7 2.1 Algoritma Pencarian String
Pencarian data sering juga disebut table look-up atau storeage and retrieval information adalah suatu proses untuk mengumpulkan sejumlah informasi di dalam computer dan kemudian mencari kembali informasi yang diperlukan secepat mungkin.
Metode pencarian data dapat dilakukan dengan dua cara yaitu pencarian internal (internal searching) dan pencarian eksternal (external searching). Pada pencarian internal, semua rekaman yang diketahui berada dalam komputer sedangkan pada pencarian eksternal, tidak semua rekaman yang diketahui berada dalam data komputer, tetapi ada sejumlah rekaman yang tersimpan dalam penyimpanan luar misalnya CD atau flashdisk. Selain itu metode pencarian data juga dapat dikelompokkan menjadi pencarian statis (static searching) dan pencarian dinamis (dynamic searching). Pada pencarian statis, banyaknya rekaman yang diketahui dianggap tetap, pada pencarian dinamis, banyaknya rekaman yang diketahui bisa berubah-ubah yang disebabkan oleh penambahan atau penghapusan suatu rekaman.
Ada dua macam teknik pencarian yaitu pencarian sekuensial dan pencarian biner. Perbedaan dari dua teknik ini terletak pada keadaan data. Pencarian
sekuensial digunakan apabila data dalam keadaan acak atau tidak terurut. Sebaliknya, pencarian biner digunakan pada data yang sudah dalam keadaan urut.
Algoritma pencarian string atau sering disebut juga pencocokan string adalah algoritma untuk melakukan pencarian semua kemunculan string pendek pattern[0..n − 1] yang disebut pattern pada string yang lebih panjang teks[0..m − 1] yang disebut teks.
Pencocokkan string merupakan permasalahan paling sederhana dari semua permasalahan string lainnya dan dianggap sebagai bagian dari pemrosesan data, pengkompresian data, analisis leksikal, dan temu balik informasi.
2.1.1 Algoritma Boyer-Moore
Algoritma Boyer-Moore adalah salah satu algoritma untuk mencari suatu string di dalam teks, dibuat oleh R.M Boyer dan J.S Moore. Ide utama algoritma ini adalah mencari string dengan melakukan pembandingan karakter mulai dari karakter paling kanan dari string yang dicari. Algoritma ini dianggap sebagai algoritma yang paling efisien pada aplikasi umum. Dengan mengunakan algoritma ini, secara rata-rata proses pencarian akan menjadi lebih cepat jika dibandingakan dengan algoritma lainnya. Alasan melakukan pencocokan dari kanan (posisi terakhir string yang dicari) seperti terlihat pada Tabel 2.1.
Tabel 2.1 Pencocokan String Pertama
k a n a n k i r i a k u r a d i o
Tabel 2.1 melakukan pembandingan dari posisi paling akhir string dapat dilihat bahwa karakter “n” pada string “kanan” tidak cocok dengan karakter “o” pada string “radio” yang dicari, dan karakter “n” tidak pernah ada dalam string “radio” yang dicari sehingga string “radio” dapat digeser melewati string “kanan” sehingga posisinya menjadi seperti yang terlihat pada Tabel 2.2.
Tabel 2.2 Pencocokan String Kedua
k a n a n k i r i a k u r a d i o
r a d i o
Dalam Tabel 2.2 terlihat bahwa algoritma Boyer-Moore memiliki loncatan karakter yang besar sehingga mempercepat pencarian string karena dengan hanya memeriksa sedikit karakter, dapat langsung diketahui bahwa string yang dicari tidak ditemukan dan dapat digeser ke posisi berikutnya.
2.1.2 Karakteristik Algoritma Boyer-Moore
Karakteristik algoritma Boyer-Moore adalah sebagai berikut: 1. Melakukan perbandingan dari kanan ke kiri
2. Fase persiapan / prepocessing membutuhkan kompleksitas waktu O(m + σ)
3. Fase pencarian membutuhkan kompleksitas waktu O(n/m)
4. Pada kasus terburuk, sebanyak 3n karakter teks yang dibandingkan untuk pattern yang tak berulang.
2.1.3 Konsep Dasar Algoritma Boyer-Moore
Algoritma Boyer-Moore memiliki empat konsep dasar yang digunakan dalam prosesnya. Keempat konsep tersebut adalah sebagai berikut:
1. Preprocessing
Keseluruhan pre-computation dari algoritma Boyer-Moore terdiri dari bad-character preprocessing dan kedua bagian dari good-suffix preprocessing. Untuk bagian preprocessing ini, diperlukan tiga array yaitu occ, f dan s. Di bawah ini adalah prosedur preprocessing.
1 2 3 4 5 6 7
Procedure bmprecomp (var pat:string,s,f,occ: array_of_integer, m: integer) Begin badprecomp(pat, occ, m); goodprecomp1(pat, s, f, m); goodprecomp2(pat, s, f, m); End_of_Procedure
Gambar 2.1 Preprocessing algoritma Boyer-Moore
Preprocessing terdiri dari bad-character preprocessing dan good-suffix preprocessing. Penjelasannya adalah sebagai berikut :
a. Preprocessing untuk Bad-Character Rule
Fungsi berikut ini adalah “compute-last-occurrence-function” yang digunakan untuk precompute array occ. Algoritma dari bad-character preprocessing adalah:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Procedure compute_last_occurence_function(var p:string, occ: array of integer, m: integer)
Declaration c: char
i , j, a: integer; Begin
//initialize the occ array
For i ← 0 to ALPHABET_SIZE do occ[i] ← -1 For j ← 0 to m do Begin C ← P[j] occ[a] ← j End_for End_of_Procedure
Gambar 2.2 Preprocessing untuk Bad-Character Rule b. Preprocessing untuk good-suffix rule
Sebelum memperkenalkan aturan good-suffix terdapat beberapa definisi yaitu :
A adalah sebuah alphabet dan x = x0...xk-1, k Є n, sebuah string yang panjangnya k sampai A.
Prefix dari x adalah sebuah substring u dengan u = x0...xb-1 dimana b Є {0, ..., k} i.e. x dimulai dengan u.
Suffix dari x adalah substring u dengan u = xk-b... xk-1 dimana b Є {0, ..., k} i.e. x diakhiri dengan u.
Prefix u dari x atau suffix u dari x dinamakan proper prefix atau suffix, berturut-turut, jika u ≠ x, i.e. jika panjang b lebih sedikit dari k. Border atau pinggiran dari x adalah substring r dengan r = x0 ... xb-1 dan r = xk-b...xk-1 dimana b Є{0, ..., k-1}. Border dari x adalah substring adalah proper prefix dan proper suffix dari x. Disebut sebagai panjang b (
lebar dari border).
Untuk aturan good-suffix, diperlukan sebuah array s. Setiap anggota dari s[i] berisi jarak pergeseran dari pattern jika sebuah ketidakcocokan terjadi pada posisi : i-1, jika suffix dari pattern dimulai pada posisi cocok. Dalam rangka menentukan jarak pergeseran, dua kasus harus dipertimbangkan.
Gambar 2.3. adalah implementasi good-suffix-rule preprocessing : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Procedure goodprecomp1(var p: string, s: string, f:array_of_integer, m: integer) Declaration i, j : integer Begin i ← m j ← m+1 f[i] j while i>0 do begin
while j<=m and p[i=1]?p[j-1] do begin if s[j] = 0 then s[j] j-1 j ← f[j] end_while i ← i-1 j ← j-1 f[i] ← j end_while End_of_procedure
Gambar 2.3 Preprocessing untuk Bad-Character Rule 2. Right-to-left Scan Rule
Prinsip dasar yang pertama dari algoritma Boyer-Moore adalah melakukan perbandingan antara pattern yang dicari dengan target teks secara terbalik yaitu bergerak dari kanan ke kiri. Perbandingan pattern dengan target teks dimulai dengan membandingkan karakter terakhir dari pattern (karakter
paling kanan) dengan target teks. Apabila ada kecocokan maka perbandingan akan dilanjutkan dengan bergerak ke kiri sampai karakter pertama dari pattern. Sedangkan apabila terjadi ketidakcocokan maka akan dilakukan pergeseran, besarnya pergesaran yang dilakukan ditentukan oleh dua fungsi pergeseran yaitu bad-character shift dan good-suffix shift.
3. Bad-character Shift Rule
Aturan bad-character shift dibutuhkan untuk menghindari pengulangan perbandingan yang gagal dari suatu karakter dalam target teks dengan pattern. Besarnya pergeseran yang dilakukan dalam aturan bad-character shift disimpan dalam bentuk tabel yang dapat kita namakan tabel BcS, table ini terdiri dari dua kolom yaitu kolom karakter dan kolom shift yang menunjukkan besarnya pergeseran yang harus dilakukan. Proses kalkulasi untuk pengisian table BcS ini adalah dengan cara memberikan index angka kepada tiap karakter dalam pattern. Index 0 diberikan pada karakter terakhir/paling kanan dari pattern, kemudian bergerak ke kiri, semakin ke kiri index dinaikkan 1 sampai pada karakter pertama pada pattern dan apabila karakter pada posisi tersebut belum ada maka karakter tersebut dimasukkan pada tabel BcS dengan nilai pada kolom shift disesuaikan dengan index.
4. Good Suffix Shift Rule
Aturan good-suffix shift dibuat untuk menangani kasus dimana terdapat pengulangan karakter pada pattern. Contoh dibawah ini akan menjelaskan bagaimana aturan bad-character shift gagal dalam menangani adanya perulangan bagian dalam pattern.
T: abccbcccbaa P: abcbbc
Pada kasus diatas aturan bad-character shift akan menghasilkan pergeseran yang negatif. Untuk kasus seperti ini kita dapat melakukan pergeseran sebanyak 1. Sehingga kita memerlukan aturan good-suffix untuk menentukan pergeseran maksimum yang mungkin berdasarkan struktur dari pattern.
Precomputation dari algoritma Boyer-Moore terdiri dari bad-character preprocessing dan good-suffix preprocessing. Prinsip dasar yang pertama dari algoritma Boyer-Moore adalah melakukan perbandingan antara pattern yang dicari dengan teks. Perbandingan pattern dengan teks dilakukan dari arah kanan ke kiri. Perbandingan dimulai dengan membandingkan antara karakter paling kanan dari pattern dengan teks. Jika terjadi kecocokkan, maka perbandingan akan dilanjutkan dengan karakter yang di sebelah kiri dari yang dibandingkan sampai ke karakter pertama dari pattern. Jika terjadi ketidakcocokkan maka akan dilakukan pergeseran yang ditentukan oleh 2 fungsi pergeseran yaitu bad-character shift dan good suffix shift.
Aturan dari bad-character shift dibutuhkan untuk menghindari pengulangan perbandingan yang gagal dari suatu karakter dalam teks dengan pattern. Aturan dari good suffix shift dibutuhkan untuk menangani kasus yang di dalamnya terdapat pengulangan karaker pada pattern.
Algoritma pencocokan string Boyer-Moore didasarkan atas dua teknik : 1. Teknik looking-glass, menemukan pattern di dalam teks dengan
menggerakan pattern mundur dimulai dari akhir teks.
2. Teknik character-jump, pergeseran karakter yang dilakukan saat terjadi ketidak cocokan.
2.1.4 Langkah Pencocokan String Algoritma Boyer-Moore
Secara sistematis, langkah-langkah yang dilakukan algoritma Boyer-Moore pada saat mencocokkan string adalah:
1. Algoritma Boyer-Moore mulai mencocokkan pattern pada awal teks.
2. Dari kanan ke kiri, algoritma ini akan mencocokkan karakter per karakter pattern dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut dipenuhi:
a. Karakter pattern dan karakter teks yang dibandingkan tidak cocok (mismatch).
b. Semua karakter pattern cocok. Kemudian algoritma akan memberitahukan penemuan di posisi ini.
3. Algoritma kemudian menggeser pattern dengan memaksimalkan nilai penggeseran good-suffix dan penggeseran bad-character, lalu mengulangi langkah 2 sampai pattern berada di ujung teks.
2.1.5 Cara Kerja Algoritma Boyer-Moore
Berikut ini adalah cara kerja pencarian string dengan algoritma Boyer-Moore misalnya ada sebuah usaha pencocokan yang terjadi pada teks[i..i + n−1], dan anggap ketidakcocokan pertama terjadi diantara teks[i + j] dan pattern[j], dengan 0 < j < n. Berarti, teks[i + j + 1..i + n − 1] = pattern[j + 1..n−1]
dan a = teks[i + j] tidak sama dengan b = pattern[j]. Jika u adalah akhiran dari pattern sebelum b dan v adalah sebuah awalan dari pattern, m adalah panjang string yang akan dicari, dan n adalah panjang string yang tersedia maka penggeseran-penggeseran yang mungkin adalah:
1. Penggeseran good-suffix yang terdiri dari mensejajarkan potongan text[i + j + 1..i + n − 1] = pattern[j + 1..n − 1] dengan kemunculannya paling kanan dalam pattern yang didahului oleh karakter yang berbeda dengan pattern[j]. Jika tidak ada potongan seperti itu, maka algoritma akan mensejajarkan akhiran v dari text[i + j + 1..i + n − 1] dengan awalan dari pattern yang sama.
2. Penggeseran bad-character yang terdiri dari mensejajarkan text[i + j] dengan kemunculan paling kanan karakter tersebut di pattern. Bila karakter tersebut tidak ada pada pattern, maka pattern akan disejajarkan dengan text[i + n + 1].
2.1.6 Kompleksitas Algoritma Boyer-Moore
Penggeseran bad-character dan good-suffix dapat dihitung dengan kompleksitas waktu dan ruang O(m + σ) dengan σ adalah besar ruang alfabet. Sedangkan pada fase pencarian, algoritma ini membutuhkan waktu pencarian sebesar O(n/m), n adalah teks (text) yaitu panjang string yang tersedia dan m adalah pattern yaitu panjang string yang akan dicocokan. Kompleksitas algoritma Boyer-Moore adalah sebagai berikut (R.S. Boyer dan J.S. Moore, 1977 : 20).
1. Time Complexity
Rata-rata algoritma membutuhkan waktu O(n/m) pada bahasa teks yang alami untuk nilai m yang kecil.
2. Space Complexity
Space complexity dari algoritma Boyer-Moore adalah O(m+ | σ |). 3. Preprocessing Time
Algoritma Boyer-Moore memerlukan waktu O(m + | σ |) untuk precompute lastoccurrence array untuk aturan bad character. Dan waktu untuk preprocessing untuk menjalankan fungsi good-suffix adalah O(m).
2.1.7 Contoh Kasus Pencarian String
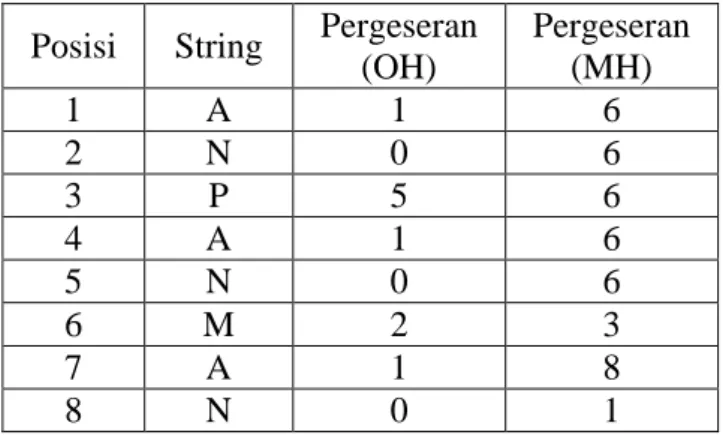
Dalam implementasinya, algoritma Boyer-Moore akan memilih nilai pergeseran terbesar dari 2 tabel pergeseran (Occurence Heuristic dan Match Heuristic). Implementasi algoritma Boyer-Moore dalam sebuah contoh kasus terlihat pada Tabel 2.3.
Tabel 2.3 Kasus Pencarian String Posisi String Pergeseran
(OH) Pergeseran (MH) 1 A 1 6 2 N 0 6 3 P 5 6 4 A 1 6 5 N 0 6 6 M 2 3 7 A 1 8 8 N 0 1
Teks : berikut ini anpamman bukan anpanman; pattern : anpanman pada tabel OH, –> selain karakter “a”,”n”,”p”,”m” nilai pergeseran sebesar panjang string yaitu 8.
1. Preprocessing tahap pertama
Pada preprocessing tahap pertama, pencocokan string pattern dimulai dengan mencocokan string pattern dengan deretan string teks yang pertama “berikut” seperti yang terlihat pada Tabel 2.4.
Tabel 2.4 Preprocessing Tahap Pertama
Hasil preprocessing tahap pertama adalah sebagai berikut : a. Spasi tidak cocok dengan “n”
b. Tabel OH : karakter spasi nilai pergeserannya = 8 belum ada karakter yang cocok.
c. Tabel MH : ketidakcocokan pada posisi 8 (karakter “n”) nilai pergeserannya=1 sehingga geser string sebesar 8 posisi (nilai maksimal dari kedua tabel pergeseran).
2. Preprocessing tahap kedua
Pada tahap ini string pattern digeser sebanyak delapan karakter terhadap string teks, karena delapan karakter sebelumnya tidak cocok. Sehingga pencocokan string pattern dimulai pada karakter ke-9 dari string teks seperti yang terlihat pada Tabel 2.5.
Tabel 2.5 Prepocessing Tahap Dua
Hasil preprocessing tahap kedua adalah sebagai berikut : a. ”a” tidak cocok dengan “n”
b. Tabel OH : karakter “a” nilai pergeserannya = 1 belum ada karakter yang cocok
c. Tabel MH : ketidakcocokan pada posisi 8 (karakter “n”) nilai pergeserannya=1, sehingga geser string sebesar 1 posisi (nilai maksimal dari kedua tabel pergeseran)
3. Preprocessing tahap ketiga
Pada tahap ini pencocokan string dimulai pada string ke-10 karena pergeseran string hanya satu karakter pada tahap sebelumnya seperti yang terlihat pada Tabel 2.6.
Tabel 2.6 Preprocessing Tahap Ketiga
Hasil pencocokan string pada tahap ini adalah sebagai berikut. a. ”m” tidak cocok dengan “n”.
b. Tabel OH : karakter “m” nilai pergeserannya = 2 belum ada karakter yang cocok.
c. Tabel MH : ketidakcocokan pada posisi 8 (karakter “n”) nilai pergeserannya=1 sehingga geser string sebesar 2 posisi (nilai maksimal dari kedua tabel pergeseran)
4. Bad Character Rule
Pada tahap ini pencocokan string dimulai pada karakter ke-12 dari string teks karena pergeseran pada tahap sebelumnya adalah dua karakter seperti yang terlihat pada Tabel 2.7.
Tabel 2.7 Tahap Bad Character Rule
Hasil pencocokan string pada tahap ini yaitu : a. ”a” tidak cocok dengan “n”
b. Tabel OH : karakter “a” nilai pergeserannya = 1 belum ada karakter yang cocok
c. Tabel MH : ketidakcocokan pada posisi 8 (karakter “n”) nilai pergeserannya=1 -sehingga geser string sebesar 1 posisi (nilai maksimal dari kedua tabel pergeseran)
5. Good Suffix Rule
Pencocokan string dimulai pada karakter ke-13 karena pergeseran pada tahap sebelumnya hanya satu karakter seperti yang terlihat pada Tabel 2.8.
Tabel 2.8 Tahap Good Suffix Rule
Hasil pencocokan string pada tahap ini adalah sebagai berikut : a. ”n” cocok dengan “n”
c. ”m” cocok dengan “m” d. ”m” tidak cocok dengan “n”
e. Tabel OH : karakter “m” nilai pergeserannya = 2, sudah ada 3 karakter cocok, nilai pergeseran = 2-3=-1 (pergeseran tidak mungkin dilakukan, hal ini merupakan kekurangan Tabel Occurence Heuristic, ada kemungkinan nilai pergeseran menjadi negatif) f. Tabel MH : ketidakcocokan pada posisi 5 (karakter “n”) nilai
pergeserannya=6 sehingga geser string sebesar 6 posisi (nilai maksimal dari kedua tabel pergeseran)
6. Bad Character Shif Rule
Pencocokan string dimulai pada karakter ke-19 karena pergeseran pada tahap sebelumnya adalah 6 karakter seperti yang terlihat pada Tabel 2.9.
Tabel 2.9 Tahap Bad Character Shift Rule
Hasil pencocokan string pada tahap ini adalah sebagai berikut : a. ”n” cocok dengan “n”
b. ”a” cocok dengan “a” c. ”k” tidak cocok dengan “m”
d. Tabel OH : karakter “k” tidak ada dalam string, sudah ada 2 karakter cocok, sehingga nilai pergeserannya =8-2=6
e. Tabel MH : ketidakcocokan pada posisi 6 (karakter “m”) nilai pergeserannya=3 sehingga geser string sebesar 6 posisi
7. Good Suffix Shift Rule
Pencocokan string dimulai pada karakter ke-25 karena pergeseran pada tahap sebelumnya adalah 6 karakter seperti yang terlihat pada Tabel 2.10.
Tabel 2.10 Tahap Good Suffix Shift Rule
Hasil pencocokan string pada tahap ini adalah sebagai berikut : a. ”n” cocok dengan “n”
b. ”a” cocok dengan “a” c. ”p” tidak cocok dengan “m”
d. Tabel OH : karakter “p” nilai pergeseran 5, sudah ada 2 karakter cocok, sehingga nilai pergeserannya = 5-2=3.
e. Tabel MH : ketidakcocokan pada posisi 6 (karakter “m”) nilai pergeserannya=3 sehingga geser string sebesar 3 posisi (nilai maksimal dari kedua tabel pergeseran).
Semua karakter cocok, string yang dicari telah ditemukan. Berikut ini adalah hasil pencarian string “anpanman” seperti yang terlihat pada Tabel 2.11.
2.2 Perputakaan
2.2.1 Pengertian Perpustakaan
Perpustakaan berasal dari kata pustaka, yang berarti buku. Setelah mendapat awalan per dan akhiran an menjadi perputakaan, yang berarti kitab, kitab perimbon atau kumpulan buku-buku, yang kemudian disebut koleksi bahan pustaka. Istilah itu berlaku untuk perputakaan yang masih bersifat tradisional atau perpustakaan konvensional. Untuk perpustakaan modern, dengan paradigm baru (kerangka berpikir atau model ilmu pengetahuan), koleksi perpustakaan tidak hanya terbatas berbentuk buku-buku, majalah Koran, atau barang tercetak (printed matter) lainnya. Koleksi perpustakaan telah berkembang dalam bentuk terekam, dan digital (recorded matter). Selanjutnya, buku-buku dan bahan pustaka yang lain tersebut harus ditata dan disusun rapi di rak dan tempat-tempat yang sudah ditentukan di dalam ruangan atau gedung tersendiri, setelah diolah atau diproses menurut suatu system tertentu. Kemudian dibuatkan kartu-kartu katalog, sebagai wakil dari koleksi perpustakaan, untuk pedoman penyusunan dan menemukan kembali. Sebuah perpustakaan tersebut dikelola oleh petugas-petugas yang telah dipersiapkan dengan dibekali kemampuan, ilmu pengetahuan dan keterampilan tertentu. Mereka bertugas melayani pemakai perpustakaan. Setelah proses itu akhirnya perpustakaan tersebut dipergunakan oleh mereka yang direncanakan atau diharapkan memakainya. (Sutarno, 2006:11).
a. Adanya kumpulan buku-buku dan bahan pustaka lainnya, baik tercetak, terekam maupun dalam bentuk lain sesuai perkembangan ilmu pengetahuan dan teknologi.
b. Koleksi tersebut ditata menurut suatu system tertentu, diolah / diproses meliputi registrasi dan identifikasi, klasifikasi, katalogisasi, da dilengkapi dengan perlengkapan koleksi, seperti slip buku, kartu-kartu katalog, kantong buku dan lain sebagainya. Koleksi itu tidak sekedar ditumpuk, sehingga terkesan seperti gudang buku.
c. Semua sumber informasi ditempatkan di gedung atau ruangan tersendiri, dan sebaiknya tidak disatukan dengan kantor atau kegiatan yang lainnya. d. Perpustakaan semestinya dikelola atau dijalankan oleh petugas-petugas,
dengan persyaratan tertentu yang meliputi melayani pemakai, dengan sebaik-baiknya.
e. Ada masyarakat pemakai perpustakaan tersebut, baik untuk membaca, meminjam, meneliti, menggali, menimba, dan mengembangkan ilmu pengetahuan yang diperoleh di perpustakaan, sehingga perpustakaan sering disebut sebagai gudang ilmu.
f. Perpustakaan merupakan instansi yang perlu bermitra dengan lembaga yang berkaitan dengan proses penyelnggaraan pendidikan secara langsung dan tidak langsung, baik formal maupun nonformal.
2.2.2 Jenis-jenis Perpustakaan
Sejak perpustakaan dikenal dan dikembangkan oleh umat manusia pada masa silam bersamaan dengan perkembangan budaya, perpustakaan telah
mengalami banyak sekali perubahan. Perubahan ini meliputi antara lain : jenis koleksi, bentuk dan bahan pustaka, kemasan, system pengelolaan, pemanfaatan, sampai dengan penyebaran kepada masyarakat. Sementara jenis perpustakaan juga kini makin bertambah jika dibandingkan masa-masa yan glalu. Pertambahan dalam jenis perpustakaan dipengaruhi oleh beberapa hal, misalnya lembaga pengelola, penekanan wilayah, masyarakat pemakai, ruang lingkup wilayah kerjanya, dan tujuan pembentukannya.
Beberapa jenis-jenis perpustakaan yang sekarang ada dan dikembangkan di Indonesia adalah :
1. Perpustakaan Nasional Republik Indonesia
Perpustakaan Nasional Republik Indonesia (Perpusnas RI) berkedudukan di ibukota Negara, satusnya merupakan Lembaga Pemerintah Non-Departemen (LPND). Kepala Perpustakaan Nasional RI bertanggung jawab kepada Presiden. (Kepres No. 17 tahun 2001, tentang Susunan Organisasi dan Tugas Lembaga Pemerintah Non-Departemen). Dilihat dari sudut pandang kedudukan dan eselionisasi, Perpustakaan Nasional RI merupakan salah satu Lembaga Pemerintah Non-Departemen yang menduduki eselon satu. Suatu penghargaan yang terhormat dan berbeda dengan perpustakaan di negara-negara lain. Perpusna RI berfungsi sebagai pusat referensi nasional, pusat penelitian, pusat kerja sama nasional dan internasional bidang perpustakaan, dan sebagai pusat deposit nasional.
2. Badan Perpustakaan Provinsi
Badan Perpustakaan Provinsi berbeda pada tiap provinsi di Indonesia, kecuali untuk provinsi-provinsi baru yan gbelum sempat membentuk perpustakaan. Perpustakaan tersebut milik pemerintah daerah. Kepala Badan Perpustakaan Provinsi bertanggung jawab kepada Gubernur. Badan Perpustakaan Provinsi berfungsi sebagai pusat kerja sama perpustakaan di daerah yang bersangkutan dan sebagai Pembina semua jenis perpustakaan di provinsi, sebagai pusat deposit daerah, pusat penelitian daerah, dan memberikan layanan informasi, pendidikan, dan ilmu pengetahuan kepada masyarakat.
3. Perpustakaan Perguruan Tinggi
Perpustakaan perguruan tinggi, yan gmencakup universitas, sekolah tinggi, institute, akademi, dan lain sebagainya. Perpustakaan tersebut berada di lingkungan kampus. Pemakainya adalah sivitas akademi perguruan tinggi tersebut, dan tugas dan fungsinya yang utama adalah menunjang proses pendidikan, penelitian dan pengabdian kepada masyarakat.
4. Perpustakaan Umum
Perpustakaan umum berada di tigas tingkatan pemerintah yakni (1) perpustakaan umum kabupaten dan kota di seluruh Indonesia, (2) perputakaan umum kecamatan, dan (3) perpustakaan umum desa / kelurahan. Perpustakaan umum tersebut milik pemerintah daerah dan dikelola oleh Pemerintah daerah yan gbersangkutan. Tugas dan fungsinya memberikan layanan kepada seluruh lapisan masyarakat, sebagai pusat
informasi, pusat sumber belajar, tempat rekreasi, penelitian, dan pelestarian koleksi bahan pustaka yang dimiliki.
5. Perpustakaan Khusus / Kedinasan
Perpustakaan jenis tersebut berada pada suatu instansi atau lembaga tertentu, baik pemerintah maupun swasta, dan sekaligus sebagai pengelola dan penanggung jawabnya. Tugas pokok nya melayani pemakai dari kantor yan gbersangkutan, sehingga koleksinya juga relative terbatas dan berkaitan dengan misi tugas lembaga yang bersangkutan.
6. Perpustakaan Sekolah
Perpustakaan sekolah merupakan salah satu sarana dan fasilitas penyelenggara pendidikan, sehingga setiap sekolah semestinya memiliki perpustakaan yang memadai. Perpustakaan sekolah merupakan komponen pendidikan yang penting. Tetapi karena berbagai alas an kenyataannya belum setiap sekolah mampu menyediakan perpustakaan sebagaimana diharapkan. Perpustakaan sekolah berada pada lingkungan sekolah, penanggung jawabnya dalah Kepala Sekolah, sedangkan pengelolanya biasanya adalah guru-guru atau pegawai yang ditugaskan. Pembinaan dan pengembangan yang meliputi koleksi, sarana prasarana serta pembiayaan menjadi wewenang dan tanggung jawab Kepala Sekolah. Namun sekolah dapat berkerja sama dengan Komite sekolah dan pihak lain dalam mengelola dan membina perpustakaan tersebut. Pemakainya adalah para pelajar dan guru-guru. Tugas pokok perpustakaan sekolah menunjang proses pendidikan dengan menyediakan bahan-bahan yang sesuai dengan
kurikulum sekolah dan ilmu pengetahuan tambahan yang lain. Tujuannya untuk menunjang agar proses pendidikan dapat berlangsung lancer dan berhasil baik.
7. Perpustakaan Keliling
Pada dasarnya perpustakaan keliling merupakan satu jenis perpustakaan tersendiri. Perpustakaan keliling merupakan jenis layanan yang dikembangkan pada perpustakaan umum, yang disebut Unit Layanan PErpustakaan Kelilng. Maksudnya agar perpustakaan tersebut dapat memberikan layanan berkeliling mendatangi tempat pemukiman penduduk, tempat kegiatan masyarakat seperti sekolah, kantor kelurahan atau tempat-tempat tertentu yang dianggap strategis.
8. Taman Bacaan Rakyat
Taman Bacaan Rakyat atau Taman Bacaan Masyarakat, merupakan salah satu embrio atau cikal bakal jenis perpustakaan umum yang berkembang di Indonesia. Perpustakaan itu telah berkembang sejak lama, dan sampai sekarang masih tetap eksis, meskipun jumlahnya tidak terlalu banyak. Keberadaan taman-taman bacaan rakyat itu dimulai ketika pemerintah mengembangkan perpustakaan umum dengan tipe-tipe tertentu, misalnya tipe A, B dan C,. Perpustakaan-perpustakaan tersebut dimaksudkan untuk mendukung program pemberantasan buta huruf (PBH). Perpustakan yang berbasis pada masyarakat. Taman bacaan secara fisik memang bukan/belum dikatakan perpustakaan, meskipun fungsinya tidak berbeda, yakni sebagai sumber ilmu yang dapat dimanfaatkan oleh setiap orang.
2.3 Teori Penunjang Laporan Tugas Akhir 2.3.1 Konsep Rekayasa Perangkat Lunak
Istilah Rekayasa Perangkat Lunak (RPL) secara umum disepakati sebagai terjemahan dari istilah Software Engineering. Istilah Software Engineering mulai dipopulerkan pada tahun 1968 pada software engineering conference yang diselenggarakan oleh NATO (North Atlantic Treaty Organization).
Pressman dalam bukunya Rekayasa Perangkat Lunak (1997:10) mengatakan :
Rekayasa perangkat lunak adalah (1) perintah program komputer yang bila dieksekusi memberikan fungsi dan unjuk kerja seperti yang diinginkan. (2) struktur data yang memungkinkan program memanipulasi informasi secara proporsional, dan (3) dokumen yang menggambarkan operasi dan kegunaan program (Presman, 1997:10).
Sedangkan menurut wikipedia Indonesia (20013:7) Rekayasa perangkat lunak (RPL, atau dalam bahasa Inggris: Software Engineering atau SE) adalah satu bidang profesi yang mendalami cara-cara pengembangan perangkat lunak termasuk pembuatan, pemeliharaan, manajemen organisasi pengembanganan software dan sebagainya. Sementara itu itu IEEE (Institute of Electrical and Electronic Engineers) mendefinisikan rekayasa perangkat lunak sebagai penerapan suatu pendekatan yang sistematis, disiplin dan terkuantifikasi atas pengembangan, penggunaan dan pemeliharaan perangkat lunak, serta studi atas pendekatan-pendekatan ini, yaitu penerapan pendekatan engineering atas
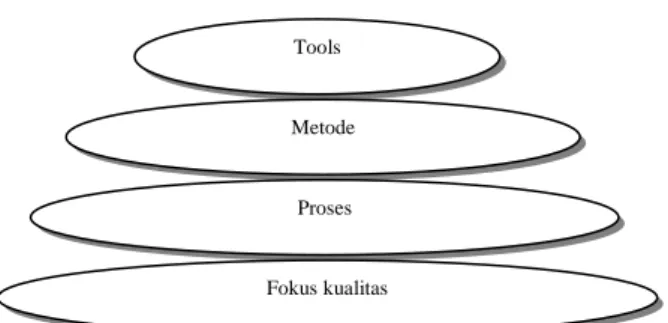
perangkat lunak tertata, mampu untuk dikembangkan, dioperasikan, dirawat dan diperbaiki, itulah sebuah aplikasi software engenering dan mempelajarinya. Gambar 2.4 merupakan lapisan software engginering.
Penjelasan tentang lapisan Software Engineering. a. Proses
Pondasi untuk software engineering adalah lapisan proses. Proses software engineering adalah perekat yang memegang lapisan teknologi bersama-sama dan memungkinkan pengembangan tepat waktu dan masuk akal tentang perangkat lunak komputer. Proses menggambarkan suatu kerangka untuk saru set kunci area pemrosesan (Key Process Area) bahwa harus dibentuk untuk penyerahan yang efektif dari teknologi software engineering. Area kunci pemrosesan membentuk basis bagi manajemen kendali proyek perangkat lunak dan menetapkan konteks dimana metode teknis diterapkan, produk-produk kerja (model, dokumen, data, laporan, format, dll.).
Tools
Metode
Proses
Fokus kualitas
b. Metode
Metode software engineering menyediakan teknis cara untuk membangun perangkat lunak. Metode ini meliputi suatu lirik yang luas tentang tugas yang meliputi analisa persyaratan, desain, konstruksi program, pengujian dan dukungan. Metode software engineering bersandar pada satu set prinsip dasar yang mengurus masing-masing area dari teknologi dan meliputi aktivitas pemodelan dan teknik deskriptif lain.
c. Tools
Software engineering menyediakan dukungan otomatis dan semi otomatis untuk proses dan metode. Kapan tools terintegrasi sedemikan sehingga informasi diciptakan oleh satu alat yang dapat digunakan oleh yang lain. Sistem untuk mendukung pengembangan software, disebut CASE (Case Aided Software Engineering) mengkombinasikan perangkat lunak, perangkat keras, dan basis data database (suatu tempat penyimpanan berisi informasi yang penting tentang analisa, desain, konstruksi program, dan pengujian) untuk menciptakan suatu lingkungan software engineering dapat disamakan ke CAD/CAE (computer-aided-design/engineering) untuk perangkat keras.
Adapun model proses yang digunakan dalam aplikasi perpustakaan sekolah adalah model Prototype. Model prototype dimulai dengan pengumpulan kebutuhan. Pengembang dan pelanggan bertemu dan mendefinisikan obyektif keseluruhan dari perangkat lunak, mengidentifikasi segala kebutuhan yang diketahui, dan area garis besar dalam hal ini definisi lebih jauh merupakan keharusan kemudian dilakukan perancangan kilat. Perancangan kilat berfokus
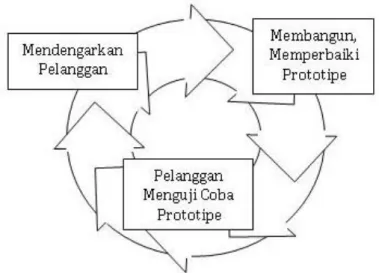
pada penyajian dari aspek-aspek perangkat lunak tersebut yang akan nampak bagi pemakai. Gambar 2.5. merupakan siklus perkembangan perangkat lunak dari model Prototype.
Gambar 2.5 Model Prototype
Gambar 2.5 menunjukan model prototype melewati tiga proses, yaitu pengumpulan kebutuhan, perancangan dan evaluasi prototype. Proses-proses tersebut dapat dijelaskan sebagai berikut :
1. Pengumpulan kebutuhan : pengembang dan user bertemu dan menentukan tujuan umum, kebutuhan yang diketahui dan gambaran bagian-bagian yang akan dibutuhkan berikutnya.
2. Perancangan : perancangan dilakukan cepat dan rancangan mewakili semua aspek software yang diketahui, dan rancangan ini menjadi dasar pembuatan prototype.
3. Evaluasi prototype : user mengevaluasi yang dibuat dan digunakan untuk memperjelas kebutuhan software.
Pada dasarnya ada beberapa keunggulan dan kelemahan pada model proses pengembangan perangkat lunak Prototye yang dikemukakan Dwi Ningsih dalam blog-nya 2012. Berikut keunggulan dan kelemahan dari pengembangan perangkat lunak Prototye.
a. Keunggulan :
1) Adanya komunikasi yang baik antara pengembang dan pelanggan
2) Pengembang dapat bekerja lebih baik dalam menentukan kebutuhan pelanggan
3) Pelanggan berperan aktif dalam pengembangan sistem 4) Lebih menghemat waktu dalam pengembangan sistem
5) Penerapan menjadi lebih mudah karena pemakai mengetahui apa yang diharapkannya
b. Kelemahan :
1) Proses analisis dan perancangan terlalu singkat
2) Ketidaksadaran user bahwa ini hanya suatu model awal bukan model akhir 3) Pengembang terkadang membuat kompromi implementasi dengan
menggunakan system operasi yang tidak relevan dan algoritma yang tidak efisien.
2.3.2 Pemodelan Data
Model dapat digunakan pada proses analisis untuk menggambarkan pemahaman mengenai aplikasi yang akan digantikan atau diperbaiki, atau untuk menspesifikasikan aplikasi yang dibutuhkan.
A. Flow Chart
Flowchart adalah representasi grafik yang menggambarkan setiap langkah yang akan dilakukan dalam suatu proses, yang merupakan alat bantu yang banyak digunakan untuk menggambarkan sistem secara pisikal. Disebut juga Mapping flow atau Process Function chart atau Diagram aliran dokumen atau Diagram Sistem Prosedur Kerja atau Paperwork Flowchart.
Dalam penulisan Flowchart dikenal dua model, yaitu System Flowchart dan Program Flowchart.
1. System Flowchart yaitu : bagan yang memperlihatkan urutan prosedure dan proses dari beberapa file di dalam media tertentu. Melalui flowchart ini terlihat jenis media penyimpanan yang dipakai dalam pengolahan data. Selain itu juga menggambarkan file yang dipakai sebagai input dan output. Tidak digunakan untuk menggambarkan urutan langkah untuk memecahkan masalah. Hanya untuk menggambarkan prosedur dalam sistem yang dibentuk.
2. Program Flowchart yaitu : Bagan yang memperlihatkan urutan dan hubungan proses dalam suatu program dengan menggambarkan alur pemecahan masalah secara rinci
B. Flow Map
Flow map adalah campuran peta dan flow chart yang menunjukan pergerakan benda dari ssatu lokasi ke lokasi lain. Flow map menolong analis dan programmer untuk memecahkan masalah kedalam segmen atau bagian yang lebih
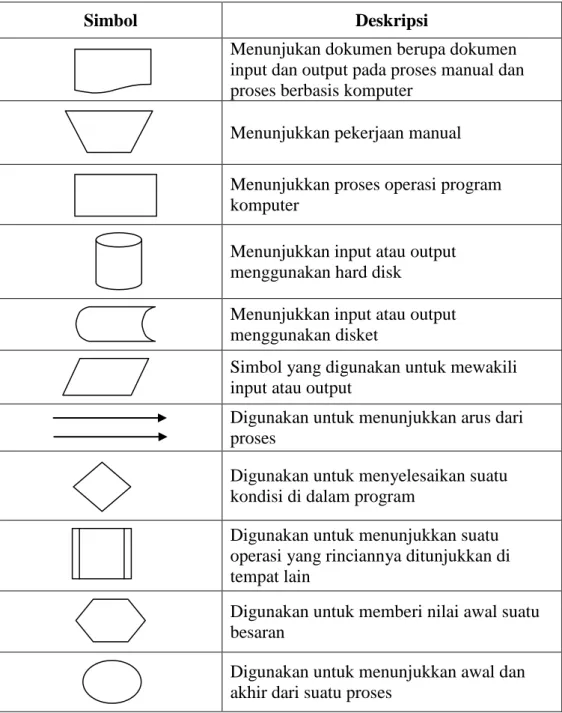
kecil dan menolong dalam menganalisis alternatif-alternatif dalam pengoperasian. Sedangkan untuk simbol yang digunakan dalam flow map sama dengan simbol dalam flow chart, karena flow map adalah bagian dari flow chart. Tabel 2.6 menampilkan simbol-simbol yang terdapat dalam Flow Chart dan Flow Map.
Tabel 2.12 Simbol dan Deskripsi dalam Flow Chart dan Flow Map
Simbol Deskripsi
Menunjukan dokumen berupa dokumen input dan output pada proses manual dan proses berbasis komputer
Menunjukkan pekerjaan manual Menunjukkan proses operasi program komputer
Menunjukkan input atau output menggunakan hard disk
Menunjukkan input atau output menggunakan disket
Simbol yang digunakan untuk mewakili input atau output
Digunakan untuk menunjukkan arus dari proses
Digunakan untuk menyelesaikan suatu kondisi di dalam program
Digunakan untuk menunjukkan suatu operasi yang rinciannya ditunjukkan di tempat lain
Digunakan untuk memberi nilai awal suatu besaran
Digunakan untuk menunjukkan awal dan akhir dari suatu proses
C. Context Diagram
Context diagram adalah Diagram alir data suatu informasi untuk menyampaikan kepada sistem secara interaksi langsung antar pelaku pelaku kegiatan dengan pengaruh faktor luar terhadap input informasi menuju output diinginkan sehingga sistem terlihat secara jelas dan informatif. (Aryafedi, 2008:1). Konteks diagram juga menunjukan semua eksternal entity yang mempunyai hubungan sistem dan aliran data antar entity. Konteks diagram ini termasuk kategori fungsional yang berguna untuk menggambarkan interaksi sistem sebagai blackbox dengan lingkungannya, mendeskripsikan fungsi sebuah sistem.
D. Data Flow Diagram (DFD)
DFD merupakan alat perancangan sistem yang berorientasi pada alur data dengan konsep dekomposisi dapat digunakan untuk penggambaran analisa maupun rancangan sistem yg mudah dikomunikasikan oleh profesional sistem kepada pemakai maupun pembuat program. (Blog, 2011:1).
Data Flow Diagram (DFD) merupakan alat yang digunakan untuk menggambarkan suatu sistem yang telah ada atau sistem baru yang akan dikembangkan secara logika tanpa mempertimbangkan lingkungan fisik dimana data tersebut mengalir ataupun lingkungan fisik dimana data tersebut akan disimpan (Jogiyanto, HM, 2005 :700). Dengan menuangkan hasil analisis ke dalam DFD, seorang analis dapat memahami sistem yang sedang dipelajari
dengan lebih mudah dan lebih baik. Tabel 2.7 menampilkan simbol-simbol yang terdapat dalam Data Flow Diagram (DFD).
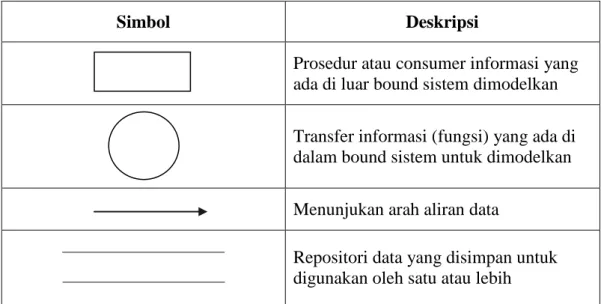
Tabel 2.13 Simbol dan Deskripsi dalam DFD
Simbol Deskripsi
Prosedur atau consumer informasi yang ada di luar bound sistem dimodelkan
Transfer informasi (fungsi) yang ada di dalam bound sistem untuk dimodelkan Menunjukan arah aliran data
Repositori data yang disimpan untuk digunakan oleh satu atau lebih
E. Entity Relationship Diagram (ERD)
ERD merupakan pemodelan data untuk desain sistem database relasional yang mewakili objek data dan hubungan mereka. ERD hanya berfokus pada data dengan menunjukan jaringan data untuk suatu sistem yang diberikan.
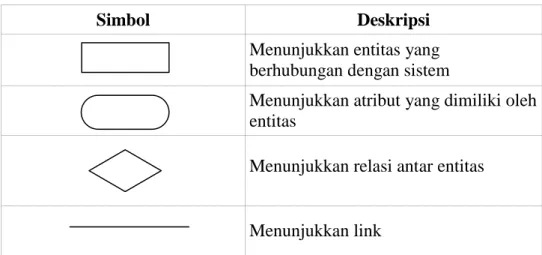
Tabel 2.8. menampilkan komponen-komponen yang ada dalam ERD, yang digambarkan pada tabel berikut.
Tabel 2.14 Simbol dan deskripsi dalam ERD
Simbol Deskripsi
Menunjukkan entitas yang berhubungan dengan sistem
Menunjukkan atribut yang dimiliki oleh entitas
Menunjukkan relasi antar entitas
Menunjukkan link
F. Kamus Data
Kamus data adalah kumpulan dari elemen-elemen atau simbol yang digunakan untuk membantu dalam penggambaran setiap field atau file dalam perangkat lunak. Kamus data (data dictionary) adalah suatu penjelasan tertulis tentang suatu data yang berada di dalam database. Kamus data pertama berbasis kamus dokumen tersimpan dalam suatu bentuk hard copy dengan mencatat semua penjelasan data dalam bentuk yang dicetak. Walau sejumlah kamus berbasis dokumen masih ada, praktik yang umum saat ini ialah mempergunakan kamus data yang berbasis komputer. Pada kamus data berbasis komputer, penjelasan data dimasukkan ke dalam komputer dengan memakai Data Description Language (DDL) dari sistem manajemen database, sistem kamus atau peralatan CASE. Kamus data tidak perlu dihubungkan dengan diagram arus data dan formulir-formulir kamus data dirancang untuk mendukung diagram arus data.
2.3.3 Web Aplikasi
A. Personal Home Page (PHP)
PHP adalah teknologi yang diperkenalkan tahun 1994 oleh Rasmus Lerdorf. Versi pertama digunakan oleh pihak lain pada awal tahun 1995 dan dikenal sebagai personal home page tools. Pada pertengahan 1995 keluarlah PHP/FI Version 2 yang berasal dari kode lain yang ditulis juga oleh Rasmus, yang menterjemahkan HTML dari data. Pada pertengahan 1997, terdapat perubahan di dalam pengembangan PHP. PHP berubah dari proyek pribadi Rasmus menjadi sebuah tim yang lebih terorganisasi. Hal ini diprakarsai oleh Zeev Suraski dan Andi Gutmans, maka keluarlah PHP version 3. banyak kode utilitas yang berasal dari PHP/FI diimport ke PHP3, dan banyak diantaranya sudah selesai ditulis ulang secara lengkap.
PHP (Hypertext Processor) adalah bahasa scripting yang menyatu dengan HTML dan dijalankan pada server side. Artinya semua sintaks yang kita berikan akan sepenuhnya dijalankan pada server sedangkan yang dikirimkan ke browser hanya hasilnya saja. Kode PHP dalam script bisa mengeksekusi query database, memuat gambar, membaca dan menulis file. Berikut merupakan beberapa keunggulan yang dimiliki program PHP diantaranya :
1. PHP memiliki tingkat akses yang lebih cepat. 2. Memiliki tingkat keamanan yang tinggi
3. Mendukung banyak database, antara lain MySQL, Ovrimos, PostgreSQL, SQLite, Solid, Sybase, oracle, informix, mSQL.
4. PHP bersifat gratis.
5. Cross platform, artinya dapat di gunakan di berbagai sistem operasi, mulai dari linux, windows, mac.
PHP mampu diaplikasikan di beberapa server yang ada, misalnya apache, microsoft, phttp, fhttp, dan xitami.
B. Structured Query Language (MySQL)
MySQL adalah sebuah perangkat lunak sistem manajemen basis data SQL (Structured Query Language) yang digunakan untuk mengakses basis data relasional (Relational Database Management System) dan didistribusikan secara gratis dibawah lisensi GPL (General Public License). MySQL sebenarnya merupakan turunan salah satu konsep utama dalam basis data yang telah ada sebelumnya; SQL (Structured Query Language). SQL adalah sebuah konsep pengoperasian basis data terutama untuk pemilihan atau seleksi dan pemasukan data, yang memungkinkan pengoperasian data dikerjakan dengan mudah secara otomatis.
Kehandalan suatu sistem basis data dapat diketahui dari cara kerja pengoptimasi-nya dalam melakukan proses perintah-perintah SQL yang dibuat oleh pengguna maupun program-program aplikasi yang memanfaatkannya.
MySQL memiliki beberapa keistimewaan, antara lain :
1. Portabilitas. MySQL dapat berjalan stabil pada berbagai sistem operasi seperti Windows, Linux, FreeBSD, Mac Os X Server, Solaris, Amiga, dan masih banyak lagi.
2. Open Source. MySQL didistribusikan secara open source, dibawah lisensi GPL sehingga dapat digunakan secara cuma-cuma.
3. Multiuser. MySQL dapat digunakan oleh beberapa user dalam waktu yang bersamaan tanpa mengalami masalah atau konflik.
4. Performance Tuning. MySQL memiliki kecepatan yang menakjubkan dalam menangani query sederhana, dengan kata lain dapat memproses lebih banyak SQL per satuan waktu.
5. Jenis Kolom. MySQL memiliki tipe kolom yang sangat kompleks, seperti signed / unsigned integer, float, double, char, text, date, timestamp, dan lain-lain.
6. Perintah dan Fungsi. MySQL memiliki operator dan fungsi secara penuh yang mendukung perintah Select dan Where dalam perintah (query).
7. Keamanan. MySQL memiliki beberapa lapisan sekuritas seperti level subnetmask, nama host, dan izin akses user dengan sistem perizinan yang mendetail serta sandi terenkripsi.
8. Skalabilitas dan Pembatasan. MySQL mampu menangani basis data dalam skala besar, dengan jumlah rekaman (records) lebih dari 50 juta dan 60 ribu tabel serta 5 milyar baris. Selain itu batas indeks yang dapat ditampung mencapai 32 indeks pada tiap tabelnya.
9. Konektivitas. MySQL dapat melakukan koneksi dengan klien menggunakan protokol TCP/IP, Unix Soket (UNIX), atau Named Pipes (NT).
10. Lokalisasi. MySQL dapat mendeteksi pesan kesalahan pada klien dengan menggunakan lebih dari dua puluh bahasa. Meski pun demikian, bahasa Indonesia belum termasuk di dalamnya.
11. Antar Muka. MySQL memiliki interface (antar muka) terhadap berbagai aplikasi dan bahasa pemrograman dengan menggunakan fungsi API (Application Programming Interface).
12. Klien dan Peralatan. MySQL dilengkapi dengan berbagai tools yang dapat digunakan untuk administrasi basis data, dan pada setiap peralatan yang ada disertakan petunjuk online.
13. Struktur tabel. MySQL memiliki struktur tabel yang lebih fleksibel dalam menangani ALTER TABLE, dibandingkan basis data lainnya.
2.3.4 Database
Database adalah kumpulan data yang saling berhubungan yang disimpan secara bersama sedemikian rupa dan tanpa pengulangan (redudansi) yang tidak perlu, untuk memenuhi berbagai kebutuhan (Fathansyah, 2002:2). Sedangkan model data adalah kumpulan perangkat konseptual untuk menggambarkan data, hubungan data, semantik (makna) data dan batasan data (Fathansyah, 2002:69).
Basis data berdaya ampuh dan membuat aplikasi lebih mudah dipindahkan dalam platform-platform perangkat keras dan sistem operasi yang lain. Menurut Hariyanto (2004:514) keunggulan penggunaan basis data adalah sebagai berikut :
a. Banyak fitur insfrastuktur, seperti crash recovery, sharing antara banyak pemakai, sharing antara banyak aplikasi, distribusi data,
integritas, ekstensibilitas, dukungan transaksi, intrface yang serupa untuk semua aplikasi, dan bahasa pengaksesan yang standar.
b. Interface yang serupa untuk semua aplikasi. c. Bahasa pengaksesan yang standar.
Adapun kelemahan dari penggunaan basis data menurut Hariyanto (2004:514) adalah sebagai berikut:
a. Overhead kinerja yang tinggi.
b. Fungsionalitas yang tak memadai untuk aplikasi-aplikasi lanjut. c. Hubungan antarmuka dan bahasa pemograman yang lemah.
Dalam perancangan database ini digunakan suatu model. Hingga saat ini model database yang paling sering digunakan adalah model relasional, alasannya adalah kemudahan dalam penerapan dan kemampuannya dalam mengakomodasi berbagai kebutuhan pengolahan database yang ada di dunia nyata. Menurut Hariyanto (2004:516) keunggulan lain dari relasional database management system adalah sebagai berikut :
a. Teori dan standar telah disepakati. b. Ketersediaan yang luas.
c. Perluasan konsep-konsep yang terus berlangsung. d. Pengaksesan data secara deklaratif.
e. Kamus data.
f. Query asosiatif yang cepat. g. Keamanan yang bagus.
2.3.5 Pengujian Perangkat Lunak
Pentingnya pengujian perangkat lunak mengacu pada kualitas perangkat lunak yang melibatkan sederetan aktivitas produksi di mana peluang terjadinya kesalahan manusia sangat besar dan karena ketidak mampuan manusia dalam melakukan komunikasi dengan sempurna terhadap kebutuhan yang diinginkan user maka pengembangan perangkat lunak harus diiringi dengan aktivitas jaminan kualitas dengan melakukan pengujian terhadap perangkat lunak tersebut. Pada dasarnya, pengujian merupakan satu langkah dalam proses rekayasa perangkat lunak unuk mencari kesalahan yang terdapat pada perangkat lunak sebelum perangakat lunak tersebut digunakan.
Pengujian yang dilakukan terhadap aplikasi perpustakaan sekolah berbasis web ini ialah menggunakan metode pengujian Black-Box. Pengujian black-box memungkinkan perekayasa perangkat lunak mendapatkan serangakaian kondisi input yang sepenuhnya menggunakan semua persyaratan fungsional untuk suatu program. Pengujian black-box berusaha menemukan kesalahan dalam kategori sebagai berikut :
1. Fungsi-fungsi yang tidak benar atau hilang. 2. Kesalahan interface.
3. Kesalahan dalam struktur data atau akses database. 4. Kesalahan kinerja.