BAB IV
PENGOLAHAN DATA
4.1 Print Output dan Analisa Output A. Diskriminan
Parameter :
1. Grup 1 : Konsumen (responden) yang sering berkunjung ke ...
Grup 2 : Konsumen (responden) yang sering berkunjung ke ...
2. Untuk Wilk’s Lambda
• Apabila nilai Wilk’s Lambda mendekati 0 maka data antar grup cenderung berbeda.
• Apabila nilai Wilk’s Lambda mendekati 1 maka data antar grup cenderung sama.
3. Untuk Signifikan
F value > 3,84 = Ho diterima F value ≤ 3,84 = Ho ditolak 4. Untuk ANOVA
• F hitung < F tabel, maka Ho diterima
Ho : σ12 = σ22 ; maka tiap grup mempunyai varians yang sama (identik)
• F hitung > F tabel, maka Ho ditolak
H1 : σ12 ≠ σ22 ; maka tiap grup mempunyai varians yang berbeda (tidak identik)
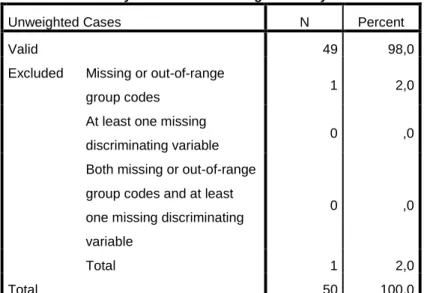
1. Analisis Case Processing Summary
Analysis Case Processing Summary
Unweighted Cases N Percent
Valid 49 98,0
Excluded Missing or out-of-range
group codes 1 2,0
At least one missing
discriminating variable 0 ,0
Both missing or out-of-range group codes and at least one missing discriminating variable
0 ,0
Total 1 2,0
Total 50 100,0
Gambar 4.1 Analisis Case Processing Summary Analisa :
Dalam analisa output dapat dianalisa bahwa data (responden) yang valid sebanyak 49 atau 98% dan ada 1 data (responden) atau 2,0% yang tidak valid yang dibuang dari total 50 data (responden).
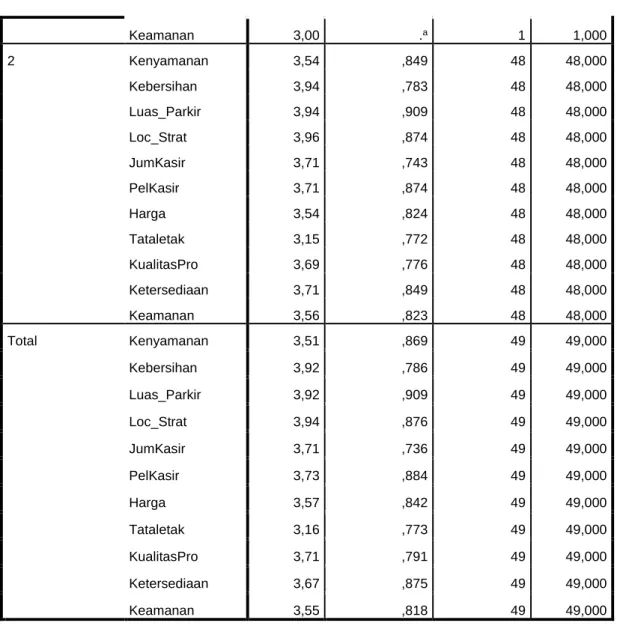
2. Group Statistic
Group Statistics
Average Linkage (Between Groups) Mean Std. Deviation
Valid N (listwise) Unweighted Weighted
1 Kenyamanan 2,00 .a 1 1,000
Kebersihan 3,00 .a 1 1,000
Luas_Parkir 3,00 .a 1 1,000
Loc_Strat 3,00 .a 1 1,000
JumKasir 4,00 .a 1 1,000
PelKasir 5,00 .a 1 1,000
Harga 5,00 .a 1 1,000
Tataletak 4,00 .a 1 1,000
KualitasPro 5,00 .a 1 1,000
Ketersediaan 2,00 .a 1 1,000
Keamanan 3,00 .a 1 1,000
2 Kenyamanan 3,54 ,849 48 48,000
Kebersihan 3,94 ,783 48 48,000
Luas_Parkir 3,94 ,909 48 48,000
Loc_Strat 3,96 ,874 48 48,000
JumKasir 3,71 ,743 48 48,000
PelKasir 3,71 ,874 48 48,000
Harga 3,54 ,824 48 48,000
Tataletak 3,15 ,772 48 48,000
KualitasPro 3,69 ,776 48 48,000
Ketersediaan 3,71 ,849 48 48,000
Keamanan 3,56 ,823 48 48,000
Total Kenyamanan 3,51 ,869 49 49,000
Kebersihan 3,92 ,786 49 49,000
Luas_Parkir 3,92 ,909 49 49,000
Loc_Strat 3,94 ,876 49 49,000
JumKasir 3,71 ,736 49 49,000
PelKasir 3,73 ,884 49 49,000
Harga 3,57 ,842 49 49,000
Tataletak 3,16 ,773 49 49,000
KualitasPro 3,71 ,791 49 49,000
Ketersediaan 3,67 ,875 49 49,000
Keamanan 3,55 ,818 49 49,000
a. Insufficient data
Gambar 4.2 Group Statistic Analisa :
Total group statistik pada dasarnya berisi data statistik deskriptif yang utama, yakni rata-rata dan standard deviasi, dari kedua group. Dari tabel juga terlihat ada 1 responden yang tergolong group 1. Dan sisanya sebanyak 48 responden yang tergolong group 2. Jika melihat semua variabel (Kenyamanan, kebersihan...) yang muncul ini berarti tidak ada variabel yang hilang yakni ada 11 variabel.
3. Analisa Test Of Equality Of Goup Means
Tests of Equality of Group Means
Wilks' Lambda F df1 df2 Sig.
Kenyamanan ,936 3,226 1 47 ,079
Kebersihan ,971 1,404 1 47 ,242
Luas_Parkir ,978 1,043 1 47 ,312
Loc_Strat ,976 1,177 1 47 ,283
JumKasir ,997 ,151 1 47 ,699
PelKasir ,956 2,139 1 47 ,150
Harga ,939 3,068 1 47 ,086
Tataletak ,975 1,201 1 47 ,279
KualitasPro ,944 2,801 1 47 ,101
Ketersediaan ,922 3,962 1 47 ,052
Keamanan ,990 ,458 1 47 ,502
Gambar 4.3 Analisa Test Of Equality Of Goup Means Analisa:
V1 = df1 = 1 V2 = df2 = 47
Didapatkan Ftabel = 4,05 a. Kenyaman
Nilai Wilk’s Lambda 0,935 mendekati 1 artinya data tiap group cenderung sama. Nilai Fhitung < Ftabel = 3,226 < 4,05 yang artinya H0 ditolak, maka data group mempunyai varians yang berbeda ( tidak identik). Nilai Sig. 0,079 >
0,05 yang artinya H0 ditolak, maka ada perbedaan antar group.
b. ( IDEM )
B. Stepwise
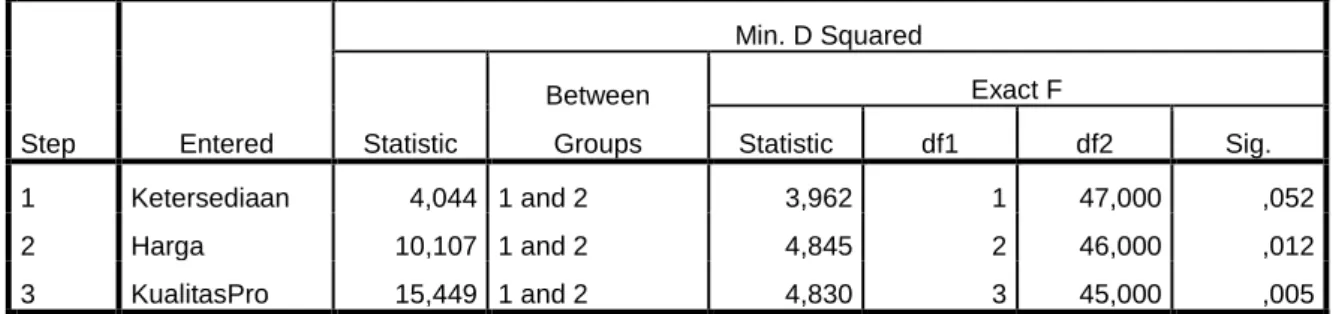
1. Variables Entered / Removed
Variables Entered/Removeda,b,c,d
Step Entered
Min. D Squared
Statistic
Between Groups
Exact F
Statistic df1 df2 Sig.
1 Ketersediaan 4,044 1 and 2 3,962 1 47,000 ,052
2 Harga 10,107 1 and 2 4,845 2 46,000 ,012
3 KualitasPro 15,449 1 and 2 4,830 3 45,000 ,005
At each step, the variable that maximizes the Mahalanobis distance between the two closest groups is entered.
a. Maximum number of steps is 22.
b. Minimum partial F to enter is 3.84.
c. Maximum partial F to remove is 2.71.
d. F level, tolerance, or VIN insufficient for further computation.
Gambar 4.4 Variables Entered / Removed Analisa :
Berdasarkan tabel output diatas variabel (Ketersediaan, Harga, KualitasPro) memiliki angka Sig di bawah 0,05. Dengan demikian dari ke 11 variabel yang dimasukkan, hanya ada 3 variabel yang signifikkan. Atau bisa di katakan variabel (Ketersediaan, harga, Kualitas Pro) mempengaruhi keputusan konsumen untuk berkunjung.
2. Variables Not In The Analysis
Variables Not in the Analysis
Step Tolerance Min. Tolerance F to Enter Min. D Squared
Between Groups
0 Kenyamanan 1,000 1,000 3,226 3,294 1 and 2
Kebersihan 1,000 1,000 1,404 1,434 1 and 2
Luas_Parkir 1,000 1,000 1,043 1,064 1 and 2
Loc_Strat 1,000 1,000 1,177 1,202 1 and 2
JumKasir 1,000 1,000 ,151 ,154 1 and 2
PelKasir 1,000 1,000 2,139 2,183 1 and 2
Harga 1,000 1,000 3,068 3,132 1 and 2
Tataletak 1,000 1,000 1,201 1,226 1 and 2
KualitasPro 1,000 1,000 2,801 2,860 1 and 2
Ketersediaan 1,000 1,000 3,962 4,044 1 and 2
Keamanan 1,000 1,000 ,458 ,467 1 and 2
1 Kenyamanan ,883 ,883 1,274 5,485 1 and 2
Kebersihan ,664 ,664 ,001 4,046 1 and 2
Luas_Parkir ,972 ,972 ,436 4,537 1 and 2
Loc_Strat ,976 ,976 ,557 4,674 1 and 2
JumKasir ,983 ,983 ,390 4,485 1 and 2
PelKasir ,999 ,999 1,773 6,049 1 and 2
Harga ,915 ,915 5,361 10,107 1 and 2
Tataletak ,932 ,932 2,527 6,903 1 and 2
KualitasPro 1,000 1,000 2,457 6,823 1 and 2
Keamanan 1,000 1,000 ,423 4,522 1 and 2
2 Kenyamanan ,839 ,839 2,508 13,343 1 and 2
Kebersihan ,628 ,628 ,307 10,502 1 and 2
Luas_Parkir ,867 ,817 1,981 12,664 1 and 2
Loc_Strat ,922 ,864 1,551 12,109 1 and 2
JumKasir ,967 ,900 ,097 10,231 1 and 2
PelKasir ,906 ,830 ,376 10,592 1 and 2
Tataletak ,920 ,843 3,026 14,012 1 and 2
KualitasPro ,944 ,864 4,139 15,449 1 and 2
Keamanan ,997 ,913 ,246 10,424 1 and 2
3 Kenyamanan ,823 ,810 3,169 20,017 1 and 2
Kebersihan ,589 ,589 ,002 15,453 1 and 2
Luas_Parkir ,864 ,769 2,075 18,440 1 and 2
Loc_Strat ,868 ,792 2,868 19,584 1 and 2
JumKasir ,958 ,846 ,012 15,467 1 and 2
PelKasir ,890 ,772 ,108 15,605 1 and 2
Tataletak ,554 ,554 ,308 15,894 1 and 2
Keamanan ,941 ,854 ,000 15,449 1 and 2
Gambar 4.5 Variables Not In The Analysis Analisa:
Tabel ini adalah kebalikan dari tabel sebelumnya, dimana tabel ini justru yang di tayangkan adalah proses pengeluaran variabel secara bertahap.
a. Pada step 0 (keadaan awal) ke-11 variabel secara lengkap di tayangkan dengan angka F to Enter sebagai faktor penguji. Terlihat angka F to Enter yang terbesar adalah variabel ketersediaan angka 3,962. Berdasarkan Min D Squared paling tinggi dari signifikan >0,05 maka variabel ketersediaan dikeluarkan dari step 0 untuk dianalisa lebih lanjut dalam model diskriminan.
b. Pada step 1, sekarang terlihat hanya ada 10 variabel, dan terlihat ke 10 variabel tersebut yang mempunyai angka F to Enter tertinggi adalah Harga (5,361) dan Min D Squared tertinggi (10,107) maka variabel Harga dikeluarkan dari step 1 untuk dianalisa lebih lanjut dalam model diskriminan.
c. ( IDEM )
3. Wilks` Lambda
Wilks' Lambda
Step
Number of Variables
Lambd
a df1 df2 df3
Exact F
Statistic df1 df2 Sig.
1 1 ,922 1 1 47 3,962 1 47,000 ,052
2 2 ,826 2 1 47 4,845 2 46,000 ,012
3 3 ,756 3 1 47 4,830 3 45,000 ,005
Gambar 4.6 Wilks` Lambda Analisa :
Wilk’s Lambda pada prinsipnya adalah varians total dalam diskriminan scores yang tidak bisa dijelaskan oleh perbedaan diantara grup-grup yang ada. Perhatikan tabel diatas yang terdiri dari 3 tahap (step) yang terkait dengan 3 variabel secara berurutan dimasukan pada tahapan analisa sebelumnya. Dengan nilai varians 92,2%, 82,6% dan 75,6% Dari kolom F dan signifikansi, terlihat baik pada pemasukan variabel 1, 2 dan 3 adalah signifikansi secara statistik. Dengan nilai Sig.
< 0,05 hal ini berarti terdapat perbedaan yang signifikan antara kelompok yang sering dengan yang jarang berkunjung.
C. Summary Of Caninical Discriminan 1. Eigenvalues
Eigenvalues
Function Eigenvalue % of Variance Cumulative %
Canonical Correlation
1 ,322a 100,0 100,0 ,494
a. First 1 canonical discriminant functions were used in the analysis.
Gambar 4.7 eigenvalues
Analisa :
Canonical Correlation mengukur keeratan hubungan antara diskriminan score dengan grup. Angka 0,494 menunjukkan keeratan yang cukup tinggi, dengan ukuran skala asosiasi antara 0 sampai 1.
2. Lambda
Wilks' Lambda
Test of Function(s) Wilks' Lambda Chi-square df Sig.
1 ,756 12,701 3 ,005
Gambar 4.8 Lambda Analisa :
Tabel tersebut menyatakan angka akhir Wilk’s Lambda, yang sebenarnya sama saja dengan angka terakhir dari step 2 pembuatan model diskriminan.
Angka Chi-Square sebesar 12,701 dengan tingkat signifikansi yang kurang dari 0,05 tidak menunjukkan perbedaan yang jelas.
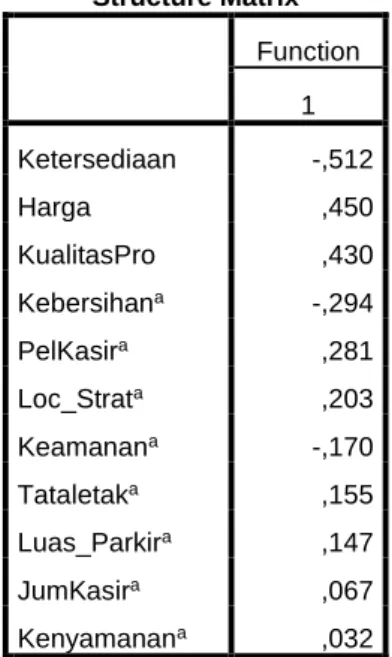
4. Structure Matrix
Structure Matrix Function
1 Ketersediaan -,512
Harga ,450
KualitasPro ,430
Kebersihana -,294
PelKasira ,281
Loc_Strata ,203
Keamanana -,170
Tataletaka ,155
Luas_Parkira ,147
JumKasira ,067
Kenyamanana ,032
Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions Variables ordered by absolute size of correlation within function.
a. This variable not used in the analysis.
Gambar 4.9 structure matrix Analisa :
Tabel structure matrix menjelaskan korelasi antara variabel independen dengan fungsi diskriminan yang terbentuk. Terlihat Kebersihan,... tidak termasuk dalam model deskriminan.
Sedangkan ketersediaan dan Harga dan kualitas pro termasuk dalam model diskriminan.
5. Canonical Discriminan Function Coefficients
Canonical Discriminant Function Coefficients
Function 1
Harga ,975
KualitasPro ,780
Ketersediaan -,869 (Constant) -3,186 Unstandardized coefficients
Gambar 4.10 Canonical Discriminan Function Coefficients Analisa :
Tabel di atas mempunyai fungsi yang hampir mirip dengan persamaan regresi ganda, yang dalam analisis diskriminan disebut sebagai fungsi diskriminan. Z Score = -3,186 + 0,975 Harga + 0,780 Kualitas Pro + ( - 0,869 ) Ketersediaan Kegunaan fungsi tersebut untuk mengetahui sebuah case ( dalam kasus ini TEMPAT KALIAN ) masuk pada grup satu, ataukah tergolong pada grup lainnya. Selain fungsi di atas, dengan di pilihnya Fisher Function Coefficient pada proses analisis, maka akan terbentuk pula fungsi diskriminan Fisher.
6. Functions At Group Centroids
Functions at Group Centroids
Average Linkage (Between Groups)
Function 1
1 3,850
2 -,080
Unstandardized canonical discriminant functions evaluated at group means
Gambar 4.11 Functions At Group Centroids
Analisa :
Karena ada dua tipe keputusan, maka disebut Two-Group Discriminant, dimana grup yang satu mempunyai centroid (group means) Positif, dan grup yang satu mempunyai centroid (group means) negatif. Angka pada tabel menunjukkan besaran ”Z” memisahkan kedua grup tersebut.
D. Clasification
1. Classification Processing Summary
Classification Processing Summary
Processed 50
Excluded Missing or out-of-range group
codes 0
At least one missing
discriminating variable 0
Used in Output 50
Gambar 4.12 Classification Processing Summary Analisa :
Dari tabel di atas menyatakan bahwa terdapat 50 data yang telah diproses tanpa ada data yang hilang dan semua data digunakan dalam output.
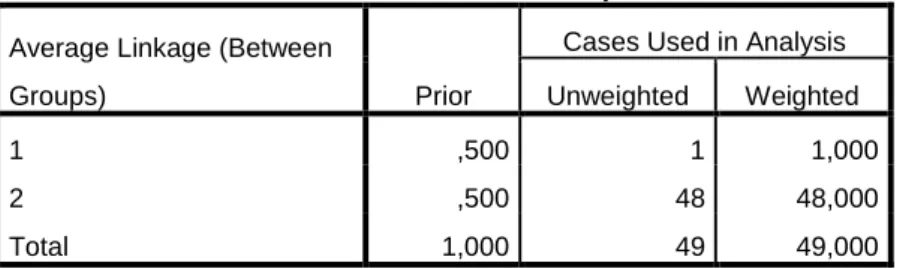
2. Prior Probabillities For Groups
Prior Probabilities for Groups
Average Linkage (Between
Groups) Prior
Cases Used in Analysis Unweighted Weighted
1 ,500 1 1,000
2 ,500 48 48,000
Total 1,000 49 49,000
Gambar 4.13 Prior Probabillities For Groups
Analisa :
Terlihat distribusi anggota grup, memperlihatkan komposisi dimana dari 49 responden yang dengan model diskriminan menghasilkan 48 orang ada pada grup 2 (responden yang jarang berkunjung), dan 1 orang yang ada pada grup 1 (responden yang berkunjung).
3. Casewise Statistic
Gambar 4.14 Casewise Statistic Analisa :
Tabel output casewise di atas pada prinsipnya ingin menguji apakah model diskriminan yang terbentuk akan mengelompokkan dengan tepat seorang pengunjung “...” pada kategori 1 atau 2.
4. Clasification Results
Classification Resultsa,c
Average Linkage (Between Groups)
Predicted Group Membership
Total
1 2
Original Count 1 1 0 1
2 2 46 48
Ungrouped cases 0 1 1
% 1 100,0 ,0 100,0
2 4,2 95,8 100,0
Ungrouped cases ,0 100,0 100,0
Cross-validatedb Count 1 0 1 1
2 2 46 48
% 1 ,0 100,0 100,0
2 4,2 95,8 100,0
a. 95,9% of original grouped cases correctly classified.
b. Cross validation is done only for those cases in the analysis. In cross validation, each case is classified by the functions derived from all cases other than that case.
c. 93,9% of cross-validated grouped cases correctly classified.
Gambar 4.15 Clasification Results Analisa :
Setelah fungsi diskriminan dibuat, kemudian klasifikasi dilakukan, maka selanjutnya akan dilihat seberapa jauh klasifikasi tersebut sudah tepat atau, berapa persen terjadi misklasifikasi pada proses klasifikasi tersebut, yang akan dijelaskan melalui tabel di atas. Pada bagian original, terlihat bahwa mereka yang pada data awal tergolong kategori 1 dan 2 adalah tetap dan tidak ada perpindahan (misklasifikasi). Dengan 0 data yang tidak masuk dalam proses diskriminan. Ketepatan prediksi dalam model ini adalah 100%. Maka model dsikriminan di atas sebenarnya bisa digunakan untuk analisis diskriminan karena ketepatan mencapai 100%.