Statistics authors titles recent submissions
Teks penuh
Gambar
Garis besar
Dokumen terkait
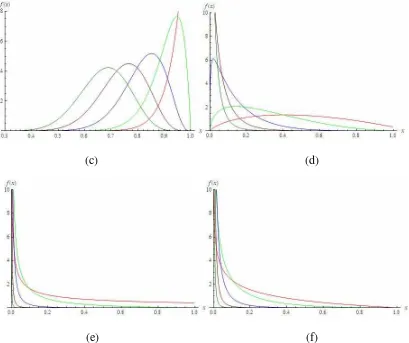
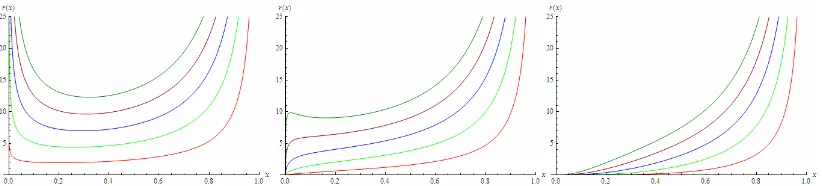
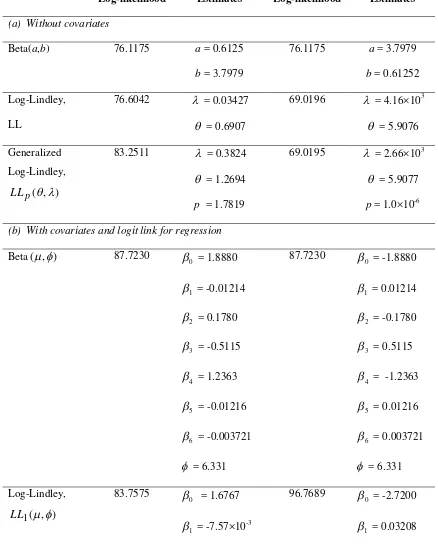
Table 2: Posterior probabilities of models and parameter estimates under the super heavy-tailed distribution assumption based on the data set without outliers.. Models
Table 1: Simulated coverage probabilities (CP) and average lengths (AL) of 95% confidence intervals from the proposed exact (EX) method, the restricted maximum likelihood (REML)
The zero-centered heavy-tailed prior distribution on w induces sparsity in the parameters vector, while the adaptive mixture model applied on the weight centers m forces a
Our approach, which we call MINT , is based on the estimation of mutual information, whose decomposition into joint and marginal entropies facilitates the use of
The second estimator relaxes the Gaussian assumption and allows both the running variable and measurement error to follow arbitrary distributions characterized by finite numbers
For community detection, the focus is on the special case where all π i are degenerate; the goal is clustering, so Hamming distance is the natural choice of loss function, and the
The better performance of moncord over space, concord and glasso is largely due to the fact that mconcord is designed for multivariate network, and treating the precision matrix
(c) Using Log-rank splitting criteria described in previous section, a node is split using the single predictor that maximizes the survival differences between daughter nodes..
