Vaddeman B Beginning Apache Pig Big Data Processing Made Easy 2016 pdf pdf
Teks penuh
Gambar


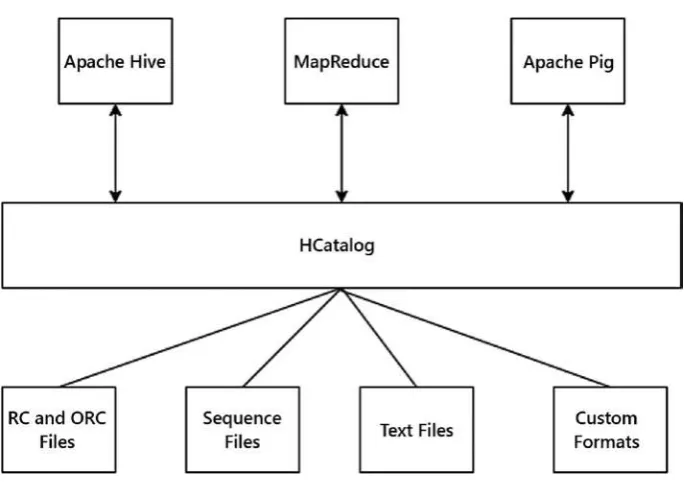
Dokumen terkait
‡ In particular, the first comma of Article 25 states that: “the controller shall, both at the time of the deter- mination of the means for processing and at the time of the
The edited book “ Big Data Processing using Spark in Cloud ” takes deep into Spark while starting with the basics of Scala and core Spark framework, and then explore Spark data
But even if you start with strat- egy, identify the metrics and data that could help you answer your SMART questions and drive your strategy, and even if you then applied analytics
applying the big data business value drivers—underleveraged transactional data, new unstructured data sources, real-time data access, and predictive analytics—against value
With traditional Hadoop, the data stored in HDFS is destroyed when you tear down your cluster; but with HDInsight and Azure Blob storage, since your data is not bound to
If your documents are relatively large, and you do not want to return all key/value information stored in a document, you can include an additional parameter in the find()
“name="information"” specifies “information” as a key, specifies the contents you input as a value , and send the Key-Value pairs to the server. $myData = $_POST[
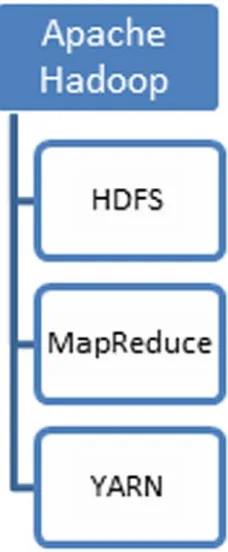
Major Course Contents: Map Reduce Computing Data Science and Models, Advanced Data Models Hadoop Internals, HDFS Application of Big Data and Predicative Analytics for large
