1
IMPLEMENTASI METODE POHON KEPUTUSAN UNTUK KLASIFIKASI
DATA DENGAN NILAI FITUR YANG TIDAK PASTI
Ratih Ariadni1, Isye Arieshanti2
Teknik Informatika, Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember (ITS), Surabaya, 60111, Indonesia
Email : [email protected], [email protected]
ABSTRAKSI
Decision tree merupakan salah satu metode untuk mengklasifikasikan data. Model decision tree merupakan sebuah tree yang terdiri dari root node, internal node dan terminal node. Sementara root node dan internal node merupakan variabel/fitur, terminal node adalah label kelas. Dalam melakukan klasifikasi, sebuah data query akan menelusuri root node dan internal node samapi mencapai terminal node. Pelabelan kelas data query berdasarkan label di internal node.
Pada Decision Tree tradisional, data yang digunakan adalah data dengan nilai fitur yang sudah pasti. Pada penelitian ini bertujuan untuk membangun suatu Decision Tree yang dapat menangani data dengan nilai fitur yang tidak pasti yaitu data yang memiliki range nilai. Selama ini penanganan data dengan fitur yang tidak pasti menggunakan metode averaging. Akan tetapi ada penelitian lain yang menyebutkan bahwa ada metode lain yang lebih handal dalam menangani data dengan nilai fitur yang tidak pasti. Metode tersebut adalah metode berbasis distribusi.
Tugas akhir ini bertujuan untuk mengimplementasikan metode decision tree yang mampu menghandle fitur dengan nilai yang tidak pasti dengan menggunakan metode yang berbasis distribusi. Akurasi dari metode ini dibandingkan dengan akurasi metode averaging. Berdasarkan hasil uji coba, terbukti bahwa metode berbasis distribusi memiliki akurasi yang lebih tinggi jika dibandingkan dengan akurasi metode yang berbasis averaging. Uji coba dilakukan dengan menggunakan data iris dan data breast dari UCI.
Kata kunci : Klasifikasi, DecisionTree, Uncertain Data
1
PENDAHULUAN
Klasifikasi adalah masalah klasik pada machine
learning dan data mining untuk meramalkan suatu nilai
pada sekumpulan data[1]. Klasifikasi sendiri merupakan suatu proses menemukan kumpulan pola atau fungsi yang mendeskripsikan serta memisahkan kelas data yang satu dengan yang lainnya untuk menyatakan objek tersebut masuk pada kategori tertentu yang sudah ditentukan. Salah satu metode klasifikasi yang populer adalah metode pohon keputusan atau decision tree. Metode ini populer karena mampu melakukan klasifikasi sekaligus menunjukkan hubungan antar atribut. Berbagai macam
algoritma yang dapat membangun suatu decision tree salah satunya adalah C45[2].
Dalam proses klasifikasi pohon keputusan tradisional, fitur (atribut) dari tupel adalah kategorikal atau numerikal. Biasanya definisi ketepan nilai (point
value) sudah didefinisikan di awal. Pada banyak aplikasi
nyata, terkadang muncul suatu nilai yang tidak pasti[3]. Suatu data yang tidak pasti muncul secara alami pada aplikasi karena berbagai alasan. Alasan – alasan tersebut yaitu kesalahan pengukuran dan pengukuran berulang[3]. Berdasarkan alasan permasalahan tersebut, Metode ini merupakan cara yang sederhana untuk menangani uncertain data yaitu dengan cara membuat ringkasan data-data statistik seperti mean dari probabilitas distribusi. Namun, pendekatan averaging memiliki beberapa kekurangan salah satunya adalah memiliki akurasi yang kurang baik. Untuk menutupi kekurangan tersebut, maka terdapat penelitian lain yang menggunakan pendekatan distribution based yang mempertimbangkan keseluruhan informasi pada probabilitas distribusi untuk membangun decision tree. Pendekatan ini memiliki beberapa kelebihan yaitu dapat berpotensi membangun
decision tree yang lebih akurat dibandingkan dengan
pendekatan averaging. Berdasarkan kelebihan tersebut, maka tugas akhir ini mengimplementasikan metode
decision tree untuk uncertain data, menggunakan metode
distribution based. Nantinya akan dibandingkan dengan metode berbasis averaging.
2
DECISION TREE
Pohon Keputusan atau dikenal dengan Decision
Tree adalah salah satu metode klasifikasi yang
menggunkan representasi suatu struktur pohon yang yang berisi alternatif-alternatif untuk pemecahan suatu masalah. Pohon ini juga menunjukkan faktor-faktor yang mempengaruhi hasil alternatif dari keputusan tersebut disertai dengan estimasi hasil akhir bila kita mengambil keputusan tersebut. Peranan pohon keputusan ini adalah sebagai Decision Support Tool untuk membantu manusia dalam mengambil suatu keputusan[3]. Manfaat dari
decision tree adalah melakukan break down proses
2
Decision tree menggunakan struktur hierarki untuk
pembelajaran supervised. Proses dari decision tree dimulai dari root node hingga leaf node yang dilakukan secara rekursif[4]. Di mana setiap percabangan menyatakan suatu kondisi yang harus dipenuhi dan pada setiap ujung pohon menyatakan kelas dari suatu data. Pada decision tree terdiri dari tiga bagian yaitu[4]: a. Root node
Node ini merupakan node yang terletak paling atas dari suatu pohon.
b. Internal node
Node ini merupakan node percabangan, hanya terdapat
satu input serta mempunyai minimal dua output. c. Leaf node.
Node ini merupakan node akhir, hanya memiliki satu
input, dan tidak memiliki output.
3
ALGORITMA DECISION TREE C45
Pohon dibangun dengan cara membagi data secara rekursif hingga tiap bagian terdiri dari data yang berasal dari kelas yang sama. Bentuk pemecahan (split) yang digunakan untuk membagi data tergantung dari jenis atribut yang digunakan dalam split. Algoritma C4.5 dapat menangani data numerik (kontinyu) dan diskret. Split untuk atribut numerik yaitu mengurutkan contoh berdasarkan atribut kontiyu A, kemudian membentuk minimum permulaan (threshold) M dari contoh-contoh yang ada dari kelas mayoritas pada setiap partisi yang bersebelahan, lalu menggabungkan partisi-partisi yang bersebelahan tersebut dengan kelas mayoritas yang sama.
Split untuk atribut diskret A mempunyai bentuk value (A)
ε X dimana X ⊂ domain(A).
Jika suatu set data mempunyai beberapa pengamatan dengan missing value yaitu record dengan beberapa nilai variabel tidak ada, Jika jumlah pengamatan terbatas maka atribut dengan missing value dapat diganti dengan nilai rata-rata dari variabel yang bersangkutan.
Dalam melakukan pemisahan obyek (split) dilakukan tes terhadap atribut dengan mengukur tingkat ketidakmurnian pada sebuah simpul (node). Pada algoritma C.45 menggunakan rasio perolehan (gain ratio). Sebelum menghitung rasio perolehan, perlu menghitung dulu nilai informasi dalam satuan bits dari suatu kumpulan objek. Cara menghitungnya dilakukan dengan menggunakan konsep entropi. Rumus untuk menghitung entropi adalah sebagai berikut:
= − −
S adalah ruang (data) sampel yang digunakan untuk
pelatihan, p+ adalah jumlah yang bersolusi positif atau mendukung pada data sampel untuk kriteria tertentu dan
p- adalah jumlah yang bersolusi negatif atau tidak mendukung pada data sampel untuk kriteria tertentu. Entropi(S) sama dengan 0, jika semua contoh pada S berada dalam kelas yang sama. Entropi(S) sama dengan 1, jika jumlah contoh positif dan negative dalam S adalah sama. Entropi(S) lebih dari 0 tetapi kurang dari 1, jika jumlah contoh positif dan negative dalam S tidak sama.
Kemudian menghitung perolehan informasi dari output data atau variabel dependent y yang dikelompokkan berdasarkan atribut A, dinotasikan dengan
gain (y,A). Perolehan informasi, gain (y,A), dari atribut A
relative terhadap output data y adalah:
, = −
!" #" $
Nilai (A) adalah semua nilai yang mungkin dari atribut A, dan yc adalah subset dari y dimana A mempunyai nilai c. Term pertama dalam persamaan diatas adalah entropi total y dan term kedua adalah entropi sesudah dilakukan pemisahan data berdasarkan atribut A.
Untuk menghitung rasio perolehan perlu diketahui suatu term baru yang disebut pemisahan informasi
(SplitInfo). Pemisahan informasi dihitung dengan cara :
% & , = − " " '()
S1 sampai Sc adalah c subset yang dihasilkan dari
pemecahan S dengan menggunakan atribut A yang mempunyai sebanyak c nilai. Selanjutnya rasio perolehan (gain ratio) dihitung dengan cara :
, = % & * , ,
4
KLASIFIKASI VOTED PERCEPTRON
Uncertain data adalah suatu data yang tidak dapat
direpresentasikan dengan suatu point data atau nilai tunggal[3]. Suatu data uncertain memiliki interval nilai. Biasanya, data dengan informasi uncertainty diwakili oleh pdf atas suatu wilayah yang terbatas dan dibatasi oleh suatu nilai yang mungkin[6]. Hal ini sering muncul dalam beberapa kasus yang disebabkan oleh:
a. Kesalahan Pengukuran
Data yang diperoleh dari pengukuran dengan menggunakan perangkat fisik sering tidak tepat akibat kesalahan pengukuran. Sebagai contoh, sebuah termometer tympanic (telinga) mengukur suhu tubuh dengan cara mengukur temperatur gendang telinga melalui sebuah sensor inframerah[3].
b. Pengukuran Berulang
Sumber ketidakpastian data yang paling umum adalah dari pengukuran berulang. Sebagai contoh, suhu tubuh pasien dapat diambil beberapa kali sehari. Suhu pasien setiap jam belum tentu[3].
3
a. Averaging
Averaging adalah suatu algoritma greedy yang membangun tree top-down. Ketika akan memproses suatu node, harus diperiksa juga semua kumpulan dari tupel S. Algoritma ini dimulai dari root node dengan S sebagai kumpulan dari tupel. Pada setiap node n, yang harus dilakukan pertama kali adalah mengecek apakah semua tupel memiliki kelas label c. Selanjutnya adalah memilih atribut Ajn dan split point zn dan membagi tupel menjadi dua subset yaitu left dan right. Untuk tupel ≤ zn diletakkan di bagian left dan tupel ≥ zn diletakkan di
bagian right. Algoritma ini berjalan secara rekursif untuk mengecek semua tupel dan meletakkan pada left atau right.
Dalam menentukan split point diperlukan suatu best split. Best split digunakan untuk memilih atribut dan split point dengan derajat dispersi yang minimal. Derajat dispersi dapat diukur dengan berbagai cara seperti entropi atau gini index[5]. Pemilihan dispersi akan berpengaruh pada struktur pohon yang dihasilkan. Berikut ini merupakan ilustrasi dari penggunaan averaging untuk membangun suatu pohon yang ditunjukkan oleh tabel 1:
Tabel 1 Contoh Penggunaan Averaging
tupel probabilitas 5/8, 1/8, dan 2/8. Berdasarkan masing-masing probabilitas dari nilai atribut dilakukan perhitungan mean dan didapatkan hasil yaitu sebesar +2. Berdasarkan averaging, didapatkan suatu partisi yaitu untuk tupel yang bernomor ganjil akan terletak di left dan tupel bernomor genap akan terletak di right.
b. Distribution Based
Untuk data yang tidak pasti mengadopsi framework
decision tree yang sama untuk menangani data point.
Setelah atribut Ajn dan split poin zn telah dipilih untuk
node n, kita harus membagi himpunan tupel menjadi dua S himpunan bagian L dan R. Pdf dari tuple ti∈S dalam
atribut Ajn direntangkan pada interval [ai,jn, bi,jn]. Dengan
ai,jn, adalah nilai minimal dan bi,jn adalah nilai maksimal pada suatu atribut. Jika bi,jn≤ zn, pdf dari ti sepenuhnya terletak di sebelah kiri split point dan dengan demikian ti ditugaskan sebagai L. Jika pdf berisi split point, yaitu,
ai,jn≤ zn < bi,jn, dibagi menjadi dua tupel ti fraksional tL dan
tR dengan cara yang sama dan menambahkannya ke L dan
R.
Kunci untuk membangun decision tree yang baik adalah pilihan dari sebuah atribut Ajn dan split point zn untuk setiap node n. Dengan data uncertain, pemilihan split point tidak terbatas pada m-1 nilai point. Hal ini karena ti tuple pdf merentang pada interval kontinyu [ai,j,
bi,j ]. Perubahan sedikit pada tuple tL dan tR akan mengubah hasil pada tree. Jika kita memodelkan pdf dengan nilai-nilai sampel s, kita mendekatkan pdf dengan distribusi diskrit. Dalam hal ini, split point berpindah dari satu end point ai,j ke end poin bi,j. dari interval tersebut. Dengan tuple m, ada di titik sampel total ms. Jadi, terdapat pada ms-1 kemungkinan split point untuk dipertimbangkan. Untuk mendapatkan atribut terbaik pada pada k atribut, maka harus melakukan pencarian atribut terbaik sebanyak k(ms-1). Oleh karena itu, distribution based membutuhkan waktu yang lebih lama dibandingkan averaging.
5
PROSES GENERATE DATA CERTAIN
MENJADI UNCERTAIN
Pada tahapan ini proses generate data digunakan untuk membuat data uncertain dari data certain. Data
certain berisi suatu point value tanpa uncertainty. Untuk
mengontrol uncertainty pada data certain perlu ditambahkan suatu informasi uncertainty pada masing-masing dataset. Untuk memodelkan dataset menjadi informasi yang mengandung uncertainty adalah dengan cara membuat error model pada data point. Pada setiap tupel ti dan setiap atribut Aj, suatu nilai point vi,j pada dataset digunakan sebagai nilai mean pada pdf dan ditemukan pada interval [ai,j, bi,j]. Rentang nilai Aj pada seluruh dataset dicatat dan width dari [ai,j, bi,j] diatur sebagai w. |Aj| menunjukkan lebar dari jangkauan untuk Aj dan w adalah parameter yang mengontrol lebar jangkauan interval.
Dalam melaukan proses generate data, langkah-langkah yang dilakukan adalah sebagai berikut:
1. Menentukan range dari setiap atribut.
Pada langkah pertama ini, untuk menentukan range dari setiap atribut yang harus dilakukan adalah mengetahui nilai minimal dan maksimal dari setiap atribut. Selanjutnya adalah menentukan width yang akan digunakan sebagai parameter untuk mengontrol lebar jangkauan. Rumus yang digunakan untuk menentukan range dari setiap atribut yaitu:
4 2. Menentukan error dari masing-masing nilai point.
Pada langkah kedua ini, generate error dibagi menjadi dua untuk masing-masing nilai point. Pembagiannya yaitu left dan right. Untuk mendapatkan nilai generate error left dan right digunakan rumus sebagai berikut:
Gen errorleft = nilai point – rangeAj
Gen error right = nilai point + rangeAj
Perhitungan ini dilakukan pada semua nilai point yang dimiliki oleh dataset. Pada langkah kedua ini yang dihasilkan adalah suatu interval yakni nilai left dan right. 3. Membuat PDF
Pada langkah ketiga ini, nilai interval yang dihasilkan dari langkah kedua selanjutnya akan diuji menggunakan distribusi Gaussian. Dalam distribusi Gaussian dilakukan penentuan jumlah sampel yang akan digunakan. Pada tugas akhir ini sampel yang digunakan sebanyak 100. Fungsi random.Gaussian akan dilakukan selama nilai interval >= NUM_STDEV/2 atau nilai interval <= -NUM_STDEV/2. Hasil dari distribusi ini selanjutnya akan dilakukan proses sorting untuk mengurutkan data dari yang terkecil hingga terbesar. Setelah proses sorting, akan didapatkan interval yang baru hasil dari proses distribusi Gaussian.
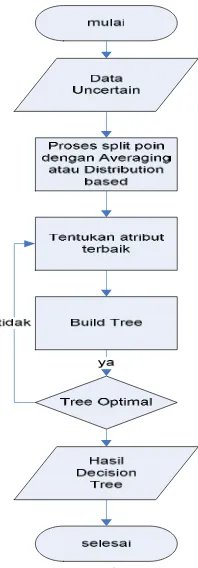
Secara umum proses membuat data uncertain dari data
certain dapat digambarkan dengan diagram alir sebagai
berikut :
Gambar 1 Diagram alir proses generate data
6
PROSES PEMBUATAN TREE
Pada bagian ini dijelaskan tentang perancangan proses untuk mengetahui alur dari proses pembuatan tree. Data yang digunakan adalah data yang dihasilkan dari proses generate data yaitu berupa data yang memiliki interval. Selanjutnya, dari masing-masing data interval tersebut [a,b] digunakan untuk membangun decision tre dengan split point tertntu yaitu sesuai dengan algoritma yang dipilih oleh user. jika lagoritma yang dipilih adalah
averaging, maka masing-masing data interval diubah
menjadi nilai mean dengan rumus sebagai berikut: . = / .& . 0.
1
#
Sedangkan untuk algoritma distribution based, masing-masing data interval diubah menjadi nilai probabilitas dengan rumus sebagai berikut:
2 . = / & . 0. 1
#
Pada tugas akhir ini, distribusi yang dipilih adalah distribusi Gaussian atau distribusi normal sehingga fungsi probabilitasnya adalah sebagai berikut:
& . = 1 √26 7 8
Selanjutnya dilakukan pencarian atribut terbaik untuk menentukan root node dan internal node. Secara garis besar proses ini dapat ditunjukkan diagram alir sebagai berikut:
5
7
UJI COBA DAN PEMBAHASAN
Total data yang digunakan berjumlah 100 untuk masing-masing dataset. Dataset yang tersedia adalah dataset Iris dan Breast. Dari 100 data tersebut, diambil 90 data untuk proses pembelajaran(traning set) dan 10 data untuk proses pelatihan sistem (testing set).
Pada bagian ini dijelaskan mengenai skenario uji coba yang telah dilakukan untuk mengetahui kemampuan sistem dalam memprediksi hasil klasifikasi data menggunakan decision tree. Skenario ini dibagi menjadi dua bagian yaitu skenario dengan pemilihan algortima
Averaging (AVG) dan skenario dengan pemilihan
algoritma Distribution Based (UDT).
Kedua skenario tersebut dijelaskan pada subbab berikut ini.
7.1
Uji Coba Decision Tree dengan Averaging
Tahap uji coba algoritma averaging dilakukan pada kedua dataset yaitu dataset Iris dan Breast. Untuk melakukan skenario uji coba ini, jumlah dataset yang digunakan sebanyak 100 data dengan pembagian 90 untuk
traning set dan 10 untuk testing set. Kemudian uji coba
ini dilakukan sebanyak 10 kali dengan perbedaan komposisi data traning dan data testing. Tabel 2 menunjukkan hasil tahap uji coba untuk algoritma averaging. Sedangkan hasil dari proses pembuatan tree untuk dataset Iris dengan algoritma averaging ditunjukkan oleh gambar 3 sebagai berikut:
Gambar 3 Hasil Pembuatan Tree dengan Averaging untuk Data Iris
Rule yang dihasilkan untuk data Iris dari proses decision tree dengan algoritma averaging pada data iris adalah sebagai berikut:
1. (Petal length > 1,9) Kelas 1
2. (Petal length > 1,9) ^ (Petal width ≤ 1,7) ^ (Petal length ≤ 4,9 ) ^ (Petal width ≤ 1,6 ) Kelas 2 3. (Petal length > 1,9) ^ (Petal width ≤ 1,7) ^ (Petal
length ≤ 4,9 ) ^ (Petal width > 1,6 ) Kelas 3 4. (Petal length > 1,9) ^ (Petal width ≤ 1,7) ^ (Petal
length >4,9 ) ^ (Petal width ≤ 1,5 ) Kelas 3
5. (Petal length > 1,9) ^ (Petal width ≤ 1,7) ^ (Petal length >4,9 ) ^ (Petal width > 1,5) ^ Sepal length ≤ 6,7 ) Kelas 2
6. (Petal length > 1,9) ^ (Petal width ≤ 1,7) ^ (Petal length >4,9 ) ^ (Petal width > 1,5) ^ Sepal length >6,7 ) Kelas 3
7. (Petal length >1,9) ^ (Petal width >1,7) ^ (Petal length≤ 4,8 ) ^ (Sepal Length ≤ 5,9) Kelas 2 8. (Petal length >1,9) ^ (Petal width >1,7) ^ (Petal length
≤ 4,8 ) ^ (Sepal Length >5,9) Kelas 2
9. (Petal length >1,9) ^ (Petal width >1,7) ^ (Petal length >4,8 ) Kelas 3
Tabel 2 Hasil Uji Coba dengan Averaging
Dataset Akurasi
Iris Breast
0,94598 0,935
7.2
Uji Coba Algoritma Decision Tree dengan
Distribution Based
Tahap uji coba algoritma distribution based dilakukan pada kedua dataset yaitu dataset Iris dan Breast. Untuk melakukan skenario uji coba ini, jumlah dataset yang digunakan sebanyak 100 data dengan pembagian 90 untuk traning set dan 10 untuk testing set. Kemudian uji coba ini dilakukan sebanyak 10 kali dengan perbedaan komposisi data traning dan data testing. Tabel 3 menunjukkan hasil tahap uji coba untuk algoritma
distribution based. Hasil proses pembentukan tree untuk
6 Gambar 4 Hasil Pembuatan Tree dengan Distribution
Based untuk Data Iris
Rule yang dihasilkan untuk data Iris dari proses decision tree dengan algoritma distribution based pada data iris adalah sebagai berikut:
1. (Petal length ≤ 1,96 ) Kelas 1
2. (Petal length>1,96) ^ (Petal width ≤ 1,72) ^ (Petal length ≤4,94) ^ (Petal width≤1,62) Kelas 2
3. (Petal length>1,96) ^ (Petal width ≤ 1,72) ^ (Petal length ≤4,94) ^ (Petal width>1,62) Kelas 3
4. (Petal length>1,96) ^ (Petal width≤1,72) ^ (Petal length >4,94) ^ (Petal width≤1,52) ^ (Sepal Length≤6,33) Kelas 2
5. (Petal length>1,96) ^ (Petal width≤1,72) ^ (Petal length >4,94) ^ (Petal width≤1,52) ^ (Sepal Length>6,33) Kelas 3
6. (Petal length>1,96) ^ (Petal width≤1,72) ^ (Petal length >4,94) ^ (Petal width>1,52) ^ (Sepal Length≤6,7) Kelas 2
7. (Petal length>1,96) ^ (Petal width≤1,72) ^ (Petal length >4,94) ^ (Petal width>1,52) ^ (Sepal Length>6,7) Kelas 3
8. (Petal length>1,96) ^ (Petal width>1,72) ^ (Petal length≤4,85) ^ (Sepal width≤3,02) Kelas 3
9. (Petal length>1,96) ^ (Petal width>1,72) ^ (Petal length≤4,85) ^ (Sepal width>3,02) Kelas 2
10.(Petal length>1,96) ^ (Petal width>1,72) ^ (Petal length≤4,85) Kelas 3
Gambar 5 Hasil Pembuatan Tree dengan Distribution Based untuk DataBreast
Rule yang dihasilkan untuk data Breast dari proses decision tree dengan algoritma distribution based pada data iris adalah sebagai berikut:
1. (F23≤115,68) ^ (F28≤0,137) ^ (F23≤107,03) ^ (F11≤0,62) Kelas B
2. (F23≤115,68) ^ (F28≤0,137) ^ (F23≤107,03) ^ (F11>0,62) ^ (F9≤0,161) Kelas M
3. (F23≤115,68) ^ (F28≤0,137) ^ (F23≤107,03) ^ (F11>0,62) ^ (F9>0,161) Kelas B
4. (F23≤115,68) ^ (F28≤0,137) ^ (F23>107,03) ^ (F2≤18,77) Kelas B
5. (F23≤115,68) ^ (F28≤0,137) ^ (F23>107,03) ^ (F2>18,77) ^ (F21≤16,8) ^ (F8≤0,041) ^ (F22≤32,66) Kelas B
6. (F23≤115,68) ^ (F28≤0,137) ^ (F23>107,03) ^ (F2>18,77) ^ (F21≤16,8) ^ (F8≤0,041) ^ (F22>32,66) Kelas M
7. (F23≤115,68) ^ (F28≤0,137) ^ (F23>107,03) ^ (F2>18,77) ^ (F21≤16,8) ^ (F8>0,041) Kelas M 8. (F23≤115,68) ^ (F28≤0,137) ^ (F23>107,03) ^
7 9. (F23≤115,68) ^ (F28≤0,137) ^ (F23>107,03) ^
(F2>18,77) ^ (F21>16,8) ^ (F28>0,122) Kelas M 10. (F23≤115,68) ^ (F28>0,137) ^ (F22≤27,55) ^
(F24≤702,29) Kelas B
11. (F23≤115,68) ^ (F28>0,137) ^ (F22≤27,55) ^ (F24>702,29) ^ (F22≤20,21) Kelas B
12. (F23≤115,68) ^ (F28>0,137) ^ (F22≤27,55) ^ (F24>702,29) ^ (F22>20,21) ^ (F6≤0,122) ^ (F2≤20,41) Kelas B
13. (F23≤115,68) ^ (F28>0,137) ^ (F22≤27,55) ^ (F24>702,29) ^ (F22>20,21) ^ (F6≤0,122) ^ (F2>20,41) Kelas M
14. (F23≤115,68) ^ (F28>0,137) ^ (F22≤27,55) ^ (F24>702,29) ^ (F22>20,21) ^ (F6>0,122) ^ (F2≤17,29) Kelas M
15. (F23≤115,68) ^ (F28>0,137) ^ (F22≤27,55) ^ (F24>702,29) ^ (F22>20,21) ^ (F6>0,122) ^ (F2>17,29) Kelas M
16. (F23≤115,68) ^ (F28>0,137) ^ (F22>27,55) Kelas M
17. (F23>115,67) ^ (F7≤0,64) ^ (F30≤0.061) Kelas B 18. (F23>115,67) ^ (F7≤0,64) ^ (F30>0.061) ^
(F2≤15,40) Kelas B
19. (F23>115,67) ^ (F7≤0,64) ^ (F30>0.061) ^ (F2>15,40) Kelas M
20. (F23>115,67) ^ (F7>0,64) Kelas M
Tabel 3 Hasil Akurasi dengan Distribution Based
dataset Akurasi
Iris Breast
0,9467 0,94044
7.3
Perbandingan Nilai Akurasi Antara Decision
Tree dengan Averaging dan Distribution
Based
Berdasarkan tabel 2 dan 3 yang menunjukkan hasil akurasi antara algoritma averaging dan distribution based pada kedua dataset. Berikut ini akan diberikan tabel untuk perbandingan antara hasil akurasi anatar kedua metode yang ditunjukkan oleh tabel 4sebagi berikut:
Tabel 0Perbandingan Akurasi Antara Averaging dan Distribution Based
dataset
Akurasi
Averaging
Distribution
Based
Iris
Breast
0,94598
0,935
0,9467
0,94044
Dari tabel 4 terlihat bahwa hasil akurasi dari
distribution based lebih tinggi jika dibandingkan dengan
averaging. Terbukti bahwa distribution based lebih baik jika dibandingkan dengan averaging.
8
KESIMPULAN
Kesimpulan yang dapat diambil berdasarkan hasil uji coba yang telah dilakukan pada Tugas Akhir ini yaitu :
Kesimpulan yang dapat diambil dari hasil uji coba dari Tugas Akhir ini adalah sebagai berikut:
1. Algortima distribution based lebih baik daripada averaging dibuktikan dengan hasil akurasi yang lebih tinggi.
2. Waktu yang diperlukan untuk membangun tree dengan algoritma distribution based lebih lama jika dibandingkan dengan aloritma averaging.
REFERENSI
[1] Agrawal,R, T.Imielinski, and A. N. Swami. Database Mining: A Performance Perspective. IEEE Trans.vol 5. pp.914-925. 1993
[2] Kaufmann , Morgan (1993).C4.5: Programs for Machine Learning. ISBN 1-55860-238-0
[3] Tsang, Smith, Ben Kao, Kevin Y.Yipi, Wai shing Ho, and sau Dan Lee. Decision Tree for Uncertain Data. IEEE Computer Society. 2009
[4] Alpaydin ,Ethem (2004). Introduction to Machine Learning. The MIT Press