KLASIFIKASI MIKROBA DENGAN METODE TAKSONOMI NUMERIK
Oleh :
Nama : Athoullah
NIM : B1J013121
Rombongan : I
Kelompok : 6
Asisten : Tedi Septiadi
LAPORAN PRAKTIKUM SISTEMATIKA MIKROBA
KEMENTERIAN RISET, TEKNOLOGI, DAN PENDIDIKAN TINGGI UNIVERSITAS JENDERAL SOEDIRMAN
FAKULTAS BIOLOGI PURWOKERTO
I. PENGANTAR
A. Latar Belakang
Pengenalan penggunaan komputer di bidang mikrobiologi membawa dampak yang besar dalam taksonomi mikroba terutama dalam perkembangan taksonomi numerik. Taksonomi numerik merupakan metode yang digunakan dalam proses klasifikasi dan identifikasi mikroba dengan membandingkan strain-strain mikroba berdasarkan sejumlah besar karakter berbeda. Semakin dekat hubungan suatu mikroba, karakter-karakter yang dimilikinya juga akan sama (Heritage et al., 1996).
Karakter-karakter yang biasa digunakan adalah karakterbiokimiawi seperti kemampuan menghasilkan asam dari karbohidrat dan reduksi nitrat, karakter kultural seperti morfologi koloni dan pigmentasi, karakter morfologis seperti bentuk sel, reaksi pewarnaan dan motilitas, karakter nutrisional seperti sumber karbon, dan karakter fisiologis seperti temperatur pertumbuhan (Lengeler et al., 1999).
Aplikasi taksonomi numerik dalam konstruksi klasifikasi biologis memungkinkan terwujudnya sirkumskripsi takson berdasarkan prinsip yang mantap dan bukan sekedar klasifikasi yang bersifat subyektif (Sembiring, 2004). Urutan tahapan teknik klasifikasi numerik meliputi empat tahap yaitu:
1. Strain mikroba (n) yang akan diklasifikasikan dikoleksi lalu ditentukan karakter fenotipiknya dalam jumlah besar (r) yang mencakup sifat biokimiawi, morfologis, nutritional, dan fisiologis. Data yang diperoleh disusun dalam suatu matriks n x t.
2. Strain mikroba diklasifikasikan berdasarkan nilai similaritas atau disimilaritas yang dihitung dari data matriks n x t.
3. Strain yang mirip akan dimasukkan ke dalam sutu kelompok dengan menggunakan algoritma pengklasteran (clustring algoritm).
4. Kelompok yang dibentuk secara numerik kemudian dipelajari dan karakter yang bersifat membedakan (separating character) dipilih diantara data dalam matriks untuk selanjutnya digunakan dalam identifikasi.
Taksonomi numerik juga dikenal sebagai taksonomi Adansonian yang didasarkan atas lima prinsip utama yaitu:
2. Masing-masing karakter diberi nilai yang setara dalam mengkonstruksi takson yang bersifat alami.
3. Tingkat kedekatan antara dua strain (OTU: operational taxonomical unit) merukapan fungsi proporsi similaritas sifat yang dimiliki bersama.
4. Taksa yang berbeda dibentuk berdasarkan atas sifat yang dimiliki. 5. Similaritas tidak bersifat filogenetis melainkan bersifat fenetis.
II. BAHAN DAN CARA KERJA
A. Bahan dan alat
Bahan dan alat yang digunakan dalam praktikum ini antara lain publikasi (jurnal) ilmiah tentang klasifikasi numerik-fenetik, dan komputer yang memiliki program Excell, PFE, MVSP, Paintshop Pro, dan Words.
B. Prosedur kerja
1. Koleksi data
Data karakter yang digunakan dalam praktikum ini mengacu pada publikasi ilmiah terkait dengan penggunaan taksonomi numerik yang dapat diakses melalui internet. Semua data unit karakter selanjutnya dimasukkan ke dalam matriks n x t.
2. Penghitungan nilai similaritas
Untuk mengetahui tingkat kemiripan antar strain mikroba (OTU), masing-masing strain dibandingkan dengan strain yang lain dengan menggunakan dua cara yaitu Simple Matching Coeficient (SSM) dan Jaccard Coeficient (SJ) dengan rumus :
( a + d ) a
SSM = --- x 100% SJ = --- x 100% ( a + b + c + d ) ( a + b + c )
Keterangan :
a : jumlah karakter yang (+) untuk kedua strain
b : jumlah karakter yang (+) untuk strain pertama dan (-) bagi strain kedua c : jumlah karakter yang (-) untuk strain pertama dan (+) bagi strain kedua d : jumlah karakter yang (-) untuk kedua strain.
3. Konstruksi dendrogram dengan analisis komputer
Data karakter fenotipik yang telah diberi skor (+) atau (-) dimasukkan ke dalam komputer dengan menggunakan program Excell. Data selanjutnya dicopykan ke dalam program PFE (Programmer File Editor), selanjutnya data (+) dikonversikan menjadi 1 dan data (-) dikonversikan menjadi 0. Data tersebut kemudian diolah dalam program MVSV untuk mengkonstruksikan dendogram yang mencerminkan klasifikasi OTU berdasarkan nilai indeks similaritas (SSM) dan (SJ) dengan algoritma UPGMA.
3.2. Presentasi hasil klasifikasi
Dendrogram yang dihasilkan oleh analisis klaster (cluster) dalam program MVSP selanjutnya di insert ke dalam file dokumen dalam program WORDS (file teks).
3.3. Penentuan struktur taksonomis (deteksi phena)
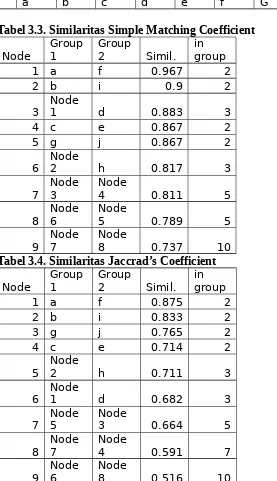
Penentuan struktur taksonomis yang digambarkan oleh dendrogram mengacu pada aturan standar yaitu bahwa pendefinisian fena dengan tingkat similaritas > 70%.
Prosedur Operasi Program Komputer
1. Pemasukkan data unit karakter ke dalam matriks n x t
Buka program Excell
Buka file baru (click new)
Label OTU diketikkan pada kolom (sejumlah strain uji n)
Label unit karakter diketikkan pada baris (row) sebanyak karakter uji (t)
Masing-masing nilai (+) atau (-) dimasukkan pada cell yang sesuai
Matriks n x t selesai disusun, selanjutnya dicopykan ke PFE dengan cara meng highlight seluruh matriks dan kemudian click copy
Program Excell diminimize.
2. Preparasi data dalam matriks n x t dengan program PFE
Program PFE dibuka
File baru dibuka dan click new
Click paste untuk mengkopikan file data yang dari Excell
Pada baris pertama ketik: *L t n Nama Data yang dianalisis
Selanjutnya data dirapikan supaya lurus dalam baris dan kolom dengan jarak satu spasi
Save file dalam format *.mvs dalam direktori MVSP, kemudian PFE diminimize.
3. Analisis data dengan MVSP untuk mengkonstruksi matriks similaritas dan dendrogram
Program MVSP dibuka
Select Cluster Analysis, Ketik ? (Enter)
Select file name pattern: *.mvd (Enter)
Select M (Clustring method: Default UPGMA)
Select R (Run Analysis)
Enter output file name: *.OT2 (matrix similarity dan clustring steps) (Enter)
Enter tree description file name: *.plg (Enter)
(Cluster Analysis) !
Finish ! Press any key
III.HASIL DAN PEMBAHASAN
A. Hasil
Tabel 3.1. Matriks Similaritas Simple Matching Coefficient Similarity matrix
a b c d e f G h i j
Tabel 3.3. Similaritas Simple Matching Coefficient
Node Group1 Group2 Simil. in group Tabel 3.4. Similaritas Jaccrad’s Coefficient
Node Group1 Group2 Simil. in group
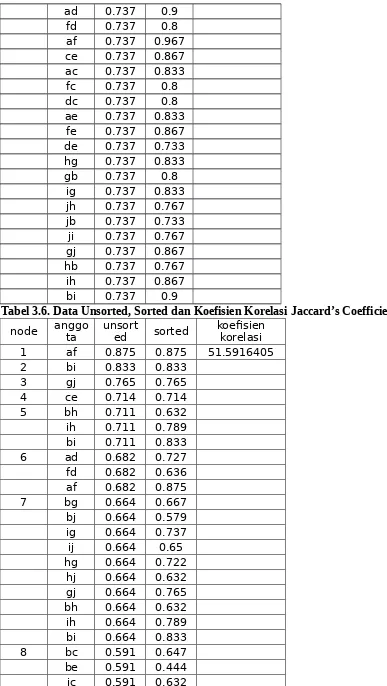
node anggota unsorted sorted koefisienkorelasi
1 af 0.967 0.967 53.96483084
ad 0.737 0.9
Tabel 3.6. Data Unsorted, Sorted dan Koefisien Korelasi Jaccard’s Coefficient node anggota unsorted sorted koefisienkorelasi
1 af 0.875 0.875 51.5916405
UPGMA
Jaccard's Coefficient
a
f
d
b
i
h
g
j
c
e
B. Pembahasan
DAFTAR REFERENSI
Heritage J, Evans E.G.V, and Killington R.A.. 1996. Introductory Microbiology. Cambridge University Press.
Kovach, W.L. 1990. MVSP Plus Version 2.0. User Manual.
Lengeler J.W, G. Drews, and H.G. Schlegel.. 1999. Biology of the Prokaryotes. Blackwell Science, New York.
Maugeri T.L., Gugliandolo C.,Caccamo D., Stackebrandt E.. 2001. A polyphasic taxonomic study of Thermophilic Bacilli from Shallow, Marine Vents. Systematic and Applied Microbiology 24: 572-587.
Priest F., and Austin B.. 1993. Modern Bacterial Taxonomy. Second edition. Chapman & Hall, United Kingdom.