BAB II
DASAR TEORI
Pada bab ini akan dibahas teori-teori pendukung yang digunakan sebagai acuan dalam merancang algoritma.
2.1.Deteksi Bola
2.1.1.Colorspace
Colorspace adalah model abstraksi matematis [3,4] untuk menggambarkan
representasi warna dalam angka-angka, dan biasanya terdiri dari tiga atau empat unsur warna, seperti RGB, CMYK, HSV, HSL [5], atau YUV. Masing-masing komponen dasar dalam colorspace adalah penyusun warna.
YUV colorspace mendefinisikan warna dengan menggunakan elemen luminans (Y) dan dua elemen warna komponen krominans (UV). Ini merupakan perbaikan dari informasi warna yang digunakan dalam televisi hitam putih tua yang hanya menggunakan elemen Y. Elemen Y adalah tingkat kecerahan, lalu komponen U dan V merupakan informasi warna.
Smartphone Android Sony Xperia Mini st15i membuat gambar yang diambil
oleh kamera dalam YUV420 colorspace[6]. Hal ini dapat dilihat pada Gambar 2.1 bahwa YUV420sp colorspace yang berperforma lebih baik dibandingkan RGBA colorspace. Ketika lampu intensitas berkurang, kinerja deteksi bola dari kedua
colorspace akan terdegradasi, tetapi pada RGBA colorspace ini mengurangi tingkat
akurasi warna[6].
2.1.2.Segmentasi Warna
Segmentasi warna digunakan untuk memisahkan warna bola oranye serta titik pinalti berwarna putih dengan warna lingkungan lainnya. Segmentasi dilakukan dengan mengatur batas atas dan bawah untuk nilai-nilai elemen dalam gambar. Sebagai hasil, citra biner yang terdiri dari 0 untuk hitam dan 1 untuk putih.
2.1.3.Metode Pusat Masa
2.2.Penjaga Gawang
Seorang penjaga gawang merupakan suatu hal yang utama dalam permainan sepakbola. Untuk menjadi seorang penjaga gawang (kiper), ada beberapa hal yang harus diperhatikan. Pada dasarnya seorang kiper diharuskan memiliki kemampuan dasar pengamatan terhadap bola, serta refleks yang cukup baik, selain itu ada kemampuan individual seorang kiper yang perlu diperhatikan, diantaranya[7] :
2.2.1. Daya Jangkau
Kemampuan kiper dalam menjangkau bola sangatlah penting untuk dikuasai. Kiper harus tahu dimana kemampuan menjangkau bola, sehingga dapat menentukan kapan bola akan ditangkap, ditinju, ditangkis, ataupun lompat serta kapan harus menjatuhkan diri untuk menyelamatkan gawang.
2.2.2. Penempatan Posisi
Semakin baik posisi kiper berada, semakin mudah pula kiper menghalau serangan lawan. Kiper haruslah paham dimana kedua kaki harus berpijak. Sejauh apa dari gawang, berada pada sudut berapa dan dimana kira-kira lawan membidik tendangannya. Titik ini menjadi awal pengambilan keputusan ketika kiper memutuskan untuk tetap di tempat atau maju keluar sarang untuk menggagalkan usaha penyerang lawan. Disini pula berawal pikiran untuk memutuskan untuk lompat, terbang, menangkis, menyergap.
2.2.3. Refleks
Poin penting untuk seorang kiper. Kecepatan bereaksi terhadap bola yang sering berubah arah. Karena apabila seorang kiper tidak memiliki refleks yang bagus, ia akan selalu terlambat dalam menangkis ataupun menghalau bola yang datang.
2.2.4. Konsentrasi
Seorang kiper, secara kasat mata seolah tidak selalu bekerja setiap menitnya. Ketika bola berada di area pertahanan lawan, kiper akan cenderung diam. Namun sebenarnya, ketika dalam situasi seperti ini, seorang kiper akan lebih baik jika berkonsentrasi penuh dalam permainan. Konsentrasi sejak serangan lawan belum dibangun akan lebih memudahkannya mengambil keputusan ketika serangan datang. 2.3.Format Lapangan
Gambar 2.1 Dimensi lapangan
Tabel 2.1 Keterangan dimensi lapangan
Ukuran Kecil (cm) Ukuran Besar (cm)
A Panjang lapangan 900 900
B Lebar lapangan 600 600
C Kedalaman gawang 50 60
D Lebar gawang 225 300
E Panjang Goal area 60 100
F Lebar Goal area 345 500
G Jarak titik pinalti ke gawang 180 210
H Diameter lingkar tengah lapangan 150 150
I lebar luar lapangan(min.) 70
2.4.Metode Decision Tree
Decision tree adalah salah satu metode klasifikasi yang menggunakan
Manfaat dari decision tree adalah melakukan proses pemecahan persoalan dalam pengambilan keputusan yang kompleks menjadi lebih sederhana sehingga orang yang mengambil keputusan akan lebih menginterpretasikan solusi dari permasalahan. Konsep yang digunakan oleh decision tree adalah mengubah data menjadi suatu keputusan pohon dan aturan-aturan keputusan(rule), selain itu metode ini juga digunakan untuk memilih atribut mana yang didahulukan dengan menghitung information gain dan juga untuk menyediakan struktur data pada saat pengambilan keputusan ketika robot (objek yang mendapat penerapan dari decision tree di sini adalah robot) menerima data baru seperti kamera atau sensor lainnya.
2.4.1. Entropy
Untuk mengimplementasikan pemilihan suatu atribut A dalam decision tree diperlukan informasi yang terkandung dalam suatu konteks atau permasalahan. Informasi yang terkandung di dalam suatu permasalahan tersebut dinamakan entropy. Selain itu entropy juga dapat diartikan sebagai suatu pengukuran dari jumlah ketidakpastian dalam suatu rangkaian peristiwa.
Kita asumsikan variable H adalah suatu rangkaian kejadian dan akan dihitung entropy dari kejadian tersebut sehingga suatu entropy dari H dapat dirumuskan[14]
i
i p
p H
logDan entropy dari sebuah kejadian yang menggambarkan 2 buah probabilitas yang dimisalkan dengan p dan q di mana q = 1-p adalah[14]:
H (plogpqlogq)
Sebagai contoh kasus yang pertama, jika robot mempertimbangkan untuk jatuh atau tidak, ini bisa diilustrasikan sebagai suatu bilangan biner 1(jatuh) atau 0(tidak jatuh), dan bilangan 1 atau 0 ini mencakup 1 bit entropy. Contoh lain kasus yang ke-dua, misalkan robot mempertimbangkan untuk jatuh, tidak jatuh, geser kiri, atau geser kanan. Dengan adanya 4 kemungkinan ini berarti dalam kasus ini memiliki 2 bit entropy, karena pengambilan keputusan ini mencakup 2 bit untuk mendeskripsikan satu
dari empat peluang pengambilan keputusan yang ada.
sama untuk jatuh ataupun tidak jatuh. Sehingga dari kasus ini kita membutuhkan entropy yang mendekati 0, tetapi memiliki nilai positif.
Sehingga dalam penerapannya, entropy dari suatu variable acak I dengan nilai Vi, masing-masing memiliki peluang P(Vi) dan jumlah sampel positif dimisalkan p dan jumlah sampel negatif dimisalkan dengan n di mana n = 1-p kita gunakan persamaan sebelumnya untuk menghitung entropy dari 2 buah probabilitas. Selain itu kita gunakan log berbasis 2 karena log basis 2 merupakan logaritma biner di mana kita akan merepresentasikan hasilnya dalam sebuah satuan bit. Sehingga perhitungannya dapat didefinisikan sebagai berikut: informasi yang kita dapatkan dari suatu probabilitas[11].
2.4.2. Information Gain
Suatu atribut A yang terpilih membagi suatu set E ke dalam subset-subset E1, … , Ev Sesuai nilai-nilai yang terdapat dalam atribut A, di mana A memiliki sejumlah v nilai-nilai yang berbeda. Di mana nilai-nilai yang berbeda tersebut menjadi pereduksi dari nilai informasi yang didapat (Entropy).
Pereduksi atau remainder inilah yang menjadi faktor pengurang untuk diperolehnya nilai information Gain yang akan dihitung. Di mana remainder ini dapat dirumuskan sebagai berikut:
Sehingga Information Gain (IG) atau reduksi dari suatu entropy dari suatu atribut yang diuji dapat dirumuskan sebagai berikut[12]:
) ( )
( )
(A entropy A remainder A
IG
2.5. Latar Belakang Pemilihan Metode Decision Tree
Penulis memilih decision tree ini disebabkan untuk mengantisipasi perkembangan robot, di mana robot dapat mengalami perkembangan-perkembangan kedepannya entah penambahan modul kamera, sound recognition, sensor-sensor lain, dsb sehingga membutuhkan trial and error serta penambahan data yang makin banyak. Untuk itulah penulis memilih metode decision tree dalam menyusun algoritma sebagai suatu alat bantu dalam pengambilan keputusan.
Ada dua algoritma lain yang tergolong juga ke dalam supervised learning, di mana supervised learning ini memanfaatkan data-data dari sejumlah training set. Di mana sejumlah training set didapat dari proses trial and error yang dilakukan. Dua algoritma lain tersebut akan dibandingkan sebagai pertimbangan penulis yang menjadi dasar terpilihnya decision tree sebagai alat bantu dalam pengambilan keputusan, algoritma-algoritma tersebut yaitu Naïve Bayes model, serta jaringan syaraf tiruan. Ketiga algoritma akan dibandingkan dengan menggunakan Tabel 2.2[13].
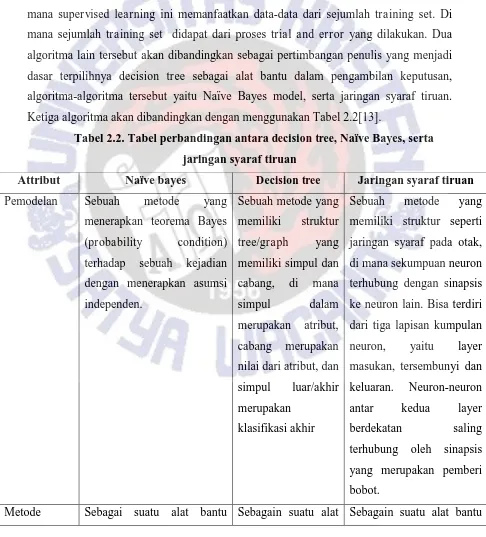
Tabel 2.2. Tabel perbandingan antara decision tree, Naïve Bayes, serta jaringan syaraf tiruan
Attribut Naïve bayes Decision tree Jaringan syaraf tiruan Pemodelan Sebuah metode yang
menerapkan teorema Bayes (probability condition) terhadap sebuah kejadian dengan menerapkan asumsi independen.
Sebuah metode yang memiliki struktur tree/graph yang memiliki simpul dan cabang, di mana simpul dalam merupakan atribut, cabang merupakan nilai dari atribut, dan simpul luar/akhir merupakan
klasifikasi akhir
Sebuah metode yang memiliki struktur seperti jaringan syaraf pada otak, di mana sekumpuan neuron terhubung dengan sinapsis ke neuron lain. Bisa terdiri dari tiga lapisan kumpulan neuron, yaitu layer masukan, tersembunyi dan keluaran. Neuron-neuron antar kedua layer berdekatan saling terhubung oleh sinapsis yang merupakan pemberi bobot.
pengambilan keputusan, naïve bayes menggunakan perhitungan teorema bayes, di mana dalam prosesnya dihitung probabilitas pada tiap kategori, lalu menentukan frekuensi kemunculan kondisi yang diinginkan pada kategori tersebut, dan pada akhirnya dilakukan pengklasifikasian untuk mendapatkan nilai maksimal dari kondisi yang diinginkan pada kategori tersebut. jaringan syaraf tiruan menggunakan model backpropagation, selama proses trial and error yang dilakukan bobot- bobot tersebut diatur sehingga nantinya akan diperoleh bobot yang baik dengan error yang sekecil mungkin dari selisih keluaran dengan target yang ingin dicapai.