PERINGKASAN DOKUMEN BAHASA INDONESIA
MENGGUNAKAN PEMBOBOTAN FITUR KALIMAT
YOZI SUKMATUL AHDA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2015
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Peringkasan Dokumen Bahasa Indonesia Menggunakan Pembobotan Fitur Kalimat adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2015 Yozi Sukmatul Ahda G64134018
ABSTRAK
YOZI SUKMATUL AHDA. Peringkasan Dokumen Bahasa Indonesia Menggu-nakan Pembobotan Fitur Kalimat . Dibawah bimbingan JULIO ADISANTOSO. Membaca dokumen yang panjang memerlukan waktu yang lama untuk menemukan isi pen-ting dari bacaan tersebut, sehingga diperlukan suatu ringkasan untuk memudahkan dalam memahami isi dokumen. Ringkasan dokumen otomatis dapat digunakan untuk menemukan ringkasan dokumen dengan cepat. Penelitian ini menggunakan sembilan fitur kalimat untuk pembobotan kalimat sebagai penentu hasil ringkasan. Hasil ringkasan tersebut menggu-nakan CR 10%, CR 20% dan CR 30%. Untuk mengetahui keakuratan hasil ringkasan maka dilakukan evaluasi menggunakanprecision,recall,f-measuredan akurasi. Untuk hasil per-hitunganprecisiondidapatkan hasil tertinggi 60.99% pada CR 10%,recalltertinggi 41.16% pada CR 30%,f-measuretertinggi 45.42% pada CR 30%, dan hasil akurasi tertinggi 64.18% pada CR 10%.
Kata kunci: fitur kalimat, pembobotan kalimat, ringkasan dokumen
ABSTRACT
YOZI SUKMATUL AHDA. Indonesian Text Summarization by Using Weighting of Sentence Features. Supervised by JULIO ADISANTOSO.
Reading long document needs a long time to find the important contents of the reading, so summary is needed to make it easier to understand. Automatic text summarization can be used to find text summarization quickly. This research used 9 sentences features of weighting the sentences as determinant of the summary results. The result of the summary uses CR 10%, 20% and 30%. The accuracy of the summary is calculated using precision, recall, f-measure and accuracy. The highest precision results is 60.99% in CR 10%, the highest recall results is 41.16% in CR 30%, the highest f-measure results is 45.42% in CR 30% and the highest accuracy results is 64.18% in CR 10%.
PERINGKASAN DOKUMEN BAHASA INDONESIA
MENGGUNAKAN PEMBOBOTAN FITUR KALIMAT
YOZI SUKMATUL AHDA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
Penguji:
1 Irman Hermadi, SKom, MS, PhD 2 Husnul Khotimah, SKomp, MKom
Judul Skripsi : Peringkasan Dokumen Bahasa Indonesia Menggunakan Pembobotan Fitur Kalimat
Nama : Yozi Sukmatul Ahda
NIM : G64134018
Disetujui oleh
Ir Julio Adisantoso, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji syukur penulis panjatkan kehadirat Allah Subhanahu wa ta’ala yang telah mem-berikan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul “Peringkasan Dokumen Bahasa Indonesia Menggunakan Pembobotan Fi-tur Kalimat”.
Skripsi ini disusun sebagai syarat mendapat gelar Sarja Komputer (SKomp) pada Program Studi Ilmu Komputer di Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor (IPB).
Terima kasih penulis ucapkan kepada Bapak Julio Adisantoso selaku pembimbing, serta Bapak Irman Hermadi dan Ibu Husnul Khotimah yang telah banyak mem-beri saran. Ungkapan terima kasih juga penulis ucapkan kepada kedua orang tua dan seluruh keluarga, atas doa, dukungan dan kasih sayangnya, serta semua pi-hak yang telah banyak membantu dalam menyelesaikan skripsi ini. Tak lupa juga penulis ucapkan terima kasih kepada rekan-rekan satu bimbingan, Lutfia dan Rheza, atas bantuan dan kerjasamanya dalam melakukan penelitian ini, serta kepada rekan-rekan seperjuangan di Ekstensi Ilmu Komputer angkatan 8, atas dukungan, ban-tuan, dan kebersamaannya selama menjalani masa studi. Semoga skripsi ini dapat memberikan kontribusi yang bermakna bagi pengembangan wawasan para pem-baca, khususnya mahasiswa dan masyarakat pada umumnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Desember 2015
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 2 Tujuan Penelitian 2 Manfaat Penelitian 2Ruang Lingkup Penelitian 2
METODE 2 Pengumpulan Dokumen 2 Parsing Kalimat 3 Fitur Kalimat 4 Seleksi Kalimat 8 Evaluasi 9
HASIL DAN PEMBAHASAN 10
Pengumpulan Dokumen 10
Parsing Kalimat 10
Fitur Kalimat 10
Seleksi Kalimat 13
Evaluasi 13
SIMPULAN DAN SARAN 16
Simpulan 16
Saran 16
DAFTAR PUSTAKA 17
DAFTAR TABEL
1 Matrix confusion 9
2 Dokumen yang memiliki kalimat yang bernilai 0 12
DAFTAR GAMBAR
1 Tahapan proses penelitian 3
2 Pemisahan kalimat dan case folding 4
3 Filtering kata 4
4 Grafik nilai rata-rata precision 14
5 Grafik nilai rata-rata recall 15
6 Grafik nilai rata-rata f-measure 15
1
PENDAHULUAN
Latar Belakang
Membaca dokumen dengan isi yang panjang memerlukan waktu yang lama untuk menemukan intisari dari dokumen tersebut. Sehingga dibutuhkan suatu ring-kasan yang memuat intisari dari keseluruhan isi dokumen. Ringring-kasan dokumen memudahkan untuk memahami isi dokumen. Peringkasan dokumen merupakan proses mendapatkan informasi penting dari tiap-tiap subbagian dari keseluruhan dokumen. Peringkasan dokumen dapat dilakukan secara manual maupun ototis. Peringkasan dokumen yang jumlahnya banyak, apabila dilakukan secara ma-nual membutuhkan waktu yang lama dibandingkan dengan peringkasan teks secara otomatis (Aristoteleset al.2012).
Ada beberapa teknik untuk melakukan peringkasan dokumen diantaranya tek-nik ekstraksi dan tektek-nik abstraksi (Jezek dan Steiberger 2008). Tektek-nik ekstraksi yaitu menyalin semua teks tanpa mengubah kalimat teks aslinya, sedangkan tek-nik abstraksi yaitu membuat kalimat baru dari isi dokumen aslinya, namun makna kalimat tetap sama dengan teks dokumen aslinya (Jezek dan Steiberger 2008).
Peringkasan dengan teknik ekstraksi membutuhkan fitur karena fitur digu-nakan untuk merepresentasikan dokumen (Zaman dan Winarko 2011). Peringkasan dokumen otomatis dengan teknik ekstraksi telah banyak dilakukan diantaranya Fat-tah dan Ren (2008) membandingkan algoritme genetika dengan regresi matematika. Hasil penelitian Fattah dan Ren (2008) menunjukkan akurasi peringkasan teks de-ngan algoritme genetika 44.94% lebih baik dibandingkan akurasi menggunakan re-gresi matematika 43.82%. Aristoteleset al. (2012) membuat pembobotan fitur teks pada peringkasan teks bahasa Indonesia menggunakan algoritme genetika.
Pembobotan fitur teks mengindikasikan pentingnya suatu teks dalam doku-men. Pada penelitian Aristoteles et al. (2012) ada 11 fitur teks yang digunakan yaitu posisi kalimat, positive keyword, negative keyword, kemiripan antarkalimat, kalimat yang menyerupai judul dokumen, kalimat yang mengandung nama entiti, kalimat yang mengandung data numerik, panjang relatif kalimat, koneksi antar-kalimat, penjumlahan bobot koneksi antar-antar-kalimat, dan kalimat semantik. Hasil penelitian tersebut menunjukkan bahwa penggunaan 4 fitur teks dengan penamba-han kalimat semantik merepresentasikan hasil akurasi 11 fitur teks sebesar 46.44%. Selain itu, Marlina (2012) melakukan penelitian untuk menghitung pembobotan fitur teks menggunakan regresi logistik biner. Penelitian tersebut menghasilkan akurasi sebesar 42.84% padacompression rate30%.
Dokumen yang digunakan pada penelitian sebelumnya merupakan dokumen pendek seperti dokumen berita, sedangkan penggunaan dokumen panjang seperti karya ilmiah belum digunakan. Oleh karena itu, penelitian ini akan menggunakan pembobotan fitur kalimat untuk peringkasan dokumen secara ekstraksi pada doku-men skripsi berbahasa Indonesia.
2
Perumusan Masalah
Perumusan masalah dalam penelitian ini yaitu:
1 Bagaimanakah pengembangan pembobotan kalimat berdasarkan fitur kalimat untuk peringkasan dokumen otomatis?
2 Apakah pembobotan kalimat dengan fitur kalimat tersebut tepat digunakan untuk peringkasan dokumen?
3 Bagaimana implementasi dari fitur kalimat tersebut untuk dokumen skripsi berbahasa Indonesia?
Tujuan Penelitian
Penelitian ini bertujuan untuk:
1 Mengembangkan peringkasan dokumen otomatis menggunakan pembobotan kalimat berdasarkan fitur kalimat.
2 Menganalisis ketepatan penggunaan pembobotan kalimat dengan fitur kali-mat untuk peringkasan dokumen.
3 Mengimplementasikan fitur kalimat untuk dokumen skripsi berbahasa Indone-sia.
Manfaat Penelitian
Manfaat dari penelitian ini yaitu menghasilkan ringkasan yang relevan dan melakukan peringkasan dokumen secara cepat sehingga dapat digunakan oleh ma-hasiswa untuk mencari dokumen skripsi untuk dijadikan acuan penelitiannya.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah:
1 Dokumen yang digunakan yaitu skripsi Ilmu Komputer berbahasa Indonesia. 2 Menggunakan fitur kalimat untuk pembobotan kalimat dengan teknik ekstraksi.
METODE
Penelitian ini dilakukan dengan beberapa tahap yaitu pengumpulan dokumen,
parsingkalimat, hitung fitur kalimat dan pemilihan fitur kalimat, pembobotan kali-mat, seleksi kalikali-mat, dan evaluasi yang dapat dilihat pada Gambar 1.
Pengumpulan Dokumen
Penelitian ini menggunakan dokumen skripsi mahasiswa Departemen Ilmu Komputer Institut Pertanian Bogor yang berjumlah 100 dokumen yang diambil dari
3
Gambar 1 Tahapan proses penelitian
repository.ipb.ac.id. Dokumen ini digunakan untuk membandingkan ringkasan ma-nual dengan ringkasan sistem. Dokumen dikumpulkan dalam format f ile.txt dan diberikan tanda pemisah sebagai berikut:
1 {{bab-pendahuluan}} {{/bab-pendahuluan}}untuk pendahuluan. 2 {{bab-metode}} {{/bab-metode}}untuk metode.
3 {{bab-hasil}} {{/bab-hasil}}untuk hasil dan pembahasan. 4 {{bab-penutup}} {{/bab-penutup}}untuk penutup.
5 {{{subbab1}}} {{{/subbab1}}}untuk subbab.
6 {{{kesimpulan}}} {{{/kesimpulan}}}untuk kesimpulan. 7 {{{{paragraf1}}}} {{{{/paragraf1}}}}untuk paragraf.
Ada beberapa aturan yang digunakan untuk pengumpulan dokumen sebagai berikut:
1 Tabel, gambar, persamaan, algoritme beserta isinya dihapus dari dokumen. 2 Bukan berupalistpendek, kecuali pada bagian kesimpulan dan saran. 3 Tinjauan pustaka yang ada di dalam dokumen dihilangkan.
4 Judul bab dan subbab dihilangkan. 5 Catatan kaki dihilangkan.
ParsingKalimat
Dalamparsingkalimat dilakukan pemisahan kalimat,case folding, dan filter-ing kata. Dalam pemisahan kalimat memperhatikan tanda baca seperti tanda titik (.), tanda tanya (?), dan tanda seru (!). Untuk kalimat kutipan yang menggunakan tanda baca kutip dua (“ “), apabila berada sebelum tanda titik, tanda tanya, dan tanda seru, maka dianggap satu kalimat.
Tahapcase foldingmerupakan tahapan mengubah huruf dalam kalimat men-jadi huruf yang sama. Dalam penelitian ini semua huruf dalam kalimat akan diubah menjadi huruf kecil (lower case). Contoh pemisahan kalimat dancase foldingdapat dilihat pada Gambar 2.
4
Gambar 2 Pemisahan kalimat dancase folding
Tahap selanjutnya melakukan filtering kata. Dalam filtering kata dilakukan pembuangan kata-kata yang sering muncul tapi tidak punya makna yang penting, disebut juga denganstopword(Kogilavani dan Balasubramani 2010). Contoh filter-ingkata dapat dilihat pada Gambar 3.
Gambar 3Filteringkata
Fitur Kalimat
Penelitian ini mengacu pada penelitian Aristoteleset al.(2012) yang meng-gunakan fitur kalimat sebagai berikut posisi kalimat, kemiripan antarkalimat, mat yang mengandung nama entiti, kalimat yang mengandung data numerik, kali-mat yang menyerupai judul dokumen, dan panjang kalikali-mat.
Posisi Kalimat(f1)
Fitur kalimat berdasarkan posisi kalimat terdiri atas posisi kalimat dalam pen-dahuluan, posisi kalimat dalam metode, posisi kalimat dalam hasil dan pembahasan, dan posisi kalimat dalam kesimpulan.
5
Posisi Kalimat dalam Pendahuluan(f1a)
Posisi kalimat S dalam setiap subbab pada pendahuluan dapat dihitung de-ngan:
Skor f1a=
P
N (1)
dengan P adalah posisi paragraf di mana kalimat S berada, dan N adalah jumlah paragraf. Berikut ini contoh fitur kalimat berdasarkan posisi kalimat dalam pen-dahuluan.
Dewasa ini, ketersediaan data semakin melimpah, apalagi ditunjang de-ngan banyaknya kegiatan yang sudah dilakukan secara terkomputerisasi. Na-mun seringkali data tersebut hanya disimpan tanpa diolah lebih lanjut se-hingga tidak mempunyai nilai guna lebih untuk keperluan di masa mendatang.
Berdasarkan contoh tersebut diasumsikan posisi paragraf adalah paragraf per-tama dengan jumlah paragraf pada subbab perper-tama adalah 4, maka perhitungan skor fitur kalimat berdasarkan posisi kalimat dalam pendahuluan untuk seluruh kalimat pada paragraf pertama adalah 14, skor untuk seluruh kalimat pada paragraf kedua adalah 24, skor untuk seluruh kalimat pada paragraf ketiga adalah 34, dan skor untuk seluruh kalimat pada paragraf keempat adalah 44.
Posisi Kalimat dalam Metode(f1b)
Posisi kalimatSdalam setiap subbab pada metode dapat dihitung dengan:
Skor f1b= (K−(M−1))
K (2)
dengan K adalah jumlah kalimat dalam paragraf, dan M adalah posisi kalimat S
dalam paragraf. Berikut contoh fitur kalimat berdasarkan posisi kalimat dalam me-tode.
Dewasa ini, ketersediaan data semakin melimpah, apalagi ditunjang de-ngan banyaknya kegiatan yang sudah dilakukan secara terkomputerisasi. Na-mun seringkali data tersebut hanya disimpan tanpa diolah lebih lanjut se-hingga tidak mempunyai nilai guna lebih untuk keperluan di masa mendatang.
Berdasarkan contoh tersebut jumlah kalimat adalah 2, maka skor kalimat per-tama adalah 22, dan skor kalimat kedua adalah 12.
Posisi Kalimat dalam Hasil dan Pembahasan(f1c)
Posisi kalimat S dalam setiap subbab hasil dan pembahasan dapat dihitung dengan:
Skor f1c=
M
n (3)
dengan n adalah jumlah kalimat dalam paragraf, dan M adalah posisi kalimat S
dalam paragraf. Berikut contoh fitur kalimat berdasarkan posisi kalimat dalam hasil dan pembahasan.
6
Dewasa ini, ketersediaan data semakin melimpah, apalagi ditunjang de-ngan banyaknya kegiatan yang sudah dilakukan secara terkomputerisasi. Na-mun seringkali data tersebut hanya disimpan tanpa diolah lebih lanjut se-hingga tidak mempunyai nilai guna lebih untuk keperluan di masa mendatang.
Berdasarkan contoh tersebut skor kalimat pertama adalah 12, dan skor kalimat kedua adalah 22.
Posisi Kalimat dalam Kesimpulan(f1d)
Posisi kalimatSdalam kesimpulan dapat dihitung dengan:
Skor f1d= (j−(Z−1))
j (4)
denganjadalah jumlah kalimat dalam paragraf, danZadalah posisi kalimatSdalam paragraf. Berikut contoh fitur kalimat berdasarkan posisi kalimat dalam kesimpulan.
Sebagian besar aturan asosiasi memiliki nilaifuzzy confidenceyang tinggi karena nilaifuzzy supportgabunganantecedentdenganconsequentjuga tinggi. Parameter yang paling mempengaruhi jumlah aturan asosiasi yang dihasilkan adalah nilai minsup.
Berdasarkan contoh skor untuk kalimat pertama adalah 22, dan untuk kalimat kedua adalah 12.
Kemiripan Antarkalimat(f2)
Kemiripan antarkalimat merupakan kata yang muncul dalam suatu kalimat juga ada dalam kalimat yang lain. Dapat dirumuskan sebagai berikut:
Skor f2=Ks T
Ko KsSKo
(5) dengan Ks adalah kata dalam kalimat S, dan Ko adalah kata dalam kalimat lain. Berikut contoh fitur kalimat berdasarkan kemiripan antarkalimat.
1 Saya pergi ke kampus
2 Kampus saya di Baranangsiang
3 Saya terlambat mengikuti pelajaran
Berdasarkan contoh kalimat pertama memiliki 2 kata yang sama dengan kali-mat kedua dan ketiga, yaitu “saya, kampus”. Kalimat kedua memiliki 2 kata yang sama dengan kalimat pertama dan ketiga, yaitu “saya, kampus”. Sedangkan ka-limat ketiga memiliki 1 kata yang sama dengan kaka-limat pertama dan kedua, yaitu “saya”. Maka skor kalimat pertama adalah 29, skor kalimat kedua adalah29, dan skor kalimat ketiga adalah 19.
Kalimat yang Mengandung Nama Entitas(f3)
Nama entitas merupakan kumpulan kata yang memiliki makna, seperti nama institusi, nama orang, nama negara, nama daerah dan nama pulau. Dapat
dirumus-7
kan sebagai berikut:
Skor f3=
E
Ls (6)
denganE adalah jumlah entitas dalam kalimatS, danLs adalah panjang kalimat S. Berikut contoh fitur kalimat berdasarkan kalimat yang mengandung nama entitas.
DKI Jakarta sebagai ibukota negara, saat ini mengalami pembangunan yang pesat. Pembangunan ini meliputi pembangunan rumah, gedung, perkan-toran, pusat perbelanjaan, pabrik, dan lain sebagainya, sehingga membuat DKI Jakarta semakin padat.
Berdasarkan contoh kalimat yang mengandung nama entitas terdapat pada ka-limat pertama dan kedua, yaitu “DKI Jakarta” merupakan nama provinsi. Maka skor kalimat pertama adalah 17, dan skor kalimat kedua adalah 131. Dalam menghi-tung panjang kalimat, kata yang termasukstopwordtidak ikut dihitung.
Kalimat yang Mengandung Data Numerik(f4)
Kalimat yang mengandung data numerik biasanya terdapat informasi yang penting. Dapat dirumuskan sebagai berikut:
Skor f4=Nn
Ls
(7)
dengan Nn adalah jumlah data numerik dalam kalimat S, dan Ls adalah panjang kalimatS. Berikut contoh fitur kalimat berdasarkan kalimat yang mengandung data numerik.
Menurut data yang diperoleh dari Dinas Pertanian dan Kehutanan Pro-pinsi DKI Jakarta tahun 2005, tecatat bahwa di DKI Jakarta terdapat 47 area hutan yang tersebar di lima kotamadya dan masih produktif sebagai hutan kota. Keberadaan hutan kota ini jarang diketahui oleh masyarakat pada umumnya dan masyarakat Jakarta pada khususnya, sehingga pengetahuan masyarakat akan hutan kota menjadi sangat kurang.
Berdasarkan contoh kalimat pertama memiliki 2 data numerik sedangkan ka-limat kedua tidak memiliki data numerik, maka skor kaka-limat pertama adalah 232.
Kalimat yang Menyerupai Judul Dokumen(f5)
Kalimat yang menyerupai judul dokumen yaitu kata yang muncul pada ka-limat juga muncul pada judul. Untuk menghitung skor kaka-limat yang menyerupai judul dokumen digunakanCosine Similarity. Cosine Similaritymerepresentasikan kalimat dalam bentuk vektor (Xie dan Liu 2008) sebagai berikut:
Skor f5=sim(s1,s2) = ~s1·~s2 |~s1||~s2|= ∑is1,i·s2,i q ∑is21,i q ∑is22,i (8)
dengan s1 adalah kalimat S, dan s2 adalah judul dokumen. Berikut contoh fitur kalimat berdasarkan kalimat yang menyerupai judul dokumen.
8
1 Saya pergi ke kampus
2 Kampus saya di Baranangsiang
3 Saya terlambat mengikuti pelajaran
Berdasarkan contoh kata “saya” pada judul dokumen muncul pada kalimat pertama, kedua dan ketiga, sedangkan kata “terlambat” hanya muncul pada kalimat ketiga. Maka skor kalimat pertama adalah 2.451 , skor kalimat kedua adalah 2.451 , dan skor kalimat ketiga adalah 2.832 .
Panjang Kalimat(f6)
Panjang kalimat merupakan jumlah kata dalam kalimat dibagi jumlah kata unik dalam dokumen.
Skor f6= Nw
Ku (9)
denganNwadalah jumlah kata dalam kalimatS, Ku adalah jumlah kata unik dalam dokumen. Berikut contoh fitur kalimat berdasarkan panjang kalimat.
Dewasa ini, ketersediaan data semakin melimpah, apalagi ditunjang de-ngan banyaknya kegiatan yang sudah dilakukan secara terkomputerisasi. Na-mun seringkali data tersebut hanya disimpan tanpa diolah lebih lanjut se-hingga tidak mempunyai nilai guna lebih untuk keperluan di masa mendatang.
Berdasarkan contoh kata dalam kalimat pertama berjumlah 8 (tidak terma-sukstopword), asumsikan kata unik dalam dokumen berjumlah 25 kata, maka skor kalimat pertama adalah 258 , dan skor kalimat kedua adalah 258.
Seleksi Kalimat
Seleksi kalimat dilakukan setelah mendapatkan bobot kalimat. Pembobotan kalimat dihitung menggunakan persamaan regresi logistik biner. Regresi logistik merupakan metode untuk menganalisis hubungan variabel respon dan variabel pen-jelas yang memiliki dua atau lebih kategori (Hosmer dan Lemeshow 2000). Variabel respon yang digunakan terdiri atas 2 kategori yaitu 1 dan 0.
Ringkasan manual yang telah dibuat akan dibandingkan dengan dokumen untuk menentukan kalimat tersebut masuk ke dalam ringkasan atau tidak. De-ngan memberikan tanday=1 untuk kalimat yang “terambil sebagai ringkasan” dan
y=0 untuk kalimat yang “tidak terambil sebagai ringkasan”. Menurut Hosmer dan Lemeshow (2000) regresi logistik biner adalah:
g=ln( π 1−π) =a0+ n
∑
i=1 aifi (10)dengana0 adalah nilai konstanta regresi, ai adalah nilai dugaan koefisien regresi, dan fiadalah skor fitur kalimat, di manai= 1, 2,...,n. Apabilaπmerupakan peluang kalimat terambil sebagai ringkasan (y=1) dengan π >= 0.50, maka didapatkan persamaan untuk mencari peluangnya yaitu:
π= ( e g
9
Setelah mendapatkan bobot kalimat langkah selanjutnya menyeleksi kalimat untuk membuat ringkasan menggunakan rasio kompresi ringkasan (CR) 30%, 20% dan 10%.
Evaluasi
Pada tahap evaluasi, keakuratan hasil ringkasan manual akan dibandingkan dengan hasil ringkasan sistem. Untuk menghitung keakuratan tersebut digunakan perhitunganPrecision(P),Recall(R),F-Measure(F-1), dan akurasi dari dokumen.
Precision adalah proporsi kalimat yang diprediksi benar dan kenyataannya masuk kategori benar, sedangkan Recall adalah proporsi kalimat yang termasuk kategori benar dan tepat masuk dalam kategori benar tersebut (Power 2011). F-Measure
adalah gabungan dari Recall dan Precision (Zaman dan Winarko 2011). Akurasi adalah perbandingan jumlah kalimat benar dengan total kalimat keseluruhan. Da-lam memudahkan perhitungan dapat digunakan tabel pendukung (matrix confusion) seperti Tabel 1. Matrix confusion merupakan matriks yang berisi informasi peng-klasifikasian aktual dan prediksi oleh sistem (Wijakso 2012).
Tabel 1Matrix confusion
Relevant Non Relevant
Retrieved tp fp
Non Retrieved fn tn
Perhitunganprecision,recall,f-measure, dan akurasi menurut Manninget al.
(2008) berdasarkan Tabel 1 sebagai berikut:
P= tp (tp+fp) (12) R= tp (tp+fn) (13) F-1= (2×P×R) (P+R) (14) Akurasi= (tp+tn) (tp+fp+fn+tn) (15)
dengan true positive (tp) adalah kalimat yang ada dalam ringkasan manual dan muncul dalam ringkasan sistem, false positive (fp) adalah kalimat yang tidak ada dalam ringkasan manual tapi kalimat tersebut muncul dalam ringkasan sistem,false negative (fn) adalah kalimat yang ada dalam ringkasan manual tapi tidak muncul dalam ringkasan sistem, dantrue negative (tn)adalah kalimat yang tidak ada dalam ringkasan manual maupun dalam ringkasan sistem.
10
HASIL DAN PEMBAHASAN
Pengumpulan Dokumen
Dokumen yang digunakan pada penelitian ini adalah skripsi mahasiswa De-partemen Ilmu Komputer yang berjumlah 100 dokumen. Dokumen tersebut diun-duh dari repository.ipb.ac.id dalam format file.pdf. Dokumen tersebut dikonversi ke dalam bentuk file.txt, misalnya 1.txt. Rata-rata jumlah kalimat awal untuk 100 dokumen tersebut yaitu 212.06 dengan jumlah kalimat terendah yaitu 100 pada do-kumen 61.txt dan tertinggi yaitu 420 pada dodo-kumen 9.txt. Namun rata-rata kalimat menjadi 134.40 setelah dilakukan penghapusan tinjauan pustaka dan kalimat yang menjelaskan tentang gambar, grafik maupun tabel. Rata-rata perbandingan kali-mat yang terambil setelah dilakukan penghapusan sebesar 65.67% dengan rata-rata terendah adalah 35.97% pada dokumen 100.txt dan tertinggi adalah 93.22% pada dokumen 99.txt. Ukuran dokumen terendah adalah 12 KB dan terbesar 40 KB. Selanjutnya dokumen tersebut digunakan untuk membuat ringkasan manual.
ParsingKalimat
Pemisahan kalimat dilakukan berdasarkan aturan yang telah dijelaskan pada metode penelitian. Jumlah kalimat terendah yaitu 64 pada dokumen 31.txt dan ter-tinggi yaitu 308 pada dokumen 9.txt. Namun, dalam prosesnya terdapat kendala pada penggunaan tanda titik (.). Karena tanda titik (.) bukan hanya digunakan seba-gai tanda akhir kalimat, tapi digunakan juga untuk penulisan bilangan desimal atau penulisan formatfile. Sehingga, ditambhakan aturan untuk mengganti tanda titik (.) pada kasus-kasus tersebut, di antaranya:
1 Tanda titik (.) pada bilangan desimal diganti dengan tanda bintang (*). Mi-salnya 25.10 diganti menjadi 25*10.
2 Tanda titik (.) pada penulisan ”et al.” dihilangkan sehingga menjadi ”et al”. 3 Tanda titik (.) pada format file diganti menjadi tanda bintang (*). Misalnya
.txt diganti menjadi *txt.
Fitur Kalimat
Perhitungan fitur kalimat mengacu pada penelitian yang dilakukan oleh Aris-toteleset al.(2012) dengan menggunakan 9 fitur kalimat yang terdiri atas fitur kali-mat berdasarkan posisi kalikali-mat dalam pendahuluan(f1a), posisi kalimat berdasarkan metode(f1b), posisi kalimat berdasarkan hasil dan pembahasan(f1c), posisi kali-mat berdasarkan kesimpulan(f1d), kemiripan antarkalimat(f2), kalimat yang me-ngandung entitas(f3), kalimat yang mengandung data numerik(f4), kalimat yang menyerupai judul dokumen(f5), dan panjang kalimat(f6).
Posisi Kalimat dalam Pendahuluan(f1a)
Kalimat dalam pendahuluan memiliki nilai rata-rata 0.16 dengan rata-rata terendah 0.06 pada dokumen 9.txt dan tertinggi 0.27 pada dokumen 44.txt. Pada
do-11
kumen 9.txt jumlah nilai kalimat yang terambil sebagai kalimat dalam pendahuluan adalah 18.5 menghasilkan rata-rata 0.06 dengan jumlah kalimat 308. Sedangkan pada dokumen 44.txt jumlah nilai kalimatnya 20.8 menghasilkan rata-rata 0.27 de-ngan jumlah kalimat 78. Dari hasil pengamatan tersebut diperoleh bahwa jumlah kalimat yang muncul dalam paragraf akan mempengaruhi tinggi rendahnya jumlah nilai kalimat dan akan mempengaruhi nilai rata-ratanya.
Posisi Kalimat dalam Metode(f1b)
Kalimat dalam metode memiliki nilai rata-rata 0.19 dengan rata-rata terendah 0.05 pada dokumen 11.txt dan tertinggi 0.35 pada dokumen 48.txt. Ada 153 kalimat yang muncul dalam metode pada dokumen 11.txt dengan jumlah nilai kalimat 7.5 dan pada dokumen 48.txt ada 180 kalimat dengan jumlah nilai kalimat 64. Dari hasil pengamatan diperoleh bahwa jumlah nilai kalimat yang kecil akan mempengaruhi rendahnya nilai rata-ratanya apabila jumlah kalimatnya banyak.
Posisi Kalimat dalam Hasil dan Pembahasan(f1c)
Kalimat dalam hasil dan pembahasan memiliki nilai rata-rata 0.28 dengan rata-rata terendah 0.03 pada dokumen 54.txt dengan jumlah nilai kalimat 30 serta jumlah kalimat 106. Untuk rata-rata tertinggi 0.54 pada dokumen 11.txt dengan jumlah nilai kalimat 82 serta jumlah kalimat 153. Dari hasil pengamatan diperoleh bahwa jumlah nilai kalimat yang kecil akan mempengaruhi rendahnya nilai rata-rata.
Posisi Kalimat dalam Kesimpulan(f1d)
Kalimat dalam kesimpulan memiliki nilai rata-rata 0.05 dengan rata-rata teren-dah 0.02 pada dokumen 65.txt dengan jumlah kalimat 183 dan jumlah nilai kalimat 3.00. Dokumen 85.txt merupakan dokumen yang memiliki rata-rata tertinggi sebe-sar 0.20 dengan jumlah kalimat 159 dan jumlah nilai kalimat 3.17. Perbedaan jum-lah nilai antara rata-rata terendah dan tertinggi tidak terlalu signifikan disebabkan karena jumlah kalimat yang muncul antara 4 sampai 13.
Kemiripan Antarkalimat(f2)
Hasil pengamatan untuk kemiripan antarkalimat menghasilkan nilai rata-rata 0.016 dengan rata-rata terendah 0.007 pada dokumen 9.txt dan tertinggi 0.028 pada dokumen 31.txt. Ada 10 dokumen yang memiliki kalimat yang bernilai 0, hal terse-but berarti tidak ada satu kata pun yang mirip dengan kata pada kalimat lainnya. Hal ini terjadi juga karena pemisahan kalimat yang belum sempurna, seperti pada dokumen 48.txt merupakan kalimat sumber yang dijadikan rujukan. Karena kalimat sebelumnya terdapat tanda titik sehingga sistem membaca kalimat berikutnya ada-lah satu kalimat baru dan menyebabkan kalimat tersebut bernilai 0. Kalimat yang tidak memiliki kemiripan dengan kalimat lainnya dapat dilihat pada Tabel2 berikut ini:
12
Tabel 2 Dokumen yang memiliki kalimat yang bernilai 0 Dokumen Kalimat
3.txt apakahpoint, polygon, atauline
6.txt Comingtogetherisabeginning,stayingtogetherisprocessand,
workingtogetherissuccess
19.txt direktori-direktori tersebut adalah /home/ilos/.config, /home/ilos/.gconf, /home/ilos/.gconfd,
/home/ilos/.gnome2
43.txt crebrisculpta (Dharma 1988) 48.txt (marcuset al 2004)
51.txt hal ini dilakukan untuk mempermudah dalam pemrosesan selanjutnya
59.txt s-p-o-pel-k
80.txt semakin besarcoverage-nya, maka semakin besar representasi mikroorganismenya
88.txt unit-unit ini disebut sebagai token 93.txt (jain 2009)
Kalimat yang Mengandung Entitas(f3)
Kalimat yang mengandung entitas memiliki nilai rata 0.014 dengan rata-rata terendah 0.001 pada dokumen 21.txt dan 67.txt, sedangkan rata-rata-rata-rata tertinggi sebesar 0.088 pada dokumen 54.txt dengan jumlah kalimat yang mengandung en-titas sebanyak 54 kalimat. Berdasarkan hasil pengamatan nilai rata-rata dokumen tersebut merupakan nilai pencilan, apabila nilai tersebut dibuang tidak mempenga-ruhi nilai rata-rata. Selain itu banyaknya jumlah kalimat yang mengandung entitas mempengaruhi munculnya nilai pencilan tersebut.
Kalimat yang Mengandung Data Numerik(f4)
Kalimat yang mengandung data numerik memiliki rata 0.05 dengan rata-rata terendah 0.005 pada dokumen 3.txt dan 5.txt dan tertinggi 0.13 pada dokumen 40.txt. Dari hasil pengamatan walaupun dokumen 3.txt dan 5.tx merupakan nilai terendah, namun jumlah kalimat yang mengandung data numerik berbeda. Untuk dokumen 3.txt ada 8 kalimat yang mengandung data numerik sedangkan dokumen 5.txt memiliki 5 kalimat yang mengandung data numerik. Panjang kalimat dan jum-lah data numerik dalam kalimat juga mempengaruhi nilai kalimat. Pada dokumen 75.txt merupakan dokumen yang memiliki nilai tertinggi yaitu sebesar 2, karena data numerik dalam kalimat berjumlah 8 sedangkan panjang kalimat 4. Hal tersebut terjadi karena kalimat data numerik ada dalam satu kata yang dipisahkan oleh huruf yaitu: nilai hash yang didapatkan yaitu 932625cac9419081a92c4d6af3b5da44.
13
Kalimat yang Menyerupai Judul Dokumen(f5)
Dari hasil pengamatan nilai rata-rata untuk kalimat yang menyerupai judul adalah 0.26 dengan rata-rata terendah 0.01 pada dokumen 76.txt dan tertinggi 0.58 pada dokumen 97.txt. Nilai terendah 0.50 pada dokumen 99.txt dan tertinggi 1 pada 10 dokumen. Ada 48 dokumen yang memiliki rata-rata di atas 0.26. Banyaknya jumlah kata yang muncul dalam satu kalimat menghasilkan nilai kalimatnya tinggi.
Panjang Kalimat(f6)
Dari hasil pengamatan nilai rata-rata sebesar 0.06 dengan rata-rata terendah 0.03 pada dokumen 9.txt dan tertinggi 0.10 pada dokumen 64.txt. Dengan nilai rata-rata panjang kalimat terendah 0.08 pada dokumen 48.txt dan tertinggi 0.38 pada dokumen 41.txt. Walaupun jumlah panjang kalimat dalam suatu kalimat pada do-kumen yang berdeda adalah sama, apabila jumlah kata uniknya besar maka nilai kalimat kecil.
Seleksi Kalimat
Untuk menyeleksi kalimat yang terambil sebagai ringkasan menggunakan perhitungan regresi logistik biner. Nilai regresi logistik biner diperoleh dari nilai-nilai fitur kalimat. Nilai yang dihasilkan yaitu g = (-1.51672) + (-0.02115 f1a) + (0.45545 f1b) +(-0.28097 f1c) + (0.26993 f1d) + (21.71967 f2) + (1.68182 f3) + (0.97838 f4) + (1.60137 f5) + (2.39809 f6). Dari persamaan tersebut akan meng-hasilkan nilai bobot masing-masing kalimat. Bobot kalimat tersebut diurutkan dari yang terbesar dengan ketentuan bobot kalimat yang lebih besar sama dengan 0.50 akan terambil sebagai kalimat ringkasan. Bobot kalimat yang telah terurut akan diseleksi menggunakan CR 30%, 20% dan 10% untuk dijadikan ringkasan. Pada ringkasan sistem, kalimat dengan bobot di bawah 0.50 terambil sebagai ringkasan pada CR 30% karena jumlah kalimat dengan bobot lebih dari 0.50 kurang dari jum-lah kalimat yang dibutuhkan untuk dijadikan ringkasan. selain itu judul dokumen juga terambil sebagai ringkasan yang muncul pada kalimat terakhir ringkasan terse-but. Padahal di dalam penghitungan fitur kalimat, judul dokumen tidak termasuk dalam banyaknya jumlah kalimat.
Evaluasi
Proses evaluasi ini bertujuan untuk membandingkan ringkasan manual dengan hasil ringkasan sistem. Dari hasil pengamatan pada CR 10% diperoleh kalimat yang sama sebanyak 1 kalimat untuk nilai terendah yang terdapat pada dokumen 17.txt dan tertinggi pada 66.txt dengan kalimat yang sama 18 kalimat. Untuk CR 20% diperoleh kalimat yang sama sebanyak 3 kalimat untuk nilai terendah yang terda-pat pada dokumen 17.txt dan tertinggi pada dokumen 86.txt sebanyak 32 kalimat yang sama. Sedangkan untuk CR 30% diperoleh kalimat yang sama sebanyak 6 kalimat pada dokumen 17.txt dan tertinggi sebanyak 46 kalimat yang sama pada dokumen 70.txt. Untuk melakukan evaluasi digunakan perhitungan precision, re-call,f-measuredan akurasi.
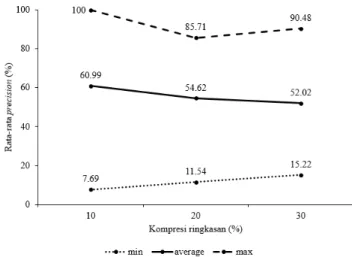
14
Evaluasi dengan menggunakanprecision dapat dilihat pada Gambar 4. Dari hasil pengamatan rata-rata perhitungan pada CR 10% yaitu sebesar 60.99% dengan nilai terendah 7.69% pada dokumen 17.txt dan tertinggi 100% pada dokumen 69.txt. Untuk CR 20% rata-rata sebesar 54.62% dengan nilai terendah 11.54% pada doku-men 17.txt dan tertinggi 85.71% pada dokudoku-men 88.txt. Sedangkan CR 30% rata-rata sebesar 52.02% dengan nilai terendah 15.22% pada dokumen 9.txt dan tertinggi 90.48% pada dokumen 88.txt. Selain itu juga menghasilkan nilai rata-ratafppada CR 10% sebesar 5.49, CR 20% sebesar 12.51 dan CR 30% sebesar 19.74. Dari hasil tersebut didapatkan bahwa semakin tinggi kompresi ringkasan maka semakin tinggi jumlah kalimat di sistem yang tidak terambil dalam ringkasan manual. Dapat disimpulkan bahwa semakin tinggi kompresi ringkasan dan nilaifpmaka semakin kecil nilaiprecisionyang dihasilkan.
Gambar 4 Grafik nilai rata-rataprecision
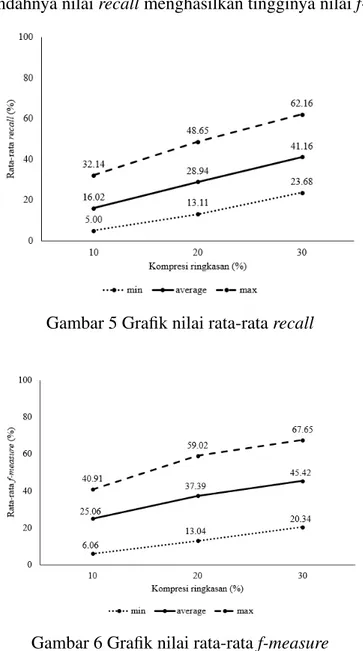
Dengan menggunakanrecalldidapatkan rata-rata perhitungan untuk CR 10% yaitu sebesar 16.02% dengan nilai terendah 5.00% pada dokumen 17.txt dan ter-tinggi 32.14% pada dokumen 19.txt, CR 20% sebesar 28.94% dengan nilai terendah 15.11% pada dokumen 51.txt dan tertinggi 48.65% pada dokumen 3.txt, sedangkan CR 30% sebesar 41.16% dengan nilai terendah 23.68% pada dokumen 14.txt dan tertinggi 62.16% pada dokumen 57.txt dapat dilihat pada Gambar 5. Dari hasil pengamatan pada CR 10% didapatkan nilai rata-rata fn sebesar 41.56, CR 20% sebesar 35.16 dan CR 30% sebesar 29.04. Hasil tersebut menunjukkan bahwa se-makin tinggi kompresi ringkasan dan nilaifnrendah maka semakin tinggi kalimat ringkasan manual yang muncul pada sistem. Hal ini terjadi karena jumlah kalimat ringkasan manual lebih banyak dibanding dengan ringkasan sistem.
Selanjutnya perhitungan dengan f-measure dengan memperhatikan nilai re-call dan precision. Pada penelitian ini nilai precision mengalami penurunan dari kompresi ringkasan CR 10% sebesar 6.37% terhadap CR 20% dan 8.97% terhadap CR 30%. Namun mengalami kenaikan sebesar 12% terhadap CR 20% dan 25.16% terhadap CR 30% pada nilairecall. Dihasilkan nilai rata-rata perhitungan untuk CR 10% yaitu sebesar 25.06% dengan nilai terendah 6.06% pada dokumen 17.txt dan tertinggi 40.91% pada dokumen 60.txt. Untuk CR 20% sebesar 37.39% dengan
ni-15
lai terendah 13.04% pada dokumen 17.txt dan tertinggi 59.02% pada dokumen 3.txt. Sedangkan CR 30% sebesar 45.42% dengan nilai terendah 20.34% pada dokumen 17.txt dan tertinggi 67.65% pada dokumen 57.txt yang dapat dilihat pada Gambar 6. Sehingga dapat disimpulkan bahwa tingginya kompresi ringkasan, tingginya nilai
precisiondan rendahnya nilairecallmenghasilkan tingginya nilaif-measure.
Gambar 5 Grafik nilai rata-ratarecall
Gambar 6 Grafik nilai rata-rataf-measure
Selain itu untuk perhitungan akurasi didapatkan hasil rata-rata untuk CR 10% yaitu sebesar 64.18% dengan nilai terendah 50.60% pada dokumen 73.txt dan ter-tinggi 87.01% pada dokumen 9.txt, CR 20% sebesar 63.93% dengan nilai terendah 47.06% pada dokumen 51.txt dan tertinggi 78.99% pada dokumen 3.txt, dan CR 30% sebesar 63.32% dengan nilai terendah 50% pada dokumen 5.txt serta 51.txt dan tertinggi 78.64% pada dokumen 57.txt dapat dilihat pada Gambar 7. Hasil tersebut menunjukkan bahwa akurasi tertinggi didapatkan pada CR 10%, hal ini terjadi karena semakin sedikit hasil ringkasan maka peluang kalimat terambil se-bagai ringkasan semakin tinggi. Dari hasil pengamatan pada CR 10% hanya ada 37% dokumen yang akurasinya tinggi dibanding dengan akurasi pada CR 20% dan
CR 30%. Tidak dapat disimpulkan bahwa ringkasan tidak cukup baik, karena 63% dokumen yang bernilai rendah memiliki nilai akurasi di atas 50%. Hal ini berarti bahwa 63% dokumen lainnya sudah dapat merepresentasikan isi dokumen.
Gambar 7 Grafik nilai rata-rata akurasi
SIMPULAN DAN SARAN
Simpulan
Pembobotan kalimat menggunakan pembobotan fitur kalimat menghasilkan nilai rata-rata tertinggi untukprecisionpada CR 10% sebesar 60.99%, recall pada CR 30% sebesar 41.16%, f-measure pada CR 30% sebesar 45.42%, dan akurasi pada CR 10% sebesar 64.18%. Berdasarkan hasil tersebut dapat disimpulkan bahwa hasil peringkasan dokumen menggunakan pembobotan fitur kalimat menunjukkan nilai akurasi yang cukup baik untuk dokumen yang panjang seperti skripsi karena untuk membuat ringkasannya tidak mudah dan memerlukan waktu untuk mema-haminya.
Saran
Pada penelitian selanjutnya disarankan untuk menambahkan aturan pemba-caan tanda titik (.) pada kalimat yang mengandung sumber rujukan agar kalimat sesudah tanda titik (.) tersebut tidak dibaca sebagai kalimat baru, serta menam-bahkan aturan pembacaan kalimat yang setelah tanda titik(.) tidak ada spasi padahal kalimat tersebut merupakan kalimat baru.
17
DAFTAR PUSTAKA
Aristoteles, Herdiyeni Y, Ridha A, Adisantoso J. 2012. Text feature weighting for summarization of documents in bahasa Indonesia using Genetic Algorithm. IJCSI. 9(1): 1–6.
Fattah MA, Ren F. 2008. Automatic text summarization. International Journal of Computer, Electrical, Automation, Control and Information Engineering. 2(1): 90-93.
Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression. Ed ke-2. Canada (CA): A Wiley-Interscience Publ.
Jezek K, Steiberger J. 2008. Automatic text summarization (the state of the art 2007 and new challenges). Di dalam: Znalosti 2008; Bratislave, 13-15 Feb 2008. hlm 1-12.
Kogilavani A, Balasubramani P. 2010. Clustering and feature specific sentence extraction based summarization of multiple documents. IJCSIT. 2(4): 99–111. Manning CD, Raghavan P, Schutze H. 2008. Introduction to Information Retrieval.
Cambridge (GB): Cambridge University Press.
Marlina M. 2012. Sistem peringkasan dokumen berita bahasa Indonesia menggunakan metode Regresi Logistik Biner [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Power DMW. 2011. Evaluation: from precision, recall and f-Measure to ROC, informedness, markedness & correlation. Journal of Machine Learning Technologies. 2(1): 37–63.
Turney PD, Pantel P. 2010. From frequency to meaning: Vector Space Models of Semantics. Journal of Artificial Intelligence Research. 37(5): 141–188.
Wijakso B. 2012. Klasifikasi jurnal ilmiah berbahasa Inggris berdasarkan abstrak menggunakan Algoritma ID3 [skripsi]. Malang (ID): Universitas Brawijaya. Xie S, Liu Y. 2008. Using corpus and knowledge based Similarity Measure
in Maximum Marginal Relevance for meeting summarization. ICASSP. 4985–4988.
Zaman B, Winarko E. 2011. Analisa fitur kalimat untuk peringkas teks otomatis pada bahasa Indonesia. IJCCS. 5(2): 60–68.
18
RIWAYAT HIDUP
Penulis dilahirkan di Panyakalan pada tanggal 11 November 1988 dari ayah Syafrizal dan ibu Roslidawati. Penulis adalah anak kedua dari empat bersaudara. Tahun 2007 penulis lulus SMA Negeri 1 Solok dan pada tahun yang sama penulis lulus seleksi masuk Politeknik Universitas Andalas, Jurusan Teknologi Informasi, Program Studi Manajemen Informatika. Tahun 2013 penulis melanjutkan pen-didikan tingkat sarjana pada program Ekstensi Departemen Ilmu Komputer IPB angkatan ke-8.