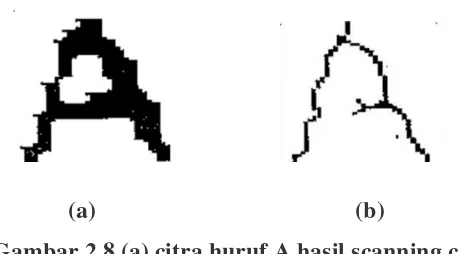BAB 2
LANDASAN TEORI
Pada bab ini akan dibahas mengenai teori pendukung dan penelitian sebelumnya yang berhubungan dengan metode ekstraksi fitur, serta metode klasifikasi Support Vector Machine dalam pengenalan citra huruf hijaiyah tulisan tangan.
2.1. Citra
Citra merupakan suatu representasi (gambaran), kemiripan, atau imitasi dari suatu objek. Citra sebagai keluaran suatu sistem perekaman data dapat bersifat optik berupa foto, bersifat analog berupa sinyal-sinyal video seperti gambar pada monitor televisi, atau bersifat digital yang dapat langsung disimpan pada suatu media penyimpan (Sutoyo et al, 2009).
Citra digital adalah larik angka-angka secara dua dimensional (Liu and Mason, 2009). Citra digital tersimpan dalam suatu bentuk larik (array) angka digital yang merupakan hasil kuantifikasi dari tingkat kecerahan masing-masing piksel penyusun citra tersebut. Citra digital dapat diklasifikasikan menjadi citra biner, citra keabuan dan citra warna.
2.1.1. Citra biner (binary image)
mempermudah proses pengenalan pola, karena pola akan lebih mudah terdeteksi pada citra yang mengandung lebih sedikit warna. Contoh citra biner dan representasi dapat dilihat pada Gambar 2.1 dan Gambar 2.2.
Gambar 2.1 citra huruf T (Sutoyo,2009) Gambar 2.2 representasi citra biner dari huruf T
(Sutoyo,2009) 2.1.2. Citra keabuan (grayscale image)
Citra keabuan yaitu citra yang pixel-nya mempresentasikan derajat keabuan atau intensitas warna putih. Citra grayscale memiliki banyak variasi nuansa abu-abu sehingga berbeda dengan citra hitam-putih seperti terlihat pada Gambar 2.3 dan 2.4. Jumlah bit yang diperlukan untuk tiap piksel menentukan jumlah tingkat keabuan yang tersedia. Tingkat keabuan yang tersedia pada citra grayscale adalah 8 atau 256.
Gambar2.3 citra hitam-putih Gambar 2.4 citra grayscale
2.1.3. Citra warna (color image)
Citra warna merupakan citra yang nilai pixel-nya mempresentasikan warna tertentu berdasarkan jumlah dari bit per-pixel citra yang bersangkutan. Setiap pixel pada citra warna mewakili warna yang merupakan kombinasi dari 3 warna (RGB = Red, Green, Blue). Setiap warna dasar menggunakan penyimpanan 8 bit = 1 byte (nilai maksimum 255 warna) sehingga satu pixel pada citra warna diwakili oleh 3 byte dengan tingkatan warna yang tersedia adalah 256. Jadi untuk tiga warna dasar pada setiap piksel memiliki kombinasi warna sebanyak 4 atau sekitar 16777216. Contoh citra warna ditunjukkan pada Gambar 2.5
Gambar2.5 citra warna (Genta,2010)
2.2. Format Citra Digital
Ada beberapa format citra digital, antara lain: BMP, PNG, JPG, GIF dan sebagainya. Masing-masing format mempunyai perbedaan satu dengan yang lain terutama pada header file. Namun ada beberapa yang mempunyai kesamaan, yaitu penggunaan palette untuk penentuan warna piksel.
2.2.1. Bitmap (.bmp)
Bitmap adalah representasi dari citra grafis yang terdiri dari susunan titik yang
tersimpan di memori komputer. Dikembangkan oleh Microsoft dan nilai setiap titik
diawali oleh satu bit data untuk gambar hitam putih, atau lebih bagi gambar berwarna.
Windows. Pada umumnya file bmp tidak di kompresi sehingga memiliki ukuran yang
sangat besar.
2.2.2 GIF
GIF adalah format gambar asli yang dikompres dengan CompuServe. Bitmap dengan
jenis ini mendukung 256 warna dan bitmap ini juga sangat popular dalam internet.
Format GIF hanya dapat menyimpan gambar dalam 8 bit dan hanya mampu
digunakan mode grayscale, bitmap, dan index color.
2.2.3 JPEG
JPEG merupakan skema kompresi file bitmap yang banyak digunakan untuk menyimpan gambar-gambar dengan ukuran lebih kecil. Format citra JPEG ini memiliki karakteristik gambar tersendiri antara lain memiliki ekstensi .jpg atau .jpeg. mampu menanyangkan warna dengan kedalaman 24-bit true color. Umumnya format citra ini digunakan untuk menyimpan gambar-gambar hasil foto.
2.3. Pengolahan Citra
Pengolahan citra merupakan proses memperbaiki kualitas citra, transformasi citra, melakukan pemilihan ciri citra untuk tujuan analisis dan mendapatkan kualitas citra yang lebih baik (Sutoyo, 2009). Tujuan dari pengolahan citra adalah bagaimana mengolah citra sebaik mungkin sehingga dapat memberikan informasi baru yang lebih bermanfaat. Beberapa teknik pengolahan citra yang digunakan adalah sebagai berikut.
2.3.1. Thresholding
Thresholding merupakan suatu proses mengubah citra berderajat keabuan menjadi citra biner atau hitam putih sehingga dapat diketahui daerah mana yang termasuk obyek dan background dari citra secara jelas (Evan, 2010).
diganti dengan 1 (putih), jika nilai piksel pada citra keabuan lebih kecil dari threshold maka nilai piksel akan diganti dengan 0 (hitam). Citra hasil thresholding dapat didefinisikan sebagaimana Persamaan 2.2.
(2.1)
Dimana : g(x,y) = piksel citra hasil binerisasi f(x,y) = piksel citra asal
T = nilai threshold
Adapun citra hasil threshoding seperti pada Gambar 2.6
(a) (b)
Gambar 2.6 (a) citra grayscale , (b) citra threshold.
2.3.2. Cropping
Gambar 2.7 proses cropping (Brigida,2010)
2.3.3. Normalisasi
Normalisasi adalah proses mengubah ukuran citra, baik menambah atau mengurangi, menjadi ukuran yang ditentukan tanpa menghilangkan informasi penting dari citra tersebut (Sharma et. al, 2012). Dengan adanya proses normalisasi maka ukuran semua citra yang akan diproses menjadi seragam.
2.3.4. Thinning
Proses thinning (penipisan) merupakan operasi pemrosesan reduksi citra biner
menjadi rangka (skeleton) yang menghampiri garis sumbu objek. Thinning bertujuan
untuk mengurangi bagian yang tidak perlu (redundant) sehingga dihasilkan informasi
yang esensial saja. Pola penipisan harus tetap mempunyai bentuk yang menyerupai
pola asalnya. Proses thinning dapat dilihat pada Gambar 2.8.
(a) (b)
Gambar 2.8 (a) citra huruf A hasil scanning citra
Citra hitam putih yang diambil sebagai masukan, akan ditipiskan terlebih dahulu.
Proses penipisan ini merupakan proses menghilangkan piksel-piksel hitam (mengubah
menjadi piksel putih) pada tepi-tepi pola. Penipisan ini dilakukan dengan mengurangi
ketebalan sebuah objek hingga ke batas minimum yang di perlukan oleh program
sehingga dapat dikenali. Citra hasil penipisan ini akan digunakan sebagai masukan
untuk dibandingkan dengan target yang telah disediakan. Citra hasil dari penipisan
biasanya disebut dengan skeleton.
2.4. Ekstraksi Fitur
Ekstraksi fitur adalah proses pengukuran terhadap data yang telah dinormalisasi untuk membentuk sebuah nilai fitur. Nilai fitur digunakan oleh pengklasifikasi untuk mengenali unit masukan dengan unit target keluaran dan memudahkan pengklasifikasian karena nilai ini mudah untuk dibedakan (Pradeep et. al, 2011). Pada penelitian ini , penulis menggunakan metode ekstraksi zoning.
2.4.1. Ekstraksi Ciri Zoning
Gambar 2.9 Pembagian zona pada citra biner (Isnan,2012)
Ada beberapa algoritme untuk metode ekstraksi ciri zoning, di antaranya metode ekstraksi ciri jarak metrik ICZ (image centroid and zone), metode ekstraksi ciri jarak metrik ZCZ (zone centroid and zone). Kedua algoritma tersebut menggunakan citra digital sebagai input dan menghasilkan fitur untuk klasifikasi dan pengenalan sebagai output-nya. Berikut merupakan tahapan dalam proses ekstraksi ciri ICZ, ZCZ .(Rajashekararadhya dan Ranjan 2008).
Algoritme 1: Image Centroid and Zone (ICZ) berdasarkan jarak metrik. Tahapan
1. Hitung centroid dari citra masukan.
2. Bagi citra masukan ke dalam n zona yang sama.
3. Hitung jarak antara centroid citra dengan masing-masing piksel yang ada dalam zona
4. Ulangi langkah ke 3 untuk setiap piksel yang ada di zona.
5. Hitung rata-rata jarak antara titik-titik tersebut.
6. Ulangi langkah-langkah tersebut untuk keseluruhan zona.
7. Hasilnya adalah n fitur yang akan digunakan dalam klasifikasi dan pengenalan .
Zona 1 (atas)
Zona 2 (tengah)
Algoritma 2: Zone Centroid Zone (ZCZ) berdasarkan jarak metrik. 1. Bagi citra masukan ke dalam sejumlah n bagian yang sama .
2. Hitung centroid dari masing-masing zona.
3. Hitung jarak antara centroid masing-masing zona dan piksel yang ada di zona.
4. Ulangi langkah ke 3 untuk seluruh piksel yang ada di zona.
5. Hitung rata-rata jarak antara titik-titik tersebut.
6. Ulangi langkah 3-7 untuk setiap zona secara berurutan.
7. Hasilnya adalah n fitur yang akan digunakan dalam klasifikasi dan pengenalan
2.5. Support Vector Machine (SVM)
Support Vector Machine (SVM) adalah suatu teknik untuk melakukan prediksi, baik
dalam kasus klasifikasi maupun regresi (Santoso, 2007). SVM berada dalam satu
kelas dengan Artificial Neural Network (ANN) dalam hal fungsi dan kondisi
permasalahan yang bisa diselesaikan. Keduanya masuk dalam kelas supervised
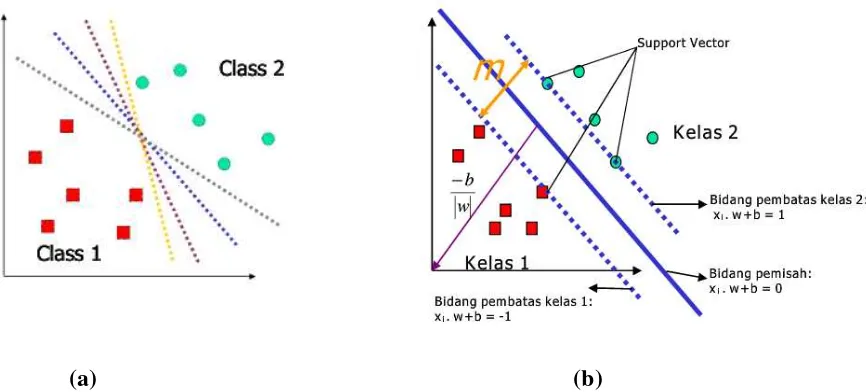
pemisah terbaik tidak hanya dapat memisahkan data tetapi juga memiliki margin paling besar.
(a) (b)
Gambar 2.10 (a) alternatif bidang pemisah (b) hyperplane terbaik dengan margin (m)
terbesar (Krisantus,2007)
Data yang berada atau terdekat pada bidang pemisah ini disebut support vector. Pada Gambar 2.7 (b) dua kelas dipisahkan oleh sepasang bidang pembatas yang sejajar. Bidang pembatas pertama membatasi kelas pertama (kotak) sedangkan bidang pembatas kedua membatasi kelas kedua (lingkaran), sehingga pattern yang termasuk kelas 1(sampel negatif) memenuhi pertidaksamaan :
. + � − (2.3)
Sedangkan pattern yang termasuk kelas 2 (sampel positif) dapat dirumuskan sebagai pattern yang memenuhi pertidaksamaan :
. + � + (2.4)
Dimana w = normal bidang (parameter bobot) x = label kelas (vektor input)
Kedua kelas dapat terpisah secara sempurna oleh bidang pemisah (classifier/Hyperplane). Hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin Hyperplane tersebut dan mencari titik maksimalnya. Margin merupakan jarak antara Hyperplane tersebut dengan pattern terdekat dari masing-masing kelas. Nilai margin (jarak) antara hyperplane (berdasarkan rumus jarak ke titik pusat adalah :
− − − −
�
=
|�| (2.5)Dengan mengalikan b dan w dengan sebuah konstanta, akan menghasilkan nilai margin yang dikalikan dengan konstanta yang sama. SVM menggunakan konsep margin yang didefinisikan sebagai jarak terdekat antara decision boundary dengan sembarang data training, dengan memaksimumkan nilai margin maka akan didapat suatu decision boundary tertentu. Margin terbesar didapat dengan memaksimalkan
nilai jarak antara hyperplane dan titik terdekatnya yaitu
|�|
.
Maka pencarianhyperplane terbaik dengan nilai margin terbesar dapat dirumuskan menjadi masalah optimasi konstrain yaitu mencari titik minimal persamaan (2.6) dengan memperhatikan constraint persamaan (2.7).
min | | (2.6)
. w + b)-1 0 (2.7)
Menggunakan metode lagrange multiplier dapat lebih mudah menyelesaikan permasalahan optimasi konstrain dalam mencari titik minimal dengan menggunakan tambahan konstrain � yang disebut sebagai lagrange multiplier dalam fungsi sebagai berikut :
(2.8)
Keterangan :
� bernilai nol atau positif ( � 0 ).
�
�
�
�(w,b,α)
= 0
∑
�=�
= 0
(2.9)dan dari
�
��
�
�(w,b,α)
= 0
w =
∑
�=�
= 0
(2.10)Vektor w sering bernilai besar hingga tak terhingga, tetapi nilai
�
terhingga.Oleh karena itu formula lagrangian Lp (prima problem) diubah kedalam dual problem �� dengan mensubstitusikan persamaan 2.10 ke Lp sehingga diperoleh dual problem �� dengan konstrain yang berbeda.
��
�
= ∑�= � -∑
�= , −� �
(2.11)
Pencarian hyperplane terbaik dapat dirumuskan sebagai berikut :
(2.12)
Dari hasil perhitungan ini diperoleh � > 0 (support vector) , data yang memiliki nilai � yang positif inilah yang berperan pada model decision boundary, sehingga kelas dari data pengujian x dapat ditentukan berdasarkan nilai dari fungsi keputusan:
f ( ) = ∑��= � + � (2.13) Dimana :
= support vector
= data yang akan diklasifikasi ns = jumlah support vector
dalam ruang ciri berdimensi lebih tinggi kemudian diterapkan klasifikasi linear dalam ruang tersebut.
2.5.1 Contoh Kasus
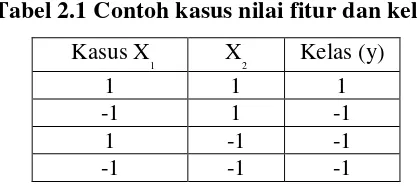
Contoh kasus pertama SVM dengan dua kelas dan empat data pada Tabel 2.1 berikut ini
merupakan problem linier yang akan ditentukan fungsi klasifikasi (hyperpalane).
Adapun formulasi masalahnya adalah sebagai berikut :
Tabel 2.1 Contoh kasus nilai fitur dan kelas
Kasus X
Langkah-langkah yang dilakukan dalam menentukan fungsi klasifikasi(hyperplane) dari contoh kasus diatas adalah :
Penentuan variabel bobot dari fitur ciri kasus.
Terdapat dua fitur ciri pada tabel 3.1 yaitu x1, x2 sehingga w (bobot) akan memiliki 2 fitur yaitu w1 dan w2 .
Optimasi masalah dengan meminimal kan nilai sebagai berikut :
min ( + + C (t1 + t2 + t3 + t4)
w1 = 1 , w2 = 1 , b = 1
Jadi persamaan fungsi pemisahnya adalah : f(x) = x1 + x2 -1
Sehingga semua nilai f(x) < 0 diberi label -1 dan f(x) > 0 diberi laber +1.
2.6. Penelitian Terdahulu
Penelitian tentang pengenalan pola telah dilakukan dengan menggunakan beberapa metode. Variasi metode ekstraksi ciri yang digunakan adalah metode yang diajukan oleh Rajashekararadhya & Ranjan (2008), yaitu Image Centroid and Zone (ICZ), Zone Centroid and Zone (ZCZ), dan gabungan ICZ dan ZCZ. Dalam penelitian ini diperoleh tingkat pengenalan rata-rata karakter angka Kannada, Telugu, Tamil, dan Malayalam yang di tulis tangan diatas 90% dengan melakukan penggabungan metode ekstraksi ciri ICZ dan ZCZ untuk klasifikasi menggunakan JST dan KNN. Tingkat pengenalan menggunakan metode zoning ini juga mencapai 87% dengan menggabungkan metode ekstraksi ciri diagonal based untuk peningkatan nilai fitur jaringan propagasi balik pada pengenalan angka tulisan tangan oleh Nanda (2012).
Support Vector Machine (SVM) merupakan metode klasifikasi yang mencari support vector terbaik yang memisahkan dua buah class dengan margin terbesar. SVM secara konseptual merupakan classifier yang bersifat linier tetapi dapat dimodifikasi dengan menggunakan kernel (fungsi yang memudahkan proses pengklasifikasian data) sehingga dapat menyelesaikan permasalahan yang bersifat tidak linier (non linier). Metode ini telah menyelesaikan kasus pengklasifikasi dan memprediksi angkutan udara jenis penerbangan internasional di Banda Aceh (Sayed,2011) dengan tingkat akurasi model hingga 84,31%.
Tabel 2.2. Penelitian terdahulu
No. Peneliti / Tahun Metode yang digunakan Akurasi
1. Rajashekararadhya & Ranjan (2008) Support Vector Machine
K-Nearet Neighbor 90%
2. Sayed (2011) Support Vector Machine 84,31%
3. Nanda (2012) Zoning dan Diagonal Based