Pada tahun 2021 terdapat 95 lomba referensi dan buku teks yang masing-masing berisi 75 buku referensi dan 20 judul buku teks. Lomba Buku Ajar dan Referensi Tahun 2021 berorientasi pada interkoneksi-integrasi agama dan ilmu pengetahuan, dengan semangat Cakrawala Ilmu UIN Mataram dengan ilmu inter multi-transdisipliner yang berdialog dengan metode dalam kajian Islam konvensional. Buku yang dilombakan dan diterbitkan pada tahun 2021 adalah 75 buku referensi dan 20 buku ajar untuk dosen.
Penggolongan Statistika
Statistik parametrik adalah statistik yang mengetahui atau memerlukan asumsi tentang sebaran penduduk, misalnya sebaran normal atau sebaran lainnya.
Peranan Statistika
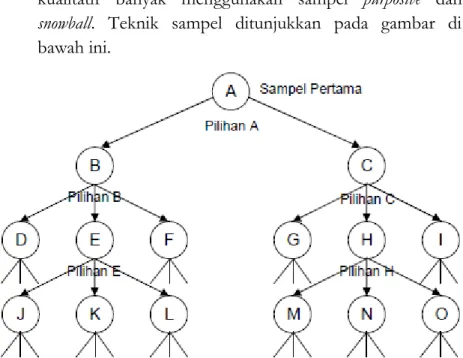
Populasi dan Sampel
Margono menyatakan sampel adalah sebagian dari populasi, sebagai contoh sampel yang diambil dengan menggunakan metode tertentu. Margono menyatakan simple sampling adalah teknik pengambilan sampel yang dilakukan secara langsung pada unit pengambilan sampel. Dengan banyak sampel, kemampuan untuk memasukkan data sebanyak jumlah sampel yang ditentukan tidak mungkin dilakukan.

- Jenis-jenis Data
- Metode Pengumpulan Data
- Skala yang Digunakan dalam Kuesioner
- Variabel
Data interval, yaitu data yang nilainya bersifat numerik tetapi tidak dapat dihubungan satu sama lain. Data relasional yaitu data yang nilainya bersifat numerik dan dapat dijatah satu sama lain. Data yang diperoleh merupakan data interval dan biasanya skala ini digunakan untuk mengukur sikap/karakteristik tertentu yang dimiliki seseorang.
Distribusi Frekuensi
Tujuan pembuatan tabel distribusi frekuensi adalah untuk menata data mentah (data yang dikelompokkan) ke dalam bentuk yang rapi tanpa mengurangi informasi inti yang ada. Pembuatan tabel distribusi frekuensi dapat dimulai dengan menyusun data mentah secara sistematis (dari nilai terkecil ke nilai terbesar atau sebaliknya) atau lebih sering disebut data terurut. Data yang disusun dalam bentuk distribusi frekuensi dapat disusun dalam bentuk distribusi lainnya yaitu distribusi frekuensi kumulatif dan proporsi.
Ukuran Pemusatan Data
Modus adalah kriteria yang digunakan untuk menentukan suatu fenomena yang terjadi atau paling sering terjadi. Untuk data kualitatif (data dengan tingkat pengukuran minimal nominal), sering kali digunakan modus sebagai pengganti mean. Sedangkan untuk data kuantitatif, modusnya diperoleh dengan menentukan frekuensi tertinggi di antara serangkaian data.
Hitung mean aritmatika data pengeluaran harian (ribu rupee) untuk 30 keluarga pada daftar frekuensi di bawah ini. Tb = tepi bawah kelas median, yaitu kelas yang terletak di mana median berada, yaitu pada jumlah frekuensi sama dengan setengah jumlah data. F = banyaknya frekuensi sebelum kelas menengah (frekuensi kumulatif). fMe = frekuensi rata-rata kelas Contoh 4.7. Untuk data pengeluaran harian 30 KK, hitung mediannya. ribu Rp) f Kelas tepi bawah F.
Artinya 50% keluarga dengan pengeluaran harian tertinggi sebesar Rp69,30 dan 50% keluarga lainnya dengan pengeluaran harian terendah sebesar Rp69,30.

Ukuran Penyebaran Data
Budi mendapat nilai 83 pada ujian akhir semester mata pelajaran statistika yang rata-rata kelasnya 75 dan simpangan baku 12. Sedangkan pada semester akhir mata pelajaran kalkulus yang rata-rata kelasnya 83 dan simpangan baku 16 ia mendapat nilai 83 90. Artinya, Budi memperoleh standar deviasi sebesar 0,6667 di atas nilai rata-rata mata pelajaran statistika, dan hanya 0,4375 standar deviasi di atas nilai rata-rata mata pelajaran statistika.
Karena nilai standar mata kuliah statistika lebih tinggi dibandingkan nilai standar mata kuliah kalkulus, maka pada mata kuliah statistika, Budi mendapat peringkat yang lebih tinggi.

Kesalahan dalam Uji Hipotesis
Untuk menguji hipotesis dalam penelitian yang menggunakan sampel acak, harus dihitung nilai statistiknya kemudian dibandingkan dengan beberapa kriteria berdasarkan hipotesis nol. Kesalahan tipe III tidak banyak ditemukan dan hal ini mengakibatkan pemecahan masalah yang tidak perlu sementara masalah sebenarnya masih belum terpecahkan. Kesimpulan apapun yang diambil dari hasil percobaan ini tidak akan menyelesaikan masalah, karena adanya kesalahan dalam perumusan hipotesis.
Kesalahan tipe III (ketiga) tidak dimasukkan dalam tabel 5.2, karena kesalahan tipe I dan II dipertimbangkan dengan asumsi hipotesis yang dirumuskan sesuai dengan masalah dan tujuan yang ingin dicapai. Jika kesalahan tipe ketiga terjadi, tidak ada gunanya membahas kesalahan tipe I dan tipe II karena pengujian itu sendiri tidak diperlukan dan tidak ada gunanya. Kesalahan Tipe II Keputusan yang Benar Saat menguji hipotesis dalam suatu penelitian, kemungkinan terjadinya kedua jenis kesalahan ini harus dibuat sekecil mungkin.
Peluang terjadinya kesalahan tipe I biasanya dinyatakan dengan α (baca: alpha), dan peluang terjadinya kesalahan tipe II dinyatakan dengan β (baca: beta). Misalnya, seorang dokter ingin menguji apakah dosis obat yang biasa (50 mg) masih sesuai dengan situasi dan keadaan saat ini. Jika pasangan hipotesis di atas diuji, maka kesimpulan yang dapat diambil mungkin menerima atau menolak H0.
Kedua jenis kesalahan tersebut memiliki risiko serius yang sama, sehingga α dan β harus dijaga sekecil mungkin dalam pengujian, sehingga diperlukan langkah praktis dalam pengujian hipotesis.
Langkah-langkah Pengujian Hipotesis
Dalam hal ini, dokter tetap menggunakan dosis yang sama padahal penyakitnya memerlukan dosis yang lebih tinggi. Misalnya, α = 0,01, dalam teori probabilitas, kira-kira. 1 dari 100 kesimpulan yang menolak H0 benar-benar diterima. Perhitungan ini dilakukan dengan mengganti variabel acak dalam statistik dengan nilai observasi yang diperoleh.
Arah Pengujian Hipotesis
Seorang pakar Sumber Daya Manusia menguji 25 karyawan dan menemukan bahwa rata-rata masa kerja sekretaris adalah 22 bulan dengan standar deviasi = 4 bulan. Pada tingkat signifikansi 5%, uji apakah terdapat perbedaan rata-rata prestasi kerja antara kedua kelompok karyawan? Uji hipotesis selisih 2 mean dari sampel kecil Misalkan varians kedua populasi tidak sama (σ12 ≠ σ22) dan nilainya tidak diketahui.
Berikut data rata-rata jumlah hari absen pegawai (hari/tahun) pada dua divisi berbeda. Diasumsikan kedua sampel tersebut diambil dari dua populasi yang variansnya tidak sama dan tidak diketahui nilainya. Pada tingkat signifikansi 5%, apakah selisih rata-rata jumlah membolos pada kedua divisi 12 lebih dari 5 hari per tahun?
Pada taraf signifikansi 5%, ujilah apakah selisih persentase mahasiswa yang aktif berorganisasi pada kedua fakultas tersebut kurang dari 30%? H0 ditolak, H1 diterima: selisih persentase populasi mahasiswa yang aktif berorganisasi di kedua fakultas kurang dari 30%.

Uji Kolmogorov-Smirnov
Padahal, secara umum uji Kolmogorov-Smirnov digunakan untuk memeriksa apakah data sampel tertentu berasal dari populasi dengan distribusi probabilitas teoritis tertentu. Jadi tidak tepat jika dikatakan bahwa pengujian ini hanya untuk menguji apakah suatu populasi berdistribusi normal atau tidak. Salah juga jika mengatakan bahwa satu-satunya cara untuk menguji normalitas adalah uji Kolmogorov-Smirnov.
Pengujian ini mengasumsikan bahwa distribusi yang mendasari variabel yang diuji adalah kontinu, sebagaimana dinyatakan dalam distribusi frekuensi kumulatif. Apakah terdapat cukup bukti yang menyatakan bahwa sampel tidak berasal dari populasi yang nilai prestasi akademiknya berdistribusi normal dengan mean 56 dan standar deviasi 11,7233? Masukkan fungsi =F4+B5 pada sel F5, lalu seret sel tersebut ke bawah hingga sel F9 dan dapatkan hasil seperti di atas.
Angka yang lebih besar antara dua kolom ((kolom |Fn(yk – 1) – F0(yk)| dan |Fn(yk)-F0(yk)|) merupakan nilai statistik D dari uji Kolmogorov-Smirnov. hasilnya tidak Terdapat cukup bukti untuk menolak bahwa data skor prestasi belajar berdistribusi normal dengan mean 56 dan standar deviasi 11,7233 Kembali ke tab Data View, ambil kolom Data dan ketikkan data skor hasil prestasi belajar (gunakan data tunggal pada contoh 5.1).
Maka hasil keluaran yang diperoleh pada kolom One-Sample Kolmogorov-Smirnov Test adalah sebagai berikut.
Uji Homogenitas
Kesimpulan: F-angka = 1,3853 < F-tabel = 2,2189 sehingga berada pada rentang penerimaan H0, maka H0 diterima karena tidak cukup bukti untuk menolak H0 dan bukan karena H0. Dalam analisis varians yang menguji persamaan beberapa mean, diasumsikan bahwa populasi mempunyai varians yang homogen. Berdasarkan sampel acak yang diambil dari setiap populasi, ditemukan beberapa metode untuk melakukan pengujian tersebut, namun pada kesempatan kali ini kita hanya akan membahas uji Bartlett saja.
Untuk mempermudah perhitungan, satuan-satuan yang diperlukan untuk uji Bartlett sebaiknya disusun dalam tabel seperti Tabel 6.4. Data pertambahan bobot badan kambing percobaan yang diberi empat jenis pakan disajikan pada Tabel 6.4 (Sudjana, 1992). Kolom H: n adalah jumlah data dari masing-masing kelompok sampel Kolom I: dk = n – 1 fungsi =H3-1 dengan cara ditarik ke bawah.
Kemudian menyeret sel K3 ke baris 4 pada penomoran sampel akan memberikan hasil pada kolom K. Kemudian menyeret sel L3 ke baris 4 pada penomoran sampel akan memberikan hasil pada kolom L. Hitung varians gabungan dengan rumus.

Sampel Independen (Tidak Berkorelasi)
Penelitian dilakukan untuk menguji hipotesis bahwa tidak terdapat perbedaan kemampuan pegawai pria dan wanita di bidang elektronika. Statistik nonparametrik yang digunakan untuk menguji hipotesis komparatif untuk dua sampel independen meliputi: χ2 Fisher ExactProbability; Tes median. -squared digunakan untuk menguji hipotesis perbandingan antara dua sampel ketika datanya nominal dan sampelnya besar.
Uji ini digunakan untuk menguji signifikansi hipotesis komparatif dua sampel kecil yang independen apabila datanya nominal. Untuk membuktikan hal tersebut, pengumpulan data dilakukan dengan menggunakan random sampling. Dengan kata lain, kesamaan μ1<μ2 dapat diterima jika w1 cukup kecil; pasangan μ1>μ2 diterima jika w2 cukup kecil; dan pembilang μ1≠μ2 diterima sebagai minimum w1 dan w2.
Urutkan data pada blok kolom G, pilih Sort & Filter, lalu pilih Sort Z to A, Anda akan mendapatkan hasil seperti di atas. Jika frekuensi datanya hanya 1 maka rank adalah jumlah datanya, tetapi jika frekuensi datanya lebih dari 1 maka ranknya adalah rata-rata dari jumlah datanya. Jika kita mengisi rangking pada kolom C dengan mengambil data pada kolom H dengan fungsi =VLOOKUP(B3,$G$2:$H$35.2,FALSE) maka hasilnya sebagai berikut.
Mengisi rangking pada kolom E dengan mengambil data pada kolom H dengan fungsi =VLOOKUP(D2,$G$2:$H$35,2,FALSE) hasilnya sebagai berikut.

Komparatif k Sampel
Untuk mendapatkan hasil di atas, selC2, E2, dan G2 tarik ke bawah sebanyak baris data yang ada di sisi kiri kolom. Seorang guru matematika ingin mengetahui efektivitas pemberian soal latihan berupa pekerjaan rumah dengan menggunakan perangkat dan buku teks kepada dua kelompok siswa, yaitu dengan menguji keefektifannya berdasarkan hasil/skor soal latihan yang dibuat siswa tersebut. Untuk keperluan penelitian, guru mengambil 10 siswa cerdas yang masing-masing mendapat dua perlakuan berbeda dan 10 siswa kurang cerdas mendapat dua perlakuan berbeda.
Tarik sel C3 ke bawah hingga baris terakhir grup data LKS, lalu tambahkan dengan fungsi =SUM(C3:C12), hasilnya 56209 dan tarik sel E3 ke bawah hingga baris terakhir grup data LKS, lalu tambahkan dengan fungsi =SUM (E3:E12) hasilnya adalah 26400 untuk mendapatkan hasil diatas. Seret sel C14 ke bawah ke baris terakhir grup data paket dan tambahkan dengan fungsinya. Hasil SUM(C14:C23) adalah 37786, dan tarik sel E14 ke baris terakhir grup data buku teks, lalu jumlahkan dengan fungsi =SUM(E14:E23) sehingga menghasilkan 24191.
Tarik cellF3 ke bawah hingga baris terakhir grup data LKS lalu tambahkan menggunakan fungsi =SUM(F3:F12) hasilnya 1255 dan tarik cellG3 ke bawah hingga baris terakhir grup data LKS lalu tambahkan ditambah dengan fungsi =SUM (G3:G12), hasilnya 82609. Seret sel F14 ke bawah ke baris terakhir grup data paket lalu tambahkan dengan fungsi tersebut. SUM(F14:F23) menghasilkan 1097 dan menyeret selG14 ke baris terakhir grup data paket lalu menambahkannya dengan fungsi =SUM(G14:G23) yang menghasilkan 61977.
Hitung jumlah nilai siswa cerdas dan siswa lemah baik dari kelompok LKS maupun buku teks.
Statistik Nonparametrik
Regresi Sederhana
Regresi Ganda
Reliabilitas