isprs archives XLI B2 269 2016
Teks penuh
Gambar


Garis besar
Dokumen terkait
The results of the research showed that (1) false colour images have a slightly higher percentage of successful interpretation than natural colour images, (2)
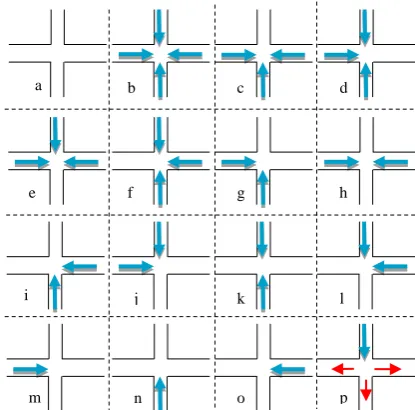
The most commonly used application for String Edit Distance in cartographic studies is eyePatterns (West et al., 2006) that output is hierarchical clustering and a tree graph
Topic modelling, a machine learning method that enables us to understand the topics in large text corpora by means of drawing probabilistic distribution over topics and
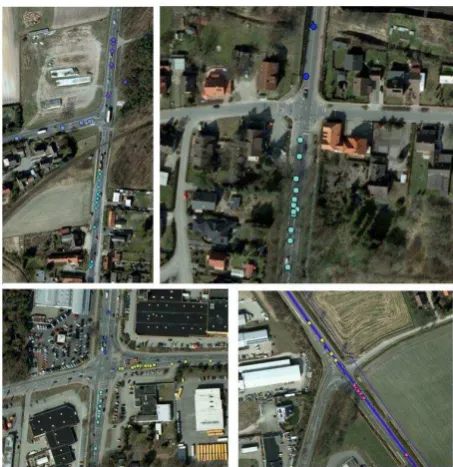
The initial results indicate that data collected using fitness tracking apps such as Strava are a promising data source for traffic managers.. Future work will incorporate
In this specific case, possible solutions could be (I) the structuring of a multiscale model that uses objects with different LoDs according to different scales of
This study suggested that the SRTM1 , a 30 m mesh open data, can be used to illustrate topographical features, such as surface ruptures or the deformations
techniques for studying rainfall gauges optimal deployment in plain regions with 25,000 km 2 (Shaghaghian and Abedini, 2013) ; Anil Kumar Kar proposed that using
The methodology presented here is useful for situations where massive sensor data need to be compressed in a way that allows a progressive retrieval with increasing
