KAJIAN TENTANG
PENDEKATAN DISTRIBUSI BINOMIAL OLEH DISTRIBUSI NORMAL
SKRIPSI
RIDWAN NASUTION 060823034
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
KAJIAN TENTANG
PENDEKATAN DISTRIBUSI BINOMIAL OLEH DISTRIBUSI NORMAL
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
RIDWAN NASUTION 060823034
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul
:
KAJIAN
TENTANG
PENDEKATAN
DISTRIBUSI
BINOMIAL OLEH DISTRIBUSI NORMAL
Kategori
: SKRIPSI
Nama
: RIDWAN NASUTION
Nim
: 060823034
Program Studi
: SARJANA (S-1) MATEMATIKA
Departemen
: MATEMATIKA
Fakultas
: MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA
UTARA
Diluluskan di
Medan, Juli 2010
Komisi Pembimbing
:
Pembimbing 2
Pembimbing 1
Drs. Suwarno Ariswoyo, M.Si
Dra. Rahmawati Pane, M.Si
NIP : 19500321 198003 1 001
NIP : 19560219 198503 2 001
Diketahui / Disetujui oleh
Departemen Matematika FMIPA USU
Ketua
Dr. Saib Suwilo, M.Sc
PERNYATAAN
KAJIAN TENTANG
PENDEKATAN DISTRIBUSI BINOMIAL OLEH DISTRIBUSI
NORMAL
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juli 2010
PENGHARGAAN
Puji syukur penulis panjatkan kepada Allah SWT dengan limpahan dan karunia-Nya sehingga skripsi ini dapat diselesaikan.
ABSTRAK
Proses Bernoulli adalah suatu proses yang berlangsung n kali dan tiap eksperimen
berlangsung dalam cara dan kondisi yang sama. Untuk setiap eksperimen hanya ada 2
(dua) kejadian yang mungkin yang mana kejadian itu saling asing dan juga
independent satu sama lain, yang biasa dinotasikan dengan kejadian sukses dan gagal.
Jika nilai n cukup besar, proses Bernoulli akan mendekati distribusi normal , dengan
menggunakan rumus :
σ µ
− = X
Z =
npq np X −
Dengan menggunakan pendekatan distribusi binomial oleh distribusi normal
diharapkan bisa lebih praktis dan lebih efisien. Disamping itu rumus distribusi normal
terkadang lebih praktis digunakan pada penjumlahan yang rumit, tentu saja dengan
simpangan yang relatif kecil. Diharapkan untuk masalah distribusi binomial bisa
diatasi dengan menggunakan pendekatan normal, dan hasil yang diperoleh tidak jauh
berbeda dengan distribusi aslinya. Atau dengan kata lain simpangan yang diakibatkan
ABSTRAC
Bernoulli process is a process that took place n times and each experiment took place
in the same manner and condition. For each experiment there were only two (two)
events where the incident may be foreign to each other and also independent of each
other, which is usually denoted with the incidence of success and failure. If the value
of n is large enough, the Bernoulli process approaches a normal distribution, using the
formula:
σ µ
− = X
Z =
npq np X −
By using the binomial distribution approaches the normal distribution is expected to
be more practical and more efficient. Besides the normal distribution formula is
sometimes more practical to use the sum of the complex, of course with a relatively
small deviation. Expected for the binomial distribution problem can be solved using
the normal approximation, and the results obtained are not much different from the
original distribution. Or in other words, the deflection caused by the normal approach
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan iv
Abstrak v
Abstrac vi
Daftar Isi vii
Daftar Tabel ix
Daftar Gambar x
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Permasalahan 3
1.3 Tujuan Penelitian 3
1.4 Manfaat penelitian 3
BAB 2 LANDASAN TEORI 4
2.1 Probabilitas 4
2.2 Operasi-Operasi dalam Kejadian 7
2.2.1 Gabungan (Union) 7
2.2.2 Irisan (Intersection) 8
2.2.3 Komplemen (Complement) 8
2.2.4 Selisih 9
2.2.5 Kejadian Majemuk 9
2.3 Probabilitas Bersyarat 10
2.4 Titik Sampel 11
2.4.1 Kombinasi (Combination) 11
2.4.2 Permutasi (Permutation) 12
2.5 Distribusi Probabilitas Diskrit 13
2.5.1 Distribusi Seragam 13
2.5.2 Distribusi Binomial 14
2.5.3 Nilai Harapan Distribusi Binomial 15
2.5.4 Variansi Distribusi Binomial 16
2.6 Distribusi Normal 17
2.6.1 Nilai Harapan Variabel Acak Normal 18
2.6.2 Variansi Variabel Acak Normal 20
2.6.4 Sifat-Sifat Normal Standard 22 2.7 Menghampiri Distribusi Binomial dengan Distribusi Normal 24
BAB 3 PEMBAHASAN 26
3.1 Pendekatan Distribusi Binomial dengan menggunakan
Distribusi Normal 26
3.2 Sifat Distribusi Binomial 27
3.3 Teorema-Teorema Pendukung 29
3.3.1 Teorema Limit Pusat ( Central Limit Theorem) 29
3.3.2 Teorema De Moivre-Laplace 30
3.4 Teknik Perhitungan Pendekatan Distribusi Binomial oleh
Distribusi Normal 31
3.5 Contoh Kasus 33
3.6 Simpangan Akibat Pendekatan 36
BAB 4 KESIMPULAN DAN SARAN 38
4.1 Kesimpulan 38
4.2 Saran 39
DAFTAR PUSTAKA 40
DAFTAR TABEL
Halaman
Tabel 2.1 Percobaan dan Hasil 5
Tabel 2.2 Urutan Percobaan, Hasil dan Peristiwa 6
DAFTAR GAMBAR
Halaman
Gambar 2.1 Gabungan 7
Gambar 2.2 Irisan 8
Gambar 2.3 Komplemen 8
Gambar 2.4 Selisih 9
Gambar 2.5 Distribusi Seragam 14
Gambar 2.6 Kurva Normal 17
ABSTRAK
Proses Bernoulli adalah suatu proses yang berlangsung n kali dan tiap eksperimen
berlangsung dalam cara dan kondisi yang sama. Untuk setiap eksperimen hanya ada 2
(dua) kejadian yang mungkin yang mana kejadian itu saling asing dan juga
independent satu sama lain, yang biasa dinotasikan dengan kejadian sukses dan gagal.
Jika nilai n cukup besar, proses Bernoulli akan mendekati distribusi normal , dengan
menggunakan rumus :
σ µ
− = X
Z =
npq np X −
Dengan menggunakan pendekatan distribusi binomial oleh distribusi normal
diharapkan bisa lebih praktis dan lebih efisien. Disamping itu rumus distribusi normal
terkadang lebih praktis digunakan pada penjumlahan yang rumit, tentu saja dengan
simpangan yang relatif kecil. Diharapkan untuk masalah distribusi binomial bisa
diatasi dengan menggunakan pendekatan normal, dan hasil yang diperoleh tidak jauh
berbeda dengan distribusi aslinya. Atau dengan kata lain simpangan yang diakibatkan
ABSTRAC
Bernoulli process is a process that took place n times and each experiment took place
in the same manner and condition. For each experiment there were only two (two)
events where the incident may be foreign to each other and also independent of each
other, which is usually denoted with the incidence of success and failure. If the value
of n is large enough, the Bernoulli process approaches a normal distribution, using the
formula:
σ µ
− = X
Z =
npq np X −
By using the binomial distribution approaches the normal distribution is expected to
be more practical and more efficient. Besides the normal distribution formula is
sometimes more practical to use the sum of the complex, of course with a relatively
small deviation. Expected for the binomial distribution problem can be solved using
the normal approximation, and the results obtained are not much different from the
original distribution. Or in other words, the deflection caused by the normal approach
BAB 1
PENDAHULUAN
1.1Latar Belakang
Salah satu jenis distribusi variabel random diskrit yang paling sederhana adalah
distribusi binomial. Distribusi Binomial adalah distribusi untuk proses Bernoulli. Distribusi ini dikemukakan pertama kali oleh seorang ahli matematika bangsa Swiss
yang bernama J. Bernoulli (1654-1705). Proses Bernoulli adalah suatu proses dengan
ciri-ciri eksperimen berlangsung n kali dan tiap eksperimen berlangsung dalam cara
dan kondisi yang sama. Untuk setiap eksperimen hanya ada 2 (dua) kejadian yang
mungkin terjadi, dimana 2 (dua) kejadian tersebut adalah saling asing dan juga
independen satu sama lain. Biasanya 2 (dua) kejadian tersebut dinotasikan sebagai
kejadian sukses dan kejadian gagal. Probabilitas sukses dilambangkan dengan p, sedangkan probabilitas gagal dilambangkan dengan q, dan p+q=1. Dari proses tersebut, yang kita definisikan sebagai variabel adalah munculnya kejadian sukses,
yang dilambangkan dengan x.
Jika n cukup besar ( n 30 ) dan nilai dari np 5 dan n(1 - p) 5, maka kita
bisa menggunakan distribusi normal untuk mendekati distribusi binomial. Distribusi binomial mempunyai nilai rata-rata = np dan nilai simpangan baku = npq. Ini diperoleh dari variabel rendom diskrit, dimana nilai dari rata-rata dicari dengan
rumus:
) ( )
(
1
X P X X
E
n
i i
=
=
E(X) = Nilai harapan X atau rata-rata X
X = Kejadian X
P(X) = Peluang kejadian X
Dan nilai varians di cari dengan rumus:
[
( )]
. ( )) (
1
2
X P X E X X
V
n
i i
=
− =
Dengan :
V(X) = Varians X
X = Kejadian X
E(X) = Nilai harapan X atau rata-rata X
P(X) = Peluang kejadian X
Distribusi normal, disebut pula distribusi Gauss, adalah distribusi probabilitas
yang paling banyak digunakan dalam berbagai analisis statistika. Distribusi normal
baku atau disebut juga distribusi Z adalah distribusi normal yang memiliki rata-rata
nol dan simpangan baku satu. Distribusi ini juga dijuluki kurva lonceng (bell curve) karena grafik fungsi kepekatan probabilitasnya mirip dengan bentuk lonceng. Secara
umum suatu distribusi normal dapat mempunyai sembarang nilai tengah , dan
sembarang simpangan baku .
Rumus distribusi normal standard :
σ µ
− = X
Z
Dengan :
Z = normal standard
X = variabel random
= rata - rata
Distribusi normal banyak digunakan dalam berbagai bidang statistik, misalnya
distribusi sampling rata-rata akan mendekati normal, meski distribusi populasi yang
diambil tidak berdistribusi normal dan kebanyakan pengujian hipotesis
mengasumsikan normalitas suatu data.
1.2 Permasalahan
Masalah yang dihadapi dalam penelitian ini adalah bagaimana proses pelaksanaan
pendekatan distribusi binomial oleh distribusi normal, dan sejauh mana simpangan
yang ditimbulkan akibat dari dilakukannya pendekatan oleh distribusi normal, jika
dibandingkan dengan hasil perhitungan dari distribusi aslinya (distribusi binomial).
1.3 Tujuan Penelitian
Tujuan penelitian ini adalah untuk mengetahui proses pendekatan distribusi binomial
oleh distribusi normal dan untuk mengetahui penyimpangan yang diakibatkan dari
pendekatan distribusi binomial oleh distribusi normal.
1.4 Manfaat Penelitian
Suatu percobaan sering terdiri atas beberapa usaha, tiap usaha dengan dua
kemungkinan hasil yang dapat diberi nama sukses dan gagal. Bila percobaan
dilakukan n kali dengan n ∞ maka akan sedikit sulit menghitungnya dengan
distribusi binomial, bentuk distribusi normal akan membantu dalam analisis yang
BAB 2
LANDASAN TEORI
2.1 Probabilitas
Probabilitas adalah suatu nilai untuk mengukur tingkat kemungkinan terjadinya suatu
peristiwa (event) akan terjadi di masa mendatang yang hasilnya tidak pasti (uncertain event). Probabilitas dinyatakan antara 0 (nol) sampai 1 (satu) atau dalam persentase. Probabilitas 0 menunjukkan peristiwa yang tidak mungkin terjadi, sedangkan
probabilitas 1 menunjukkan peristiwa yang pasti terjadi. P(A) = 0,99 artinya
probabilitas bahwa kejadian A akan terjadi sebesar 99 % dan probabilitas A tidak
terjadi adalah sebesar 1%.
Ada tiga hal penting dalam rangka membicarakan probabilitas, yaitu
percobaan (experiment), ruang sampel (sample space) dan kejadian (event).
Percobaan (experiment) adalah pengamatan terhadap beberapa aktivitas atau proses yang memungkinkan timbulnya paling sedikit 2 (dua) peristiwa tanpa
memperhatikan peristiwa mana yang akan terjadi.
Contoh :
Kegiatan melempar mata uang akan menghasilkan peristiwa muncul gambar atau
angka, kegiatan jual beli saham akan menghasilkan peristiwa membeli atau menjual,
perubahan harga-harga akan menghasilkan peristiwa inflasi atau deflasi, pertandingan
sepak bola akan menghasilkan peristiwa menang, kalah atau seri. Kegiatan-kegiatan
Ruang sampel (sample space) atau semesta (universe) merupakan himpunan dari semua hasil (outcome) yang mungkin dari suatu percobaan (experiment). Jadi ruang sampel adalah seluruh kemungkinan peristiwa yang akan terjadi akibat adanya
suatu percobaan atau kegiatan.
Contoh :
Dari kegiatan diatas dapat diperoleh hasil sebagai berikut :
Tabel 2.1 Percobaan dan Hasil
Percobaan Ruang Sampel
Melempar Mata Uang
{ Gambar , Angka }
Perdagangan Saham
{ Menjual, Membeli )
Perubahan harga
{ Inflasi, Deflasi }
Pertandingan Sepak Bola
{ Menang, Kalah, Seri}
Kejadian (event) adalah kumpulan dari satu atau lebih hasil yang terjadi pada
sebuah percobaan atau kegiatan. Kejadian menunjukkan hasil yang terjadi dari suatu
percobaan. Dalam setiap percobaan atau kegiatan hanya ada satu hasil. Pada kegiatan
jual beli saham, kalau tidak membeli berarti menjual. Pada perubahan harga terjadi
inflasi atau deflasi. Dua peristiwa tersebut tidak dapat terjadi bersamaan. Pada
pertandingan sepak bola juga hanya terjadi satu peristiwa, apakah klub sepak bola
tersebut menang, kalah atau seri. Tidak mungkin dalam suatu pertandingan sepak
bola, misalnya Persipura dan PSM, hasilnya adalah Persipura menang juga kalah.
Peristiwa yang mungkin adalah Persipura menang, Persipura kalah, atau seri. Urutan
Tabel 2.2 Urutan Percobaan, Hasil dan Peristiwa
Percobaan / Kegiatan Pertandingan sepak bola antara Persipura VS PSM di Stadion Mandala, Jayapura, 27 Februari 2010
Ruang Sampel
Persipura Menang
Persipura Kalah
Seri, Persipura tidak kalah dan menang
Kejadian / Peristiwa Persipura Menang
Nilai probabilitas dapat dihitung berdasarkan nilai hasil observasi (sifatnya
subyektif) atau berdasarkan pertimbangan pembuat keputusan atau tenaga ahli dalam
bidangnya secara subyektif.
Besarnya nilai kemungkinan bagi munculnya suatu kejadian adalah selalu
diantaa 0 (nol) dan 1 (satu). Pernyataan ini dapat ditulis sebagai 0≤ P(A)≤1, dimana P(A) menyatakan nilai kemungkinan bagi munculnya kejadian A. Jika suatu
percobaan dapat menghasilkan N macam hasil yang berkemungkinan sama (equally likely) dan jika tepat terdapat sebanyak n hasil yang berkaitan dengan kejadian A, makaprobabilitas kejadian A adalah :
N n A P( )=
Contoh:
Didalam kegiatan pengendalian mutu produk, ada 100 buah barang yang diperiksa,
ternyata ada 12 buah barang yang cacat atau rusak. Kalau kebetulan diambil secara
acak satu saja, berapa probabilitasnya bahwa barang yang diambil adalah barang yang
rusak.
Dari soal diketahui bahwa: N = 100 buah barang
n = 12 buah barang yang rusak
A = barang yang diambil secara acak
Jadi, probabilitas memperoleh barang yang rusak adalah :
12 , 0 100
12 )
(A = =
P
Jika n = 0, berarti tidak ada barang yang rusak, ( )= 0 =0
N A
P , kejadian ini disebut impossible event (tidak mungkin terjadi). Tetapi jika n = N = 100, berarti
semua barang rusak, 1
100 100 )
(A = =
P , kejadian ini disebut sure event (pasti terjadi).
2.2 Operasi-Operasi dalam Kejadian
Ada beberapa operasi-operasi dalam kejadian yaitu: gabungan (union), irisan (intersection), komplemen (complement), selisih dan kejadian majemuk
2.2.1 Gabungan (Union)
Gabungan dua kejadian Adan B, dinyatakan dengan A∪B, merupakan kejadian yang mengandung semua elemen yangtermasuk Aatau Batau keduanya.
B
A∪ = {x : x ∈ A atau x ∈ B}
Jika digambarkan pada diagram Venn maka daerah yang diarsir merupakan
himpunan A∪B.
Gambar 2.1 Gabungan
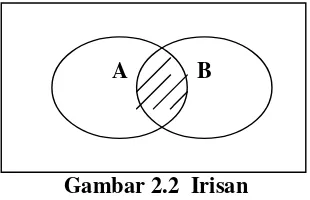
2.2.2 Irisan (Intersection)
Irisan dua kejadian A dan B, dinyatakan dengan A ∩ B, merupakan kejadian yang
elemen-elemennya merupakan anggota dari A dan B.
= ∩B
A {x : x∈A dan x∈B}
Jika digambarkan pada diagram Venn maka daerah yang diarsir merupakan
himpunan A∩B.
Gambar 2.2 Irisan
2.2.3 Komplemen (Complament)
Komplemen dari kejadian A, dinyatakan dengan Ac, adalah kejadian dari
elemen-elemen yang merupakan anggota semesta tetapi bukan anggota A.
{
x x S x A}
Ac = : ∈ , ∉
Jika digambarkan pada diagram Venn maka daerah yang diarsir merupakan
himpunan Ac.
Gambar 2.3 Komplemen
A B
2.2.4 Selisih
Selisih kejadian B dari kejadian A dinyatakan dengan A – B adalah kejadian dari
elemen-elemen yang merupakan anggota dari A tetapi bukan anggota dari B.
{
x x A x B}
B
A− = : ∈ , ∉
Jika digambarkan pada diagram Venn maka daerah yang diarsir merupakan himpunan
A - B.
Gambar 2.4 selisih
2.2.5 Kejadian Majemuk
1. Bila A and B mutually exclusive (kejadian yang terpisah), maka : P(A∪B)=P(A)+P(B)
2. Bila A dan B dua kejadian sembarang, maka :
P(A∪B)=P(A)+P(B)−P(A∩B)
3. Bila ada K kejadian yaitu A1, A2, …, Ai, …, Ak yang mutually exclusive dan
membentuk kejadian A, maka:
P(A)=P(A1∪A2∪...∪Ai ∪...∪Ak) ( ) ( )
1 =
=
k
i i
A P A
P
P(A)=1
4. Bila A dan B independent (bebas), maka : P(A∩B)=P(A)P(B)
5. Bila A dan B dependent (tidak bebas), maka : P(A∩B)=P(A)P(B| A)
P(A∩B)=P(B)P(A|B), dimana P(A)≠0,P(B)≠0.
2.3 Probabilitas Bersyarat
Peluang terjadinya suatu kejadian A bila diketahui bahwa kejadian B telah terjadi
disebut peluang bersyarat dan dinyatakan dengan P(A|B).
) ( ) ( ) | ( B P B A P B A
P = ∩
Sama halnya dengan peluang terjadinya suatu kejadian B bila diketaui bahwa
kejadian A telah terjadi dan dinyatakan dengan P(B|A).
) ( ) ( ) | ( A P B A P A B
P = ∩
Dengan mengkombinasikan kedua persamaan maka diperoleh :
) ( ) | ( ) ( ) ( ) |
(A B P B P A B P B A P A
P = ∩ =
) ( ) ( ) | ( ) ( ) ( ) | ( B P A P A B P B P B A P B A
P = ∩ =
Contoh:
Dari 900 nama, terdapat 500 orang pria dengan status 460 orang bekerja, sedangkan
40 orang lagi tidak bekerja, dan 400 orang wanita dengan status 140 orang bekerja
sedangkan 260 orang lagi tidak bekerja. Berapa probabilitas terpilihnya pria dengan
A = pria terpilih
B = orang yang terpilih berstatus bekerja
3 2 900 600 )
(B = =
P
45 23 900 460 )
(B∩A = =
P
30 23
3 2
45 23 ) |
(A B = =
P
Dari perhitungan diatas maka diperoleh kemungkinan bahwa nama yang
terpilih adalah pria dengan status bekerja adalah sebesar 0,77 atau 77%.
2.4 Titik Sampel
Titik sampel (sample point) merupakan tiap anggota atau elemen dari ruang sampel. Jika suatu operasi dapat dilakukan dengan n1 cara, dan bila untuk setiap cara ini operasi kedua dapat dilakukan dengan n2 cara, dan bila untuk setiap cara ini operasi ketiga dapat dilakukan dengan n3 cara, dst, maka deretan k operasi dapat dilakukan dengan n1n2...nk cara.
Contoh:
Tiga buah koin (uang logam) dilemparkan sekali. Banyaknya titik sampel dalam ruang
sampel ?
Koin I dapat menghasilkan 2 hasil yang mungkin, muka (M) atau belakang (B)
Koin II dapat menghasilkan 2 hasil yang mungkin, M atau B
Koin III dapat menghasilkan 2 hasil yang mungkin, M atau B
Jumlah titik sampel yang dihasilkan = (2) (2) (2) = 8
2.4.1 Kombinasi (Combination)
Kombinasi merupakan susunan dari suatu himpunan obyek yang dapat dibentuk tanpa
memilih r obyek dari sejumlah n obyek tanpa memperhatikan urutannya. Kombinasi merupakan sekatan dengan dua sel, sel pertama berisi r obyek yang dipilih dan (n – r) obyek sisanya. Jumlah kombinasi dari n obyek yang berlainan jika diambil sebanyak
r.
(
)
!! !
r n r
n Crn
− =
Contoh:
Suatu kelas terdiri atas 4 pria dan 3 wanita Banyaknya panitia yang dibentuk yang
beranggotakan 2 pria dan 1 wanita?
Banyaknya cara memilih 2 dari 4 pria = 6 ! 2 ! 2
! 4
4
2 = =
C
Banyaknya cara memilih 1 dari 3 wanita = 3 ! 2 ! 1
! 3
3
1 = =
C
Banyaknya panitia yang dapat dibentuk = (6) (3) = 18
2.4.2 Permutasi (Permutation)
Permutasi merupakan susunan dari suatu himpunan obyek yang dapat dibentuk yang
memperhatikan urutan. Banyaknya permutasi n obyek berlainan adalah n! Banyaknya permutasi n obyek berlainan bila diambil r sekaligus.
(
)
!!
r n
n Prn
−
= Banyaknya
permutasi n benda berlainan yang disusun melingkar adalah (n – 1)!
Banyaknya permutasi yang berlainan dari n obyek bila n1 adalah jumlah obyek jenis pertama, n2 adalah jumlah obyek jenis kedua, ..., nk jumlah obyek ke-k adalah:
! !... !
!
2
1 n nk
n n
Banyaknya cara menyekat n obyek dalam r sel bila masing-masing berisi n1 obyek pada sel pertama, n2 obyek pada sel kedua, dan seterusnya adalah :
! !... !
!
2
1 n nr
n n
2.5 Distribusi Probabilitas Diskrit
Penyajian distribusi probabilitas dalam bentuk grafis, tabel atau melalui rumusan tidak
masalah, yang ingin dilukiskan adalah perilaku (kelakuan) perubah acak tersebut.
Sering di menjumpai, pengamatan yang dihasilkan melalui percobaan statistik yang
berbeda mempunyai bentuk kelakuan umum yang sama.
Oleh karena itu perubah acak diskrit yang berkenaan dengan percobaan
tersebut dapat dilukiskan dengan distribusi probabilitas yang sama, dan dapat
dinyatakan dengan rumus yang sama.
Dalam banyak praktek yang sering di jumpai, hanya memerlukan beberapa
distribusi probabilitas yang penting untuk menyatakan banyak perubah acak diskrit.
2.5.1 Distribusi Seragam
Distribusi probabilitas yang paling sederhana adalah yang semua perubah acaknya
mempunyai probabilitas yang sama. Distribusi ini disebut distribusi probabilitas
seragam diskrit.
Jika perubah acak X mendapat nilaix1,x2, ,xkdengan probabilitas yang sama , maka distribusi probabilitas diskrit diberikan oleh:
; 1 ) ; (
k k x
f = untuk x = x1, x2, … , xk
Lambang f(x;k) sebagai pengganti f(x), yang menunjukan bahwa distribusi
k
1
X1 X2 X3 XK
Gambar 2.5 Distribusi Seragam
Rata-rata dan varians dari distribusi seragam diskrit adalah :
k x
k
i i
=
= 1
µ
(
)
k x
k
i i
=
− = 1
2
2
µ σ
Contoh:
Sebuah dadu seimbang dilemparkan satu kali, maka tiap unsur dalam ruang sampel
S={1, 2,3 4, 5, 6}. Muncul dengan probabilitas 1/6. Jadi jika X menyatakan mata dadu
yang muncul, maka X terdistribusi peluang seragam (uniform) yakni f(x;6)=1/6,
untuk x = 1, 2, 3, 4, 5, 6
2.5.2 Distribusi Binomial
Suatu percobaan yang terdiri atas beberapa usaha, tiap-tiap usaha, memberikan hasil
yang dapat dikelompokan menjadi 2-kategori yaitu sukses atau gagal, dan tiap-tiap
ulangan percobaan bebas satu sama lainnya. Probabilitas kesuksesan tidak berubah
dari percobaan satu ke percobaan lainnya. Proses ini disebut proses Bernoulli. Jadi
proses Bernoulli harus memenuhi persyaratan berikut:
1. Percobaan terdiri atas n-eksperimen yang berulang
2. Tiap-tiap eksperimen memberikan hasil yang dapat dikelompokan menjadi
2-kategori, sukses atau gagal
3. Peluang kesuksesan dinyatakan dengan p, tidak berubah dari satu eksperimen
ke eksperimen berikutnya.
Jadi proses Bernoulli adalah suatu proses dengan ciri-ciri eksperimen
berlangsung n kali dan tiap eksperimen berlangsung dalam cara dan kondisi yang
sama. Untuk setiap eksperimen hanya ada 2 (dua) kejadian yang mungkin terjadi,
dimana 2 (dua) kejadian tersebut adalah saling asing dan juga independent satu sama
lain. Biasanya 2 (dua) kejadian tersebut dinotasikan sebagai kejadian sukses dan
kejadian gagal. Probabilitas sukses dilambangkan dengan p, sedangkan probabilitas
gagal dilambangkan dengan q, dan p+q=1. Dari proses tersebut, yang di definisikan sebagai variabel adalah munculnya kejadian sukses, yang dilambangkan dengan x.
Untuk distribusi Binomial semacam itu, bisa dihitung probabilitas x sukses akan
muncul dalam n percobaan tersebut dengan rumus :
x n x x n x n
x p q
x n x n q p C p n x P x
F − −
− = = = )! ( ! ! ) , ; ( ) ( Dengan:
x = munculnya sukses yang ingin di hitung
n = jumlah eksperimen
p = probabilitas sukses dalam tiap eksperimen
q = probabilitas gagal dalam tiap eksperimen = 1 – p
n-x = jumlah gagal dalam n eksperimen
Distribusi binomial mempunyai nilai rata-rata = np dan nilai simpangan baku
= npq.
2.5.3 Nilai Harapan Distribusi Binomial
E(X) = = − = = n x x n x n x q p x n x F 0 0 ) (
= n x
n x q x n x n X − = − x 0 p )! ( ! ! .
= n x
n x q x n x n X − = − x 1 p )! ( ! ! .
= n x
= n.p x 1( 1) 1 p )! 1 ( 1 ( )! 1 ( )! 1 ( −− − = − − − −
− n x
n x q x n x n
y = x-1
x = 1 => y = 0
x = n => y = n – 1
= n.p n y
n y q y n y
n −−
−
= − −
− y 1
1 0 p )! 1 ( ! )! 1 (
= n.p (p + q)n -1
= n.p(1)n -1
= np
2.5.4 Variansi Distribusi Binomial
Var (X)
=
E [X2] - (E [X])2E [X2] =
= − = + − = n x x n x n x q p x n x x x x F x 0 0 2 } ) 1 ( { ) ( = = − − n x x n x q p x n x x 0 ) 1 ( + = − n x x n x q p x n x 0
= 2 2
2 1 .
2 n p qn− + 3 3 3
2 .
3 n p qn− + …+ n(n-1)pn + np = n(n-1)p2 (qn-2 + (n-2) pqn-3 +…+ pn-2) + np
= n(n-1)p2 (q + p)n-2 + np
= n(n-1)p2 + np
Jadi,
Var (X)
=
E [X2] - (E [X])2= n(n-1)p2 + np – n2p2
= np (1-p)
2.6 Distribusi Normal
Distribusi probailitas kontinyu yang terpenting di bidang statistik adalah distribusi
Normal. Grafiknya disebut kurva normal, berbentuk lonceng. Distribusi ini ditemukan
Karl Friedrich Gauss (1777-1855) yang juga disebut distribusi Gauss. Perubah acak
X yang bentuknya seperti lonceng disebut perubah acak normal dengan persamaan
matematik distribusi probabilitas yang bergantung paramerter µ (mean) dan
σ (simpangan baku). Dinyatakan n(x,µ,σ)
Gabar 2.6 Kurva Normal
Fungsi padat perubah acak normal X, dengan rata-rata µ dan simpangan
baku
σ
dinyatakan sebagai :2
) )( 2 1 (
2 1 )
, ;
( σ
µ
πσ σ
µ
− −
=
x
e x
n untuk −∞< x<∞
Dengan :
µ = mean
σ
= simpangan bakuπ = 3,14159…
e = 2, 71828…
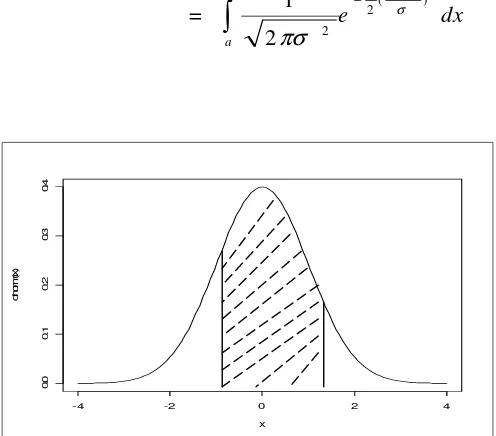
Luas daerah kurva normal antara x = a dan x = b dinyatakan sbb:
= ≤
≤ )
(a x b
P
b
a
dx x f( )
-4 -2 0 2 4
0
.0
0
.1
0
.2
0
.3
0
.4
x
d
n
o
rm
(x
= e dx x b a 2 ) ( 2 1 2 2
1 σµ
πσ
[image:31.612.126.374.90.308.2]− −
Gambar 2.7 Luas Derah P(a < x < b) = Luas Daerah Diarsir
2.6.1 Nilai Harapan Variabel Acak Normal
E [X]
=
∞
∞ −
dx x xf( )
=
x e dxx
x )2
( 2 1
2
1 σµ
π σ − − ∞ ∞ −
=
xe dxx
x )2
( 2 1
2
1 σµ
π σ − − ∞ ∞ −
σ µx x
z= −
;
σz+µx = x;
dz dxσ
1
=
;
dx=σdz=
σz µx e z σdzπ σ 2 2 1 ) ( 2
1 ∞ −
∞ −
+
=
z x e z dz2 2 1 ) ( 2
1 ∞ −
∞ −
+µ σ π
=
ze z dz2 2 1 2 − ∞ ∞ − π σ
+
x e z dz2 2 1 2 − ∞ ∞ − π µ
-4 -2 0 2 4
Untuk
ze z dz 2 2 1 2 − ∞ ∞ − π σ
=
( ) 2 0 2 1 0 21 2 2
dz ze dz
ze z z
∞ − ∞ − − + π σ 2 2 1 z
y= ; dy=zdz ;
z dy dz=
=
( ) 2 0 0 dy e dye y y
∞ − ∞ − − + π σ
untuk ze z dz
∞ − 0 2 1 2
=
z dy ze o y ∞ −=
dy e y ∞ − 0=
[ ]
− ∞ 0 y edimana lim − =0
∞ →
y
y e ; maka 0
0 = ∞ − dy e y
akibatnya ze z dz
2 2 1 2 − ∞ ∞ − π σ
=
) 0 0 ( 2π + σ=
0Untuk
x e z dz
2 2 1 2 − ∞ ∞ − π µ
=
( ) 2 0 2 1 0 21 2 2
dz e dz
e z z
x ∞ − ∞ − − + π µ y z z y 2 2 1 2 = → = z dy dz zdz
dy= → =
=
( ) 2 0 0 z dy e z dye y y
x ∞ − ∞ − − + π µ
=
) 2 1 2 1 ( 2 0 2 1 0 2 1 dy e y dy ey y y
x ∞ − − − ∞ − − + π µ
=
) 2 2 2 2 ( 2 π π π µ +x
=
x
µ
Sehingga :
E [X]
=
ze z dz2 2 1 2 − ∞ ∞ − π σ
+
x e z dz2 2 1 2 − ∞ ∞ − π µ
E [X]
=
0+µx2.6.2 Variansi Variabel Acak Normal
Var (X)
=
E [X2] - (E [X])2E [x2]
=
x e dx xx )2
( 2 1 2
2
1 σµ
π σ − − ∞ ∞ −
=
x e dxx
x )2
( 2 1 2
2
1 σµ
π σ − − ∞ ∞ − x x z x
z σ µ
σ µ + → − = dz dx dx dz σ σ → = = 1
=
σz µx e z σdzπ σ 2 2 1 2 ) ( 2
1 ∞ −
∞ −
+
=
z z x x e z dz2 2 1 2 2 ) 2 ( 2
1 ∞ −
∞ − + + σ µ µ σ π
=
z e z dz2
2 1 2
2
1 ∞ −
∞ −
σ
π
+
z e dzz x 2 2 1 2 2
1 ∞ −
∞ −
µ σ
π
+
e dzz x 2 2 1 2 2
1 ∞ −
∞ −
µ π
=
z e z dz2 2 1 2 2 2 − ∞ ∞ − π σ
+
x z e z dz2
2 1
2
2 ∞ −
∞ −
π σµ
+
x e z dz2 2 1 2 2 − ∞ ∞ − π µ
=
z e z dz2 2 1 2 2 2 − ∞ ∞ − π σ
+
0+
ππ µ 2 ( 2 2 x
=
z e z dz2 2 1 2 2 2 − ∞ ∞ − π σ
+
2x
µ
Untuk z e z dz
2 2 1 2 2 2 − ∞ ∞ − π σ
=
( ) 2 2 2 2 1 0 2 2 1 0 2 2 dz e z dz ez z − z
z e z dz 2 2 1 2 2 2 − ∞ ∞ − π σ
=
) 2 2 2 2 ( 2 0 0 2 ∞ − ∞ − − + y dy ye y dyye y y
π σ
=
) 2 2 2 2 ( 2 2 1 0 2 1 0 2 dy e y dy ey y −y
∞ − ∞ − + π σ
=
)) 2 1 ( 2 1 2 ) 2 1 ( 2 1 2 ( 2 2 Γ + Γ π σ=
) 2 2 2 2 ( 2 2 π π π σ +=
2σ
Sehingga : E [X2]
=
σ2+µX2Maka :
Var (X)
=
E [X2] - (E [X])2
=
σ2 +µX2-
µx2=
2σ
2.6.3 Distribusi Normal Standard
Keluarga distribusi normal memiliki jumlah yang banyak sekali, akibat pengaruh
rata-rata dan simpangan baku. Akan tetapi, untuk mencari probabilitas suatu interval dari
variabel random kontinu dapat di permudah dengan menggunakan bantuan distribusi
normal standard.
Distribusi normal standard adalah distribusi normal yang memiliki rata-rata
(µ) = 0 dan simpangan baku (σ) = 1. Bentuk fungsinya adalah :
2 2 1 2 1 )
(Z e z
f = −
Untuk mengubah distribusi normal umum menjadi distribusi normal standard
di gunakan nilai Z (standard units). Bentuk rumusnya adalah:
σ µ
− = X
Z
Dengan:
Z = Skor Z atau nilai normal baku
X = Nilai dari suatu pengamatan atau pengukuran
µ = Nilai rata-rata hitung suatu distribusi
σ = Standart deviasi suatu distribusi
Nilai Z (standard units) adalah angka atau indeks yang menyatakan penyimpangan suatu nilai variabel random (X) dari rata-rata (µ) dihitung dalam
satuan simpangan baku (σ).
2.6.4 Sifat-Sifat Normal Standard
Sifat-sifat penting dalam distribusi normal standard yaitu:
1) Grafiknya selalu ada di atas sumbu datar x
2) Bentuknya simetrik terhadap x = µ
3) Mempunyai satu modus, jadi kurva unimodal, tercapai pada x = µ
4) Grafiknya mendekati (berasimtutkan) sumbu datar x di mulai dari x = µ+3σ
ke kanan dan x = µ−3σ ke kiri
5) Luas daerah grafik selalu sama dengan satu unit persegi.
Untuk tiap pasang µ dan σ , sifat-sifat di atas selalu di penuhi, hanya bentuk
kurvanya saja yang berlainan. Jika σ makin besar, kurvanya makin rendah
Gambar 2.8 Distribusi Kurva Normal dengan µ Sama dan σσσσ Berbeda
Pada Gambar 2.8 menunjukkan bentuk distribusi dan kurva normal dengan
nilai tengah sama dan standart deviasi yang berbeda. Kurva normal demikian
mempunyai µ = Md = Mo yang sama, namun mempunyai σ yang berbeda. Semakin
besar σ , maka kurva semakin pendek dan semakin tinggi nilai σ , maka semakin
runcing. Oleh sebab itu, σ yang tinggi menunjukkan bahwa nilai data semakin
menyebar dari nilai tengahnya (µ). Sebaliknya apabila σ semakin rendah, maka nilai
semakin mengelompok pada nilai tengahnya, sehingga parameter nilai tengah menjadi
indikator yang baik bagi ukuran populasi.
Gambar 2.9 Distribusi Kurva Normal dengan µ Berbeda dan σ Sama
0 1 2 3 4 5 6 7 8 9 1 0
m
[image:36.612.131.502.497.678.2]Pada Gambar 2.9 menunjukkan bentuk distribusi probabilitas dan kurva
normal dengan µ berbeda dan σ sama, mempunyai jarak antara kurva yang berbeda,
namun bentuk kurva tetap sama. Hal demikian bisa terjadi karena kemampuan antar
[image:37.612.139.500.189.362.2]populasi berbeda, namun setiap populasi mempunyai keragaman yang hampir sama.
Gambar 2.10 Distribusi Kurva Normal dengan µµµµ dan σσσσ Berbeda
Pada Gambar 2.10 menunjukkan bentuk distribusi probabilitas dan kurva
normal dengan µ berbeda dan σ berbeda. Kurva yang demikian mempunyai titik
pusat yang berbeda pada sumbu mendatar dan bentuk kurva berbeda karena
mempunyai setandart deviasi yang berbeda. Kurva demikian relatif banyak terjadi,
karena antar-populasi terdapat perbedaan kemampuan, disamping itu di dalam setiap
populasi juga terdapat perbedaan, atau setiap populasi juga mempunyai keragaman
yang berbeda.
2.7 Menghampiri Distribusi Binomial dengan Distribusi Normal
Sebagaimana distribusi poisson sebagai penghampir distribusi binomial, maka
distribusi binomial dapat juga dihampiri dengan distribusi normal. Penghampiran ini
atas dasar teori asimtotik, yaitu dengan mengandaikan banyak pengamatan n dan
p tetap. Atas dasar perandaian ini maka : px p n x x
n x
n x
X P x
f − −
− = =
= (1 )
) ! ( !
! )
Pendekatan distribusi normal ini dapat di gunakan untuk pendekatan distribusi
binomial, dengan memenuhi beberapa syarat, yaitu :
a. Jumlah pengamatan relatif besar (n 30), dan nilai dari np 5 dan n(1-p) 5,
dimana n = jumlah data dan p adalah probabilitas sukses.
b. Memenuhi syarat binomial yaitu mempunyai peristiwa hanya 2 (dua), antara
percobaan bersifat independent, probabilitas sukses dan gagal sama untuk
semua percobaan dan data merupakan hasil perhitungan.
c. Rumus nilai normal untuk mendekati binomial adalah :
npq np X
Z = −
d. Faktor korelasi diperlukan dari binomial yang acak diskrit menjadi normal
BAB 3
PEMBAHASAN
3.1 Pendekatan Distribusi Binomial dengan Menggunakan Distribusi Normal
Dalam melakukan proses pengendalian kualitas, penting untuk melakukan pendekatan
suatu distribusi probabilitas dengan distribusi probabilitas yang lain. Proses
pendekatan akan berguna pada saat nilai tabel dari suatu distribusi tak ada. Dengan
pendekatan distribusi yang lain akan didapatkan nilainya dengan tabel. Selain itu
pendekatan distribusi dilakukan jika penggunaan distribusi aslinya tidak praktis.
Meskipun distribusi Poisson dapat di gunakan untuk mendekati distribusi
binomial, terutama dalam kasus-kasus dimana n sangat besar, sedangkan p sangat
kecil. Sebagai penggantinya kita dapat menggunakan distribusi normal untuk
mendekati distribusi binomial apabila n bertambah besar. Umumnya jika µ=np>5, kita akan dapat menggunakan distribusi normal.
Dengan melakukan proses standarisasi peta kendali p berarti dilakukan pendekatan distribusi Binomial yang merupakan distribusi asli probabilitas cacat
dengan menggunakan distribusi Normal.
Karena distribusi Binomial merupakan distribusi yang diskrit, dan distribusi
Normal merupakan distribusi yang kontinu, maka perlu ditambahkan faktor koreksi
kontinuitas (continuity correction), yaitu sebesar 0.5. Jika n bernilai besar, maka pendekatan distribusi Binomial dengan distribusi Normal dapat dilakukan dengan
np
=
Beberapa hal yang perlu dilakukan adalah dengan mengubah atau
membakukan distribusi normal dalam bentuk distribusi normal standard yang dikenal
dengan nilai Z atau skor Z. Rumus nilai Z adalah :
σ µ
− = X
Z
Dengan:
Z = Skor Z atau nilai normal standard
X = Nilai dari suatu pengamatan atau pengukuran
µ = Nilai rata-rata hitung suatu distribusi
σ = Standart deviasi suatu distribusi
Untuk mengubah pendekatan dari binomial ke normal menurut Lind (2002)
diperlukan faktor koreksi, selain syarat binomial terpenuhi yaitu : hanya terdapat dua
peristiwa, peristiwa tersebut bersifat independent, besar probabilitas sukses dan gagal
sama setiap percobaan dan data merupakan hasil penghitungan.
Apabila sudah memenuhi syarat binomial, maka kita menggunakan faktor
koreksi yang besarnya 0,05. Faktor koreksi ini diperlukan untuk mentransformasi dari
binomial menuju normal yang merupakan variabel acak kontinu.
3.2 Sifat Distribusi Binomial
Suatu percobaan yang terdiri atas beberapa usaha, tiap-tiap usaha, memberikan hasil
yang dapat dikelompokan menjadi 2-kategori yaitu sukses atau gagal, dan tiap-tiap
ulangan percobaan bebas satu sama lainnya. Probabilitas kesuksesan tidak berubah
dari percobaan satu ke percobaan lainnya. Proses ini disebut proses Bernoulli. Jadi
proses Bernoulli harus memenuhi persyaratan berikut:
1. Percobaan terdiri atas n-eksperimen yang berulang
2. Tiap-tiap eksperimen memberikan hasil yang dapat dikelompokan menjadi
2-kategori, sukses atau gagal
3. Peluang kesuksesan dinyatakan dengan p, tidak berubah dari satu eksperimen
4. Tiap eksperimen bebas dengan eksperimen lainnya.
Banyaknya X yang sukses dalam n- eksperimen Bernoulli disebut “peubah
acak binomial”, dan distribusi dari peubah acak ini disebut “distribusi Binomial”. Jika
p menyatakan probabilitas kesuksesan dalam suatu eksperimen, maka distribusi
peubah acak X ini dinyatakan dengan b(x;n,p). Karena nilainya bergantung pada
banyaknya eksperimen (n).
Probabilitas x kesuksesan dan n-x kegagalan dalam urutan tertentu. Tiap
kesuksesan dengan probabilitas p dan tiap kegagalan dengan probabilitas q=1-p .
Banyaknya cara untuk memisahkan n-hasil menjadi dua kelompok, sehingga x hasil
ada pada kelompok pertama dan sisanya n-x pada kelompok kedua, jumlah ini
dinyatakan sebagai
( )
nx Karena pembagian tersebut saling terpisah (bebas) makaprobabilitasnya adalah
( )
n x n xx p q
− .
Suatu usaha bernoulli dapat menghasilkan kesuksesan dengan probabilitas p
dan kegagalan dengan probabilitas q=1-p, maka distribusi probabilitas peubah acak
binomial X yaitu banyaknya kesuksesan dalam n- eksperimen bebas adalah :
( )
n x n xx x n x n
x p q C p q
p n x P x
f( )= ( ; , )= − = − dengan x = 1,2,3,...,n Adapun sifat-sifat dari distribusi binomial ini adalah:
1. Nilai rata-rata (µ) dari distribusi binomial yaitu banyaknya eksperimen
dikalikan dengan banyaknya sukses atau dengan kata lain µ = E (X) = np.
2. Nilai dari varians (σ2) untuk distribusi binomial adalah banyaknya eksperimen
dikalikan dengan banyaknya sukses dan banyaknya gagal atau dengan kata lain
2
σ = E (X - µ)2 = npq.
3. Nilai dari Simpangan baku (σ ) untuk distribusi binomial adalah akar dari
3.3 Teorema-Teorema Pendukung
Dalam proses untuk mendekatkan distribusi binomial dengan menggunakan distribusi
normal, maka diperlukan teorema-teorema pendukung yang terkait.
3.3.1 Teorema Limit Pusat ( Central Limit Theorem)
Teorema limit pusat menyatakan bahwa nilai tengah suatu sampel yang terdiri dari n
buah nilai variabel random yang menyebar secara tidak normal, akan tetapi menyebar
secara identik (dengan perkataan lain x1, x2, ..., xn memiliki fungsi kepadatan yang
sama) serta bebas terhadap sesamanya, penyebarannya akan mendekati sebaran
normal dengan pertambahan besarnya nilai n, jadi juga dengan bertambahnya ukuran
sampel.
Jika x1, x2, ..., xn adalah n variabel random independent dengan distribusi yang
identik dan memiliki mean µ dan varians σ2. Jumlahnya dinyatakan sebagai berikut:
X = x1 + x2 + ... + xn
Karena mean dari jumlah adalah jumlah semua mean dan varian dari jumlah
adalah jumlah semua varian, untuk variabel random independent, maka :
E (X) = nµ Var (X) = n 2
σ
Untuk setiap variabel random, mengurangi mean dan membaginya dengan
standart deviasi akan menghasilkan variabel random dengan mean 0 dan varian 1.
maka variabel random :
) (
) (
X Var
X E X
Z = − =
2
σ µ
n n X −
Kemudian dengan membagi pembilang dan penyebutnya dengan n, maka :
n X Z
σ µ
Dengan :
n X n
x x
x
X = 1+ 2+...+ n = adalah nilai rata-rata X
i.
Central Limit Theorem, jika x1, x2, ..., xn adalah n variabel random
independent dengan distribusi yang identik, dengan mean µ dan varian σ2.
Dilambangkan dengan X dan X adalah jumlah dari rata-rata dari variabel random ini. Sejalan dengan bertambahnya n, distribusi :
Z =
2
σ µ
n n X −
=
n X
σ µ
−
cenderung mendekati normal standard.
Dengan bantuan Central Limit Theorem ini, dalam prakteknya untuk masalah
jumlah dan rata-rata variabel random, distribusi normal akan memberikan perkiraan
yang cukup tepat mengenai distribusi yang sebenarnya.
Apapun distribusi dari sekelompok variabel random, selama variannya bersifat
finit, jumlah atau rata-rata dari sejumlah besar variabel tersebut akan berupa variabel
random dengan distribusi mendekati normal. Namun rata-rata variabel random dengan
distribusi seragam yang independent dalam jumlah cukup besar, akan memiliki
distribusi mendekati normal pula.
Bila nilai n makin besar, maka akan mendekati normal standard. Bentuk fungsi
densitas probabilitas untuk n variabel random independent dari distribusi Chi-squere
dengan derajat kebebasan 1. Validitas Central Limit Theorem tidak terbatas hanya
untuk jumlah variabel random kontinu, juga bisa berlaku untuk variabel random
diskrit.
3.3.2 Teorema De Moivre-Laplace
Misalkan x1, x2, ..., xn suatu barisan variabel random, Sn menyatakan banyaknya
dengan probabilitas sukses p, 0<p<1. Misalkan Zn, n = 1, 2, ... barisan variabel
random dengan :
npq np S
Z n
n
−
= ,
Dan misalkan z suatu tetapan. Maka, bila n menuju ke takberhingga, P(Zn > z)
mendekati luas pada distribusi normal standard di sebelah kanan z.
Atau dengan pernyataan lain teorema De Moivre-Laplace menyatakan bahwa :
Jika Sn banyaknya sukses dalam n percobaan Bernoulli dan p adalah probabilitas
sukses dan
npq np S
Z n
n
−
= , maka :
dt e z
Z P z F
z t
n Zn
∞ −
−
→ >
= 2
2
) (
)
( , dimana n .
Teorema De Moivre-Laplace merupakan suatu bentuk dari teorema limit pusat
yang cukup umum. Teorema ini membicarakan limit distribusi jumlah variabel
random, dan limit distribusinya biasanya normal. Pentingnya teorema ini ialah bahwa
dengan menggunakannya, dapat di hitung pendekatan peluang untuk jumlah variabel
random dengan menggunakan distribusi normal tanpa perlu tahu distribusi jumlah
variabel random dengan tepat.
3.4 Teknik Perhitungan Pendekatan Distribusi Binomial oleh Distribusi Normal
Oleh karena distribusi binomial adalah distribusi untuk variabel random diskrit yang
mana probabilitasnya berupa ordinat. Sedangkan distribusi normal merupakan
distribusi untuk variabel random kontinu yang mana probabilitasnya berupa area
(luasan), maka perlu diadakan penyesuaian (perubahan) dari ordinat menjadi luas.
(panjang dikalikan lebar). Penyesuaian ini dilakukan sebagai berikut :
Misalkan X berdistribusi B(n,p), maka P(X=x) merupakan ordinat pada absis
x. Tinggi ordinat sebagai nilai probabilitas dalam distribusi binomial, diambil sebagai
berpusat pada x, dengan panjang setinggi nilai ordinat dan lebarnya adalah 1 unit
(panjang interval x – 0,5 sampai dengan x + 0,5), sehingga didapatkan probabilitas
yang asli (probabilitas diskrit = ordinat) sama dengan luas persegi panjang tersebut.
Dengan memperhatikan proses pendekatan dari distribusi binomial ke
distribusi normal yang telah dibahas di atas, maka perhitungan pendekatan distribusi
binomial oleh distribusi normal dapat dilakukan dengan cara sebagai berikut :
Jika X ~ B(n,p), maka untuk keperluan penghitungan P(X=x) dengan
menggunakan distribusi normal adalah sebagai berikut:
P(X = x) = P (x – 0,5 < X < x + 0,5)
= − − < − < + −
npq np x
npq np X npq
np x
P ( 0,5) ( 0,5)
= − − < < + −
npq np x
Z npq
np x
P ( 0,5) ( 0,5)
Dengan Z ~ N(0,1)
P (X x) = ≥ − −
npq np x
Z
P ( 0,5)
P (X x) = ≤ + −
npq np x
Z
P ( 0,5)
P (x1 < X < x2) = P (x1 – 0,5 < X < x2 + 0,5)
= − − < − < + −
npq np x
npq np X npq
np x
P ( 1 0,5) ( 2 0,5)
= − − < < + −
npq np x
Z npq
np x
3.5 Contoh Kasus
Dari data kelahiran bayi menurut jenis kelamin di RS. Bunda Zahara Medan, selama
[image:46.612.136.503.175.340.2]bulan Januari – Juni 2007 diperoleh data seperti tabel di bawah ini:
Tabel 3.1 Tabel Kelahiran Bayi Menurut Jenis Kelamin
Bulan Laki-laki Perempuan Jumlah
Januari 34 orang 43 orang 77 orang
Februari 48 orang 25 orang 73 orang
Maret 39 orang 46 orang 85 orang
April 26 orang 42 orang 68 orang
Mei 47 orang 49 orang 96 orang
Juni 32 orang 37 orang 69 orang
Jumlah 226 orang 242 orang 468 orang
Dari data jenis kelamin bayi yang lahir diatas, dapat di peroleh hasil sebagai berikut :
Banyak bayi lahir = 468 orang, yang terdiri dari :
Jenis kelamin laki-laki = 226 orang
Jenis kelamin perempuan = 242 orang
Dari data sampel ini dapat dihitung misalnya :
a. Probabilitas proporsi kelahiran bayi laki-laki > 0,5
b. Probabilitas proporsi kelahiran bayi laki-laki < 0,5
c. Probabilitas proporsi kelahiran bayi laki-laki = 0,5
d. Probabilitas proporsi kelahiran bayi laki-laki antara 0,4 dan 0,5
Penyelesaian :
Misalkan X adalah variabel random yang menyatakan banyaknya bayi laki-laki yang
lahir.
n = 468 orang, p = peluang kelahiran bayi laki-laki = 468 226
= 0,4829,
q = 1-0,4829 = 0,5171
npq
=
a. Probabilitas kelahiran bayi laki-laki = 0,5 berarti :
X = (0,5) . (468) = 234, Sehingga :
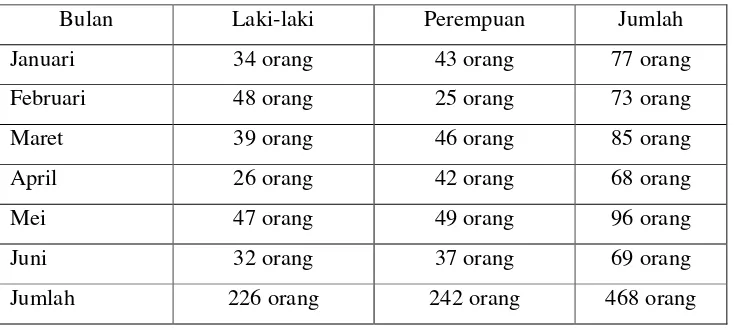
Probabilitas proporsi kelahiran bayi laki-laki > 0,5 adalah:
P (X > 234) = ( ( 0,5) )
npq np x
Z
P > − −
= )
8103 , 10
226 ) 5 , 0 234 (
(Z > − −
P
= P (Z > 0,69)
= 0,5 - 0,2549
= 0,2451
[image:47.612.153.407.291.432.2]Jadi probabilitas banyaknya bayi laki-laki lebih dari 234 orang adalah 0,2451.
Gambar 3.1 Kurva Kelahiran Bayi Laki-Laki > 0,5
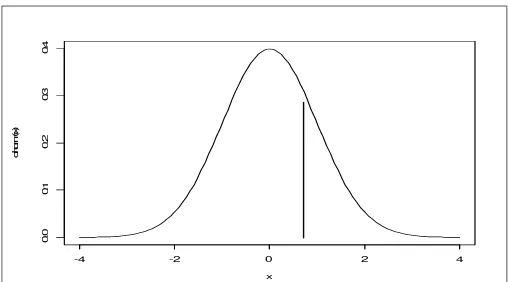
b. Probabilitas proporsi kelahiran bayi laki-laki < 0,5
P (X > 234) = ( ( 0,5) )
npq np x
Z
P < + −
= )
8103 , 10
226 ) 5 , 0 234 (
(Z < + −
P
= P (Z < 0,78)
= 0,5 + 0,2823
= 0,7823
Jadi, probabilitas banyaknya bayi laki-laki kurang dari 234 adalah 0,7823.
-4 -2 0 2 4
0
.0
0
.1
0
.2
0
.3
0
.4
x
d
n
o
rm
(x
Gambar 3.2 Kurva Kelahiran Bayi Laki-Laki < 0,5
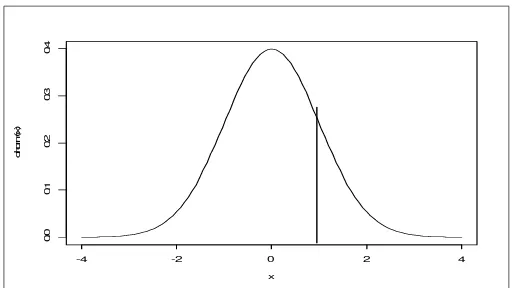
c. Probabilitas proporsi kelahiran bayi laki-laki = 0,5
P ( X = 234 ) =
(
−)
− < <(
+)
−npq np x
Z npq
np x
P 0,5 0,5
=
(
−)
− < <(
+)
− 8103 , 10226 5 , 0 234 8103
, 10
226 5 , 0 234
Z P
= P ( 0,69 < Z < 0,78 )
= 0,2823 – 0,2549
= 0,0274
[image:48.612.153.408.467.609.2]Jadi probabilitas banyaknya bayi laki-laki sama dengan 234 adalah 0,0274
Gambar 3.3 Kurva Kelahiran Bayi Laki-Laki = 0,5
-4 -2 0 2 4
0
.0
0
.1
0
.2
0
.3
0
.4
x
d
n
o
rm
(x
)
-4 -2 0 2 4
0
.0
0
.1
0
.2
0
.3
0
.4
x
d
n
o
rm
(x
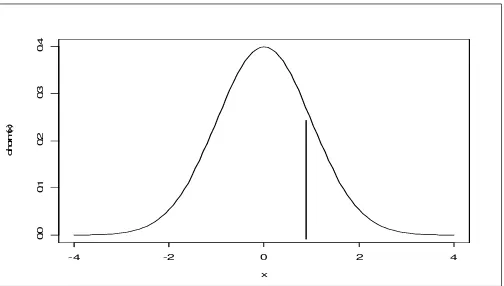
d. Probabilitas kelahiran bayi laki-laki = 0,4 berarti :
X = (0,4) . (468) = 187, sehingga :
Probabilitas proporsi kelahiran bayi laki-laki antara 0,4 dan 0,5 adalah :
P ( 187 < X < 234 ) =
(
−)
− < <(
+)
−npq np x
Z npq
np x
P 0,5 0,5
=
(
−)
− < <(
+)
− 8103 , 10226 5 , 0 234 8103
, 10
226 5 , 0 187
Z P
= P ( -3,65 < Z < 0,69)
= 0,4999 + 0,2549
= 0,7548
[image:49.612.163.472.158.297.2]Jadi brobabilitas banyaknya bayi laki-laki antara 187 dan 234 adalah 0,7548.
Gambar 3.4 Kurva Kelahiran Bayi Laki-Laki antara 0,4 dan 0,5
3.6 Simpangan Akibat Pendekatan
Untuk melihat besarnya simpangan yang terjadi akibat pendekatan, akan diperlihatkan
hasil perhitungan simpangan yang terjadi untuk setiap variabel random X (banyaknya
sukses) dalam distribusi binomial dengan parameter n dan p, untuk pendekatan suku
tunggal binomial maupun pendekatan binomial kumulatif. Dalam perhitungan ini
digunakan program microsoft excel.
Tabel Distribusi Binomial (Terlampir) di peroleh dengan jalan menjalankan
program untuk setiap parameter n dan p yang telah diketahui secara berulang-ulang.
-4 -2 0 2 4
0
.0
0
.1
0
.2
0
.3
0
.4
x
d
n
o
rm
(x
[image:49.612.163.415.320.463.2]Untuk probabilitas proporsi kelahiran bayi laki-laki > 0,5 dengan
menggunakan distribusi binomial adalah sebesar 0,2437. Sedangkan dengan
pendekatan distribusi normal diperoleh 0,2451. Itu berarti simpangan yang terjadi
adalah sebesar 0,2451 – 0,2437 = 0,0014
Untuk probabilitas proporsi kelahiran bayi laki-laki < 0,5 dengan
menggunakan distribusi binomial adalah sebesar 0,7842. Sedangkan dengan
pendekatan distribusi normal diperoleh 0,7823. Itu berarti simpangan yang terjadi
adalah sebesar 0,7842 – 0,7823 = 0,0019.
Untuk probabilitas proporsi kelahiran bayi laki-laki = 0,5 dengan
menggunakan distribusi binomial adalah sebesar 0,0280. Sedangkan dengan
pendekatan distribusi normal diperoleh 0,0274. Itu berarti simpangan yang terjadi
adalah sebesar 0,0280 – 0,0274 = 0,0006.
Untuk probabilitas proporsi kelahiran bayi laki-laki antara 0,4 dan 0,5 dengan
menggunakan distribusi binomial adalah sebesar 0,7541. Sedangkan dengan
pendekatan distribusi normal diperoleh 0,7548. Itu berarti simpangan yang terjadi
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Dari uraian bab-bab sebelumnya, maka dapatlah dibuat kesimpulan sebagai berikut :
1. Pada distribusi binomial dengan parameter n dan p, dengan rumus :
x n x x
n x n
x p q
x n x
n q
p C p n x P x
f − −
− = =
=
)! ( !
! )
, ; ( ) (
Dapat didekati dengan distribusi normal, dengan rumus :
2
) )( 2 1 (
2 1 )
( σ
µ
πσ
− −
=
x
e x
f untuk −∞<x<∞
2. Simpangan terbesar yang terjadi dalam pendekatan akan semakin besar jika
jarak p semakin jauh terhadap 0,5 dan atau n semakin kecil.
3. Pendekatan distribusi binomial oleh distribusi normal kurang baik dilakukan
untuk kondisi p yang berjarak jauh terhadap 0,5 dan n yang kecil.
4. Khusus untuk data kelahiran bayi, disini dapat diperoleh hasil taksiran dengan
interval yang relatif pendek (relatif baik), hal ini disebabkan karena dalam data
tersebut ukuran sampelnya cukup besar yaitu n = 468. Untuk probabilitas
proporsi kelahiran bayi laki-laki > 0,5, diperoleh distribusi binomialnya adalah
sebesar 0,2437, sedangkan dengan pendekatan distribusi normal diperoleh
0,2451. Sehingga simpangan yang terjadi adalah sebesar 0,2451 – 0,2437 =
0,0014. Untuk probabilitas proporsi kelahiran bayi laki-laki < 0,5, diperoleh
distribusi binomialnya adalah sebesar 0,7842, sedangkan dengan pendekatan
distribusi normal diperoleh 0,7823. Sehingga simpangan yang terjadi adalah
laki-laki = 0,5, diperoleh distribusi binomialnya adalah sebesar 0,0280,
sedangkan dengan pendekatan distribusi normal diperoleh 0,0274. Sehingga
simpangan yang terjadi adalah sebesar 0,0280 – 0,0274 = 0,0006. Untuk
probabilitas proporsi kelahiran bayi laki-laki antara 0,4 dan 0,5, diperoleh
distribusi binomialnya adalah sebesar 0,7541, sedangkan dengan pendekatan
distribusi normal diperoleh 0,7548. Sehingga simpangan yang terjadi adalah
sebesar 0,7548 – 0,7541 = 0,0007.
4.2 Saran
Saran yang dianggap perlu untuk dikemukakan sehubungan dengan kesimpulan, yaitu:
1. Dalam menentukan ukuran sampel yang akan digunakan dalam pendekatan
distribusi binomial oleh distribusi normal, sebaiknya dipenuhi kondisi bahwa
jika p semakin jauh dari 0,5 maka ukuran sampel yang diperoleh harus semakin
besar. Atau dengan perkataan lain simpangan pendekatan yang diinginkan
sebaiknya dijadikan salah satu faktor penentu dalam menentukan besarnya
ukuran sampel.
2. Untuk melihat besarnya simpangan yang di akibatkan dari pendekatan distribusi
binomial oleh distribusi normal, sebaiknya di buat tabel yang lebih lengkap
DAFTAR PUSTAKA
Adiningsih, Sri. 1993. Statistik. Yogyakarta: BPFE.
Boediono dan Koster, W. 2004. Teori dan Aplikasi Statistika dan Probabilitas. Bandung: Remaja Rosdakarya.
Hakim, Abdul. 2002. Statistik Induktif untuk Ekonomi dan Bisnis. Yogyakarta: Ekonisia.
Jong Jek Siang. 2002. Matematika Diskrit dan Aplikasinya pada Ilmu Komputer. Yogyakarta: Andi.
Noer, Ahmad. 2004. Statistik Deskriptif dan Probabilita. Yogyakarta: BPFE. Sarwoko. 2007. Statistik Inferensi untuk Ekonomi dan Bisnis. Yogyakarta: Andi. Suharyadi dan Purwanto. 2003. Statistika untuk Ekonomi dan keuangan Modren.
Bandung: Salemba Empat.
Supranto, J. 2001. Statistik Teori dan Aplikasi. Jilid 2. Jakarta: Erlangga.
LAMPIRAN
TABEL DISTRIBUSI BINOMIAL P
Binomial Tunggal
Binomial Kumulatif
46 4.82429E-72 5.45786E-72
47 4.04512E-71 4.5909E-71
48 3.31325E-70 3.77234E-70
49 2.6521E-69 3.02934E-69
50 2.07547E-68 2.37841E-68
51 1.58857E-67 1.82641E-67
52 1.18966E-66 1.3723E-66
53 8.7201E-66 1.00924E-65
54 6.25833E-65 7.26757E-65
55 4.39925E-64 5.12601E-64
56 3.02987E-63 3.54247E-63
57 2.04517E-62 2.39941E-62
58 1.3534E-61 1.59334E-61
59 8.78293E-61 1.03763E-60
60 5.59106E-60 6.62869E-60
61 3.49226E-59 4.15513E-59
62 2.14088E-58 2.55639E-58
63 1.28843E-57 1.54407E-57
64 7.6141E-57 9.15817E-57
65 4.41946E-56 5.33528E-56
66 2.52007E-55 3.0536E-55
67 1.41204E-54 1.7174E-54
68 7.77615E-54 9.49355E-54
69 4.20977E-53 5.15913E-53
70 2.24087E-52 2.75678E-52
71 1.17307E-51 1.44875E-51
72 6.04038E-51 7.48912E-51
73 3.05998E-50 3.8089E-50
74 1.52534E-49 1.90623E-49
75 7.48315E-49 9.38939E-49
76 3.61365E-48 4.55259E-48
77 1.718E-47 2.17326E-47
78 8.04246E-47 1.02157E-46
79 3.70774E-46 4.72931E-46
80 1.68365E-45 2.15658E-45
81 7.53149E-45 9.68807E-45
82 3.31941E-44 4.28822E-44
83 1.44163E-43 1.87045E-43
84 6.17045E-43 8.0409E-43
85 2.60323E-42 3.40731E-42
86 1.08267E-41 1.4234E-41
87 4.43937E-41 5.86277E-41
88 1.79493E-40 2.3812E-40
89 7.15686E-40 9.53807E-40
90 2.81451E-39 3.76831E-39
P
Binomial Tunggal
Binomial Kumulatif
1 3.9211E-132 3.9301E-132
2 8.5503E-130 8.5896E-130
3 1.2403E-127 1.2489E-127
4 1.3465E-125 1.359E-125
5 1.1669E-123 1.1805E-123
6 8.4091E-122 8.5271E-122
7 5.1829E-120 5.2682E-120
8 2.7891E-118 2.84