BELAJAR SISWA
SKRIPSI
TORANG TAMPUBOLON
080803018
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
ANALISIS DISKRIMINAN FAKTOR YANG MEMPENGARUHI
TINGKAT KELULUSAN SISWA BERDASARKAN PERILAKU
BELAJAR SISWA
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
TORANG TAMPUBOLON
080803018
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : ANALISIS DISKRIMINAN FAKTOR YANG MEMPENGARUHI TINGKAT KELULUSAN SISWA BERDASARKAN PERILAKU BELAJAR SISWA.
Kategori : SKRIPSI
Nama : TORANG TAMPUBOLON
Nomor Induk Mahasiswa : 080803018
Program Studi : SARJANA (S1) MATEMATIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, 26 Juli 2012
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Henry Rani Sitepu, M.Si Drs.Suwarno Ariswoyo, M.Si NIP. 19530303198303 1 002 NIP. 19502103198003 1 001
Diketahui/Disetujui oleh
Departemen Matematika FMIPA USU Ketua,
Prof. Dr. Tulus, M.Si
PERNYATAAN
ANALISIS DISKRIMINAN FAKTOR YANG MEMPENGARUHI TINGKAT KELULUSAN SISWA BERDASARKAN PERILAKU BELAJAR SISWA
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya
Medan, Juli 2012
PENGHARGAAN
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa yang telah memberikan rahmat dan hidayah-Nya sehingga skripsi ini dapat diselesaikan dalam waktu telah ditetapkan.
Ucapan terima kasih penulis sampaikan kepada Bapak Drs. Suwarno Ariswoyo, M.Si selaku pembimbing I dan Drs. Henry Rani Sitepu, M.Si selaku pembimbing II yang telah memberikan panduan dan penuh kepercayaan kepada penulis untuk menyempurnakan skripsi ini.
Penulis juga mengucapkan terima kasih kepada Bapak Dr. Sutarman, M.Sc selaku Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam USU, Bapak Prof. Dr. Tulus, M.Si, selaku Ketua Departemen Matematika Ibu Dra. Mardiningsih, M.Si selaku Sekretaris Departemen Matematika, Bapak Drs. Pasukat Sembiring, M.Si dan Dra. Mardiningsih, M.Si selaku penguji skripsi, dan staf Pengajar Matematika di FMIPA USU, beserta Pegawai Administrasi FMIPA USU.
Penulis juga mengucapkan terima kasih kepada kedua orang tua yang tercinta Ayahanda S. Tampubolon (+) dan Ibunda Minar Br Hutahaean yang telah memberikan semangat dan motivasi kepada saya secara terus-menerus tanpa lelah serta mendidik dan mendoakan saya agar dapat menyelesaikan tugas akhir ini. Seta buat Kakak Tio Tampubolon (Mama Kembar), Abang Tigor Tampubolan serta adik saya Teddy Tampubolon dan Tamaria Elisabeth Tampubolon yang telah memberikan motivasi dan dorongan serta doa kepada saya serta kedua keponakkanku Angga dan Anggi Siregar yang membuat saya menjadi semangat buat mengerjakan Tugas Akhir ini. Buat Elsa, Indra, Hasoloan, Sarah, Rifalin, Rina, Alan, Lindo, Argetta,John Putra, Rohot, April, Catrin serta teman-teman satu perjuangan di Anak Jendral 2008 Matematika yang tidak bisa kusebutkan satu-persatu terima kasih atas dukungan dan doanya buat diriku selama mengerjakan sampai menyelesaikan tugas akhir ini. Tak lupa juga buat adik-adikku Etty 09, Isti11, Endang11 serta adik-adik stambuk semuanya yang tak bisa disebutkan satu persatu terima kasih buat bantuannya selama ini serta dukungannya.
Semoga segala bentuk bantuan yang telah diberikan mendapat balasan yang jauh lebih baik dari Tuhan Yang Maha Esa.
Sebagai seorang mahasiswa, penulis menyadari bahwa masih banyak kekurangan di dalam menyelesaikan skripsi ini. Untuk itu, kritik dan saran yang membangun sangat diharapkan demi perbaikan tulisan ini.
Medan, 16 Juli 2012 Penulis
ANALISIS DISKRIMINAN FAKTOR YANG MEMPENGARUHI TINGKAT KELULUSAN SISWA BERDASARKAN PERILAKU BELAJAR SISWA
ABSTRAK
Analisis diskriminan adalah metode statisiik untuk mengelompokkan atau mengklasifikasikan sejumlah obyek ke dalam beberapa kelompok, berdasarkan beberapa variabel, sedemikian hingga setiap obyek yang menjadi anggota lebih dari satu kelompok. Pada prinsipnya analisis diskriminan bertujuan untuk mengelompokkan setiap obyek ke dalam dua atau lebih kelompok berdasarkan kriteria sejumlah variabel bebas.
Bentuk umum dari analisis diskriminan adalah:
= + 1 1+ 2 2+ 3 3+ + + +
Tujuan penelitian ini adalah untuk mendiskriminasi atau mengelompokkan serta mencari apa yang membedakan faktor-faktor yang mempengaruhi tingkat kelulusan siswa antara tingkat kelulusan siswa antara siswa yang satu dengan yang lain berdasarkan perilaku belajar siswa selama belajar di sekolah.
DISCRIMINANT ANALYSIS FACTORS DETERMINE THE EXTENT OF STUDENTS GRADUATION BASED LEARNING STUDENT CONDUCT
ABSTRACT
Discriminant analysis is a statistical method to categorize or classify a number of objects into groups, based on several variables, such that every object is a member of more than one group. In principle, the discriminant analysis aims to classify each object into two or more groups based on the criteria of a number of independent variables.
The general form of discriminant analysis are:
= + 1 1+ 2 2+ 3 3+ + + +
The purpose of this study was to discriminate or categorize and search for what distinguishes the factors that affect student graduation rate among student graduation rate among students from one another based on the learning behavior of students while studying in school.
DAFTAR ISI
Halaman
Persetujuan i
Pernyataan ii
Penghargaan iii
Abstrak iv
Abstract v
Daftar Isi vi
Daftar Tabel viii
Bab 1 Pendahuluan
1.1. Latar Belakang 1
1.2. Perumusan Masalah 3
1.3. Batasan Masalah 3
1.4. Tinjauan Pustaka 3
1.5. Tujuan Penelitian 6
1.6. Manfaat Penelitian 6
1.7. Metodologi Penelitian 6
Bab 2 Landasan Teori
2.1. Latar Belakang 10
2.1.1 Definisi Perilaku Belajar Siswa 10
2.1.2 Data 11
2.1.3 Variabel 12
2.2. Analisis Multivariate 13
2.4. Uji-Uji Dalam Statistik 19
2.4.1 Uji Kecukupan Sampel 19
2.4.2 Uji Validitas 19
2.4.3 Uji Reabilitas 20
2.5. Analisis Regresi 21
2.51 Analisis Regresi Sederhana dan Berganda 23
2.6. Analisis Diskriminan 25
2.6.1 Syarat-syarat dan Tujuan Analisis Diskriminan 26 2.6.4 Algoritma Pokok Analisis Diskriminan dan Model Matematis 28
Bab 3 Hasil dan Pembahasan
3.1 Latar Belakang 35
3.1.1 Data Hasil Kuisioner 35
3.2. Pengujian Data dengan Uji-Uji Statistik 38
3.2.1 Uji Kecukupan Sampel 38
3.2.2 Uji Validitas 39
3.2.3 Uji Reabilitas 39
3.3 Pengolahan Data dengan Analisis Regresi Berganda 40 3.4 Mencari Hubungan Antar Variabel dengan Analisis Korelasi dan
Determinasi 50
3.5 Mengolah Data dengan Analisis Diskriminan 58
3.5.1 Uji Kesamaan 58
3.5.2 Menentukan Nilai Diskriminan untuk Setiap Responden 66 3.5.3 DeskripsiVariabel Perilaku Belajar Siswa 69
3.6 Analisis Diskriminan dengan SPSS 70
3.6.1 Interpretasi Output 70
3.6.2 Uji Signifikasi 74
3.6.3 Koefisien Fungsi Diskriminan Kanonik Standard 74 3.6.4 Fungsi Diskriminan Kanonik 75
3.6.5 Fungsi Grup Terpusat 76
3.6.6 Klasifikasi Statistik 77
3.6.8 Uji Hasil Klasifikasi 78
3.6.9 Akurasi Statistik 80
Bab 4 Penutup
4.1. Kesimpulan 81
4.2. Saran 83
DAFTAR TABEL
Halaman Tabel 3.1 : Data-data Responden Berupa Faktor Perilaku Belajar 36 Tabel 3.2 : Data Responden Setelah Diolah 41 Tabel 3.3 : Data Responden Hasil Pengolahan Data 44 Tabel 3.4 : Nilai Koefisien Intersep Penduga Variabel-Variabel Bebas 49 Tabel 3.5 : Nilai Korelasi Antar Sesama Variabel 50
Tabel 3.6 : Uji Kesamaan Rata-rata 58
Tabel 3.7 : Uji Kesamaan Matriks Kovarians 58
Tabel 3.8 : Uji Box‟s M 58
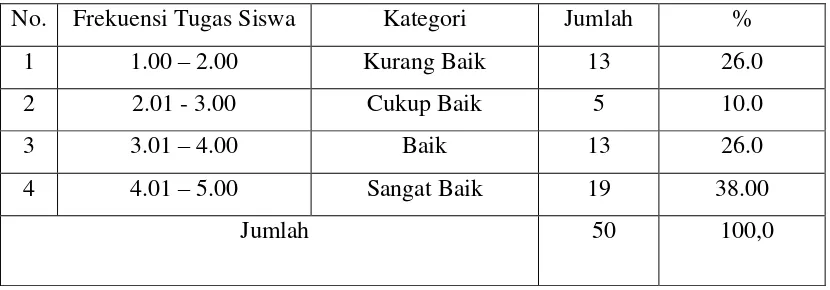
Tabel 3.9 : Nilai Diskriminan Masing-masing Sampel atau Responden 67 Tabel 3.10: Pengaruh Perilaku Belajar Siswa terhadap Tingkat Kelulusannya 69 Tabel 3.11: Lama Belajar Siswa Di Luar Sekolah 70
Tabel 3.12: Frekuensi Tugas Siswa 70
Tabel 3.13: Grup Statistik 70
Tabel 3.14: Variabel yang Masuk kedalam Fungsi Diskriminan 72
Tabel 3.15: Variabel dalam Analisis 72
Tabel 3.16: Variabel yang Tidak Masuk Fungsi Diskriminan 73
Tabel 3.17: Nilai Eigen 73
Tabel 3.18: Nilai Wilk‟s lambda 74
Tabel 3.19: Struktur Matriks 75
Tabel 3.20: Koefisien Fungsi Diskriminan Kanonik 75
Tabel 3.21: Fungsi Grup Terpusat 76
Tabel 3.22: Klasifikasi Statistik 77
ANALISIS DISKRIMINAN FAKTOR YANG MEMPENGARUHI TINGKAT KELULUSAN SISWA BERDASARKAN PERILAKU BELAJAR SISWA
ABSTRAK
Analisis diskriminan adalah metode statisiik untuk mengelompokkan atau mengklasifikasikan sejumlah obyek ke dalam beberapa kelompok, berdasarkan beberapa variabel, sedemikian hingga setiap obyek yang menjadi anggota lebih dari satu kelompok. Pada prinsipnya analisis diskriminan bertujuan untuk mengelompokkan setiap obyek ke dalam dua atau lebih kelompok berdasarkan kriteria sejumlah variabel bebas.
Bentuk umum dari analisis diskriminan adalah:
= + 1 1+ 2 2+ 3 3+ + + +
Tujuan penelitian ini adalah untuk mendiskriminasi atau mengelompokkan serta mencari apa yang membedakan faktor-faktor yang mempengaruhi tingkat kelulusan siswa antara tingkat kelulusan siswa antara siswa yang satu dengan yang lain berdasarkan perilaku belajar siswa selama belajar di sekolah.
DISCRIMINANT ANALYSIS FACTORS DETERMINE THE EXTENT OF STUDENTS GRADUATION BASED LEARNING STUDENT CONDUCT
ABSTRACT
Discriminant analysis is a statistical method to categorize or classify a number of objects into groups, based on several variables, such that every object is a member of more than one group. In principle, the discriminant analysis aims to classify each object into two or more groups based on the criteria of a number of independent variables.
The general form of discriminant analysis are:
= + 1 1+ 2 2+ 3 3+ + + +
The purpose of this study was to discriminate or categorize and search for what distinguishes the factors that affect student graduation rate among student graduation rate among students from one another based on the learning behavior of students while studying in school.
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Seperti yang kita ketahui, bahwa akhir-akhir ini nilai standar kelulusan Ujian Nasional (UN) di Indonesia terkhususnya pendidikan di tingkat SMA semakin tinggi. Oleh karena itu, sekolah seharusnya mengetahui apa yang menjadi faktor-faktor yang menentukan tingkat kelulusan siswanya.
Dalam masalah ini, penulis ingin menganalisis faktor yang menentukan tingkat kelulusan siswa berdasarkan perilaku belajar siswa selama belajar di jenjang tingkat pendidikan SMA.Perilaku belajar siswa selama belajar di sekolah diyakini mempunyai peranan yang besar dalam menentukan tingkat kelulusan siswa tersebut. Sebagai penilaiannya, siswa akan menggunakan perilaku belajarnya selama disekolah sebagai standar atau acuan untuk tingkat kelulusannya. Dengan demikian, perilaku belajar siswa dapat melatarbelakangi mengapa tingkat kelulusan siswa yang satu dengan yang lain dapat berbeda.
banyaknya guru memberi tugas pada siswa, les tambahan siswa di sekolah, les tambahan siswa di luar sekolah dan nilai rata-rata siswa dikelas XI.
Responden yang digunakan dalam penelitian ini adalah siswa-siswi kelas XII-IA yang belajar di SMA Kristen Immanuel Medan.Data yang digunakan adalah kuisioner tentang preferensi dan perilaku belajar siswa.Pengolahan data menggunakan software SPSS 16.0.Penelitian ini yang terbatas pada lamanya belajar siswa, les tambahan siswa, frekuensi tugas siswa dan nilai rata-rata siswa.
Analisis diskriminan adalah salah satu teknik statistik yang bias digunakan pada hubungan dependensi atau hubungan antar faktor dimana sudah bias dibedakan mana faktor respon dan mana faktor penjelas. Lebih spesifik lagi, analisis diskriminan digunakan pada kasus dimana faktor respon berupa data kualitatif dan faktor penjelas berupa data kuantitatif.Analisis diskriminan bertujuan untuk mengklasifikasikan suatu individu atau observasi ke dalam kelompok yang saling bebas
1.2PERUMUSAN MASALAH
Masalah yang dibahas dalam penelitian ini ialah pendiskriminan permasalahan tingkat kelulusan siswa dengan Metode Analisis Diskriminan berdasarkan perilaku belajar siswa dan meramalkan kemungkinan tingkat kelulusan siswa pada Ujian Nasional (UN) tingkat pendidikan SMA serta faktor-faktor apa saja yang mempengaruhi tingkat kelulusan siswa SMA Kristen Immanuel Medan.
1.3BATASAN MASALAH
Agar penelitian ini tepat sasaran, penulis menetapkan pembatasan permasalahan :
1. Hanya untuk mengkategorikan faktor-faktor apa yang mempengaruhi tingkat kelulusan siswa. Adapun faktor- faktor yang menentukan tingkat kelulusan siswa seperti lamanya belajar siswa, les tambahan siswa, frekuensi tugas siswa dan nilai rata-rata siswa.
2. Data yang digunakan adalah data nilai rata-rata siswa kelas XII-IA SMA Kristen Immanuel Medan dan data hasil kuesioner dari responden yakni siswa-siswi SMA Kristen Immanuel Medan.
1.4TINJAUAN PUSTAKA
kovarians dan korelasi yang mencerminkan hubungan antar variabel. Pengukuran dilakukan pada karakteristik atau atribut suatu obyek.
Adapun demikian, Analisis Diskriminan merupakan salah satu teknik menganalisis dalam analisis multivariate. Analisis diskriminan merupakan teknik menganalisis data, kalau variabel tak bebas (disebut criterion) merupakan kategori (non-metrik, nominal atau ordinal,bersifat kualitatif) sedangkan variabel bebas sebagai prediktor merupakan metrik (interval atau rasio, bersifat kuantitatif). Teknik analisis diskriminan dibedakan menjadi dua yaitu analisis diskriminan dua kelompok atau kategori, kalau variabel tak bebas Y dikelompokkan menjadi dua.Diperlukan satu fungsi diskriminan.
Ada dua asumsi utama yang harus dipenuhi pada analisis diskriminan ini, yaitu : 1. Sejumlah p faktor penjelas harus berdistribusi normal.
2. Matriks varians dan kovarians faktor penjelas berukuran p × p pada kedua kelompok yang sama.
Kalau variabel tak bebas dikelompokkan menjadi lebih dari dua kelompokdisebut analisis diskriminan berganda ( multiple discriminant analysis) diperlukan fungsi diskriminan sebanyak ( k – 1 ) kalau memang ada k kategori. Model analisis diskriminan berkenaan dengan kombinasi linear yang bentuknya sebagai berikut.
= + 1 1+ 2 2+ 3 3+ + + +
= nilai (skor) diskriminan dari responden (objek) ke-i. i = 1, 2, …, n. D merupakan variabel tak bebas.
= variabel (atribut) ke-j dari responden ke-i.
= koefisien atau timbangan diskriminan dari variabel atau atribut ke j. = koefisien atau timbangan diskriminan dari variabel atau atribut ke k.
= variabel bebas atau prediktor ke j dari responden ke i, juga disebut atribut, seperti disebutkan diatas.
Menurut Maholtra (1999), analisis diskriminan terdiri dari lima tahap, yaitu :
1. Merumuskan masalah, tahap ini mencakup jawaban atas pertanyaan kenapa analisis diskriminan dilakukan atau apa yang menjadi latar belakang masalah dan apa tujuan analisis diskriminan, termasuk variable-variabel apa saja yang dilibatkan.
2. Mengestimasi fungsi diskriminan, estimasi dapat dilakukan setelah sampel analisis diperoleh. Ada dua pendekatan umum yang diperoleh. Pertama, metode langsung (direct method), yaitu suatu cara mengestimasi fungsi diskriminan dengan melibatkan faktor-faktor prediktor sekaligus. Setiap faktor di masukan tanpa memperhatikan kekuatan diskriminan masing-masing faktor. Metode ini baik kalau faktor-faktor prediktor dapat diterima secara teoritis. Kedua, stepwise method dalam metode ini faktor prediktor dimasukkan secara bertahap, tergantung pada kemampuannya melakukan diskriminan kelompok atau grup. Metode ini cocok kalau peneliti ingin memilih sejumlah faktor prediktor untuk membentuk fungsi diskriminan.
3. Memastikan signnifikasi determinan. 4. Interpretasi output.
5. Uji signifikasi, tak ada gunanya menginterpretasi hasil analisis diskriminan kalau fungsi tidak signifikan.
1.5TUJUAN PENELITIAN
Adapun tujuan dari penelitian ini adalah untuk mendiskriminasi atau mengelompokkan serta mencari apa yang membedakan faktor-faktor yang mempengaruhi tingkat kelulusa siswa antara tingkat kelulusan siswa antara siswa yang satu dengan yang lain berdasarkan perilaku belajar siswa selama belajar di sekolah.
1.6MANFAAT PENELITIAN
Adapun manfaat penelitian saya ini adalah untuk :
1. Bagi Sekolah, agar mendapat acuan untuk mengetahui bagaimana cara untuk meningkatkan tingkat kelulusan siswanya berdasarkan perilaku belajar siswanya.
2. Bagi Siswa, agar menjadi acuan untuk menentukan seberapa besar kemungkinan mereka lulus berdasarkan perilaku belajar mereka selama disekolah.
3. Bagi Penulis, untuk mengetahui bahwa ada korelasi antara tingkat kelulusan siswa dengan perilaku belajar siswa dan mengaplikasikan ilmu yang selama ini dipelajari oleh si penulis di lingkungan masyarakat.
1.7METODOLOGI PENELITIAN
Penelitian ini dilakukan dengan beberapa langkah yaitu : 1. Pengumpulan Data
Sumber data dalam penelitian ini meliputi :
Data primer, merupakan data yang diperoleh dari sumber pertama, baik individu atau perseorangan.Dalam penelitian ini, berbentuk hasil kuisioner oleh responden.Data sekunder, merupakan data primer yang telah diolah lebih lanjut dan disajikan dalam bentuk table-tabel atau diagram-diagram.Dimana data sekunder tersebut diperoleh dari hasil penilaian belajar siswa/i kelas XII-IA SMA Kristen Immanuel Medan.Populasi dalam penelitian ini adalah seluruh siswa/i kelas XII-IA SMA Kristen Immanuel Medan.Dan populasi telah diketahui homogen dan diasumsikan bahwa populasi berdistribusi normal.Dalam penelitian ini, data diambil dan telah diolah oleh sekolah bersangkutan.Teknik pengumpulan data yang digunakan dalam penelitian ini adalah menggunakan wawancara langsung dengan siswa, mengisi kuisioner (angket) dan dokumentasi.
2. Pengolahan Data
Langkah-langkah yang ditempuh sebelum menentukan metode yang akan digunakan yaitu dengan melakukan pengujian terhadap data antara lain :
1.Uji Kecukupan Sampel (Size Sample Test)
Untuk mendapatkan sampel yang representative dalam penelitian ini digunakan Stratified Random Sampling yaitu metode penelitian sampel dengan membagi populasi ke dalam kelompok-kelompok yang homogen (strata), kemudian sampel diambil secara acak dari setiap strata.
2.Uji Validitas
3.Uji Reliabilitas
Pengujian realibilitas berkaitan dengan masalag adanya kepercayaan terhadap alat uji instrument.Suatu instrument dapat memiliki tingkat kepercayaan yang tinggi jika hasil dari pengujian tersebut menunjukkan tetap.
4. Analisis Diskriminan
Untuk model diskriminan dengan tiga kelompok, pembagian variabel bebas tidak seperti kasus dua kelompok, yakni „langsung‟ variabel A ke kelompok 1, variabel b ke kelompok 2 dan seterusnya. Pada kasus tiga kelompok, seluruh variabel bebas dilakukan proses reduksi variabel dahulu, yakni menjadi satu atau beberapa faktor. Setelah itu, setiap kelompok (sering, cukup dan jarang) akan ditentukan lebih cenderung masuk ke faktor yang mana.Jadi dasar pembagian adalah faktor dan bukan variabel bebas yang semula.Analisis diskriminan adalah metode statistik untuk mengelompokkan atau mengklasifikasikan sejumlah obyek ke dalam beberapa kelompok, berdasarkan beberapa variabel, sedemikian hingga setiap obyek yang menjadi anggota lebih dari pada satu kelompok.Pada prinsipnya analisis diskriminan bertujuan untuk mengelompokkan setiap obyek ke dalam dua atau lebih kelompok berdasarkan pada criteria sejumlah variabel bebas.
Metode analisis data yang digunakan adalah teknik analisis diskriminan dengan bentuk SPSS dengan tahapan sebagai berikut :
1. Memisahkan faktor ke dalam faktor dependent dan faktor independent 2. Analysis Case Processing Summary, tabel yang menyatakan bahwa
responden ( jumlah kasus atau baris SPSS) semuanya valid atau sah untuk diproses, dapat mengetahui data yang hilang.
3. Group Statistics, tabel yang menunjukkan jumlah responden yang mempunyai pengaruh terhadap berpengaruh atau tidak berpengaruh.
4. Test of Equality Groups Means, tabel yang menunjukkan apakah terdapat perbedaan yang signifikan untuk dua grup diskriminan dengan berdasarkan uji F.
6. Variable in The Analysis, tabel yang berisi rangkaian proses tahap sebelumnya, mengenai pemilihan faktor satu persatu yang dimasukkan ke dalam model.
7. Variable Not in The Analysis, tabel ini berisi “kebalikan” dari tabel
sebelumnya, yang memuat faktor yang akan dikeluarkan satu per-satu dari model.
8. Eigenvalues, interpretasi dari pengelompokkan faktor ke dalam satu lebih faktor yang dianalisis.
9. Wilk’s Lambda, mengindikasi perbedaan yang signifikan atau nyata antara kedua grup dalam k model diskriminan berdasarkan angka Chi-Square. 10.Standardized Canonical Discriminant Function Coefficient, menentukan
faktor mana, dasar pemasukan faktor dilihat pada besar korelasi kanonikal, dengan korelasi terbesar masuk ke faktor yang bersangkutan.
11.Structure Matrix, menunjukkan faktor yang paling membedakan perilaku terhadap kelulusan siswa.
12.Function At Group Centroid, tabel ini mengelompokkan ke dua grup dalam satu fungsi 1 atau fungsi 2.
13.Casewise Statistics, tabel ini berisi rincian tiap kasus, penempatannya dalam model diskriminan serta perbandingan apakah penempatannya telah sesuai dengan kenyataan.
14.Classification Result, menunjukkan angka ketepatan prediksi dari model diskriminan. Pada umumnya ketepatan diata 50% dianggap memadai atau sah (valid)
BAB 2
LANDASAN TEORI
2.1 Latar belakang
2.1.1 Definisi Perilaku Belajar Siswa
Perilaku adalah tindakan atau aktivitas dari manusia itu sendiri yang mempunyai bentangan yang sangat luas antara lain : berjalan, berbicara, menangis, tertawa, bekerja, kuliah, menulis, membaca, dan sebagainya. Dari uraian ini dapat disimpulkan bahwa yang dimaksud perilaku manusia adalah semua kegiatan atau aktivitas manusia,
baik yang diamati langsung, maupun yang tidak dapat diamati oleh pihak luar.(Notoatmodjo, 2003). Sedangkan belajar adalah sebuah proses perubahan di dalam kepribadian manusia dan perubahan tersebut ditampakkan dalam bentuk
peningkatan kualitas dan kuantitas tingkah laku seperti peningkatan kecakapan,
pengetahuan, sikap, kebiasaan, pemahaman, ketrampilan, daya pikir, dan
kemampuan-kemampuan yang lain.
maupun yang tidak diamati oleh pihak luar yang dapat melakukan sebuah proses perubahan didalam kepribadian siswa tersebut dan perubahan tersebut ditampakkan dalam bentuk peningkatan kualitas dan kuantitas tingkah laku siswa tersebut.
2.1.2 Data
Data merupakan kumpulan fakta atau angka atau segala sesuatu yang dapat dipercaya kebenarannya sehingga dapat digunakan sebagai dasar penarikkan kesimpulan. Data dapat dikelompokkan dalam beberapa golongan antara lain berdasarkan aspek sifat, dimensi waktu, cara memperoleh dan pengukurannya (Muhidin, 2009).
Ditinjau dari aspek angka, data digolongkan menjadi 2, yaitu :
a. Data diskrit, yaitu data yang satuannya mengenai bilangan bulat dan tidak berbentuk pecahan. Contohnya data mengenai jumlah mahasiswa pada sebuah PTN di Medan.
b. Data kontiniu, yaitu data yang satuannya merupakan bilangan pecahan. Contohnya data mengenai rata-rata tinggi badan mahasiswa Matematika USU.
Ditinjau dari aspek waktu, data digolongkan menjadi 2, yaitu :
a. Data time series,yaitu data yang dikumpulkan pada waktu tertentu yang dapat menggambarkan keadaan atau karakteristik objek pada saat penelitian dilakukan. Contohnya data jumlah mahasiswa Matematika USU pada tahun 2008.
2.1.3 Variabel
Variabel adalah suatu sebutan yang dapat diberi angka ( kuantitatif) atau nilai mutu (kualitatif). Variabel merupakan pengelompokkan secara logis dari dua atau lebih atributdari objek yang diteliti. Misalnya: tidak sekolah, tidak tamat SD, tidak tamat SMP, dan sebagainya. Maka variabelnya adalah tingkat pendidikan dari objek penelitian itu.Variabel tingkat pendidikan merangkum semua atribut tadi.
Variabel merupakan suatu istilah yang berasal dari kata vary dan able yang berarti “berubah” dan “dapat”. Jadi, kata variabel berarti dapat berubah-ubah.Nilai itu berupa nilai kuantitatif maupun kualitatif.Dilihat dari segi nilainya, variabel dibedakan atas 2, yaitu variabel diskrit dan variabel kontiniu.Variabel diskritnya nilai kuantitatifnya selalu berupa bilangan bulat, sedangkan variabel kontiniu nilai kuantitatifnya bisa berupa pecahan.(http://rakim-ypk.blogspot.com).
Variabel penelitian pada dasarnya adalah segala sesuatu yang berbentuk apa saja yang ditetapkan oleh peneliti untuk dipelajari sehingga diperoleh informasi tentang hal tersebut, kemudian ditarik kesimpulannya, (Sugiyono, 2007).
Menurut hubungan antara suatu variabel dengan variabel lainnya, variabel terbagi atas beberapa yaitu :
1. Variabel bebas (independent variable) yaitu variabel yang menjadi sebab terjadinya atau terpengaruhnya variabel tak bebas.
2. Variabel tak bebas (dependent variable) yaitu variabel yang nilainya dipengaruhi oleh variabel bebas.
3. Variabel moderator yaitu variabel yang memperkuat atau memperlemah hubungan antara suatu variabel bebas dengan tak bebas.
4. Variabel intervening, seperti halnya variabel moderator, tetapi nilainya tidak dapat diukur, seperti kecewa, marah, gembira, senang, sedih, dan lain sebagainya.
2.2 Analisis Multivariate
Analisis statistik multivariat merupakan metode statistik yang memungkinkan kita melakukan penelitian terhadap lebih dari dua variable secara bersamaan.Dengan menggunakan teknik analisis ini maka kita dapat menganalisis pengaruh beberapa variable terhadap variabel – (variable) lainnya dalam waktu yang bersamaan.Contoh kita dapat menganalisis pengaruh variable kualitas produk, harga dan saluran distribusi terhadap kepuasan pelanggan. Contoh yang lain, misalnya pengaruh kecepatan layanan, keramahan petugas dan kejelasan memberikan informasi terhadap kepuasan dan loyalitas pelanggan. Analisis multivariat digunakan karena pada kenyataannnya masalah yang terjadi tidak dapat diselesaikan dengan hanya menghubung-hubungkan dua variable atau melihat pengaruh satu variable terhadap variable lainnya.Sebagaimana contoh di atas, variable kepuasan pelanggan dipengaruhi tidak hanya oleh kualitas produk tetapi juga oleh harga dan saluran distribusi produk tersebut.
Teknik analisis multivariat secara dasar diklasifikasi menjadi dua, yaitu analisis dependensi dan analisis interdependensi.Analisis dependensi berfungsi untuk menerangkan atau memprediski variable (variable) tergantung dengan menggunakan dua atau lebih variable bebas.Yang termasuk dalam klasifikasi ini ialah analisis regresi linear berganda, analisis diskriminan, analisis varian multivariate (MANOVA), dan analisis korelasi kanonikal.
bersifat metrik, maka teknik analisisnya digunakan analisis multivariate varian.Jika variable tergantung lebih dari satu dan pengukurannya bersifat non-metrik, maka teknik analisisnya digunakan analisis conjoint.Jika variable tergantung dan bebas lebih dari satu dan pengukurannya bersifat metrik atau non metrik, maka teknik analisisnya digunakan analisis korelasi kanonikal.Contoh umum untuk metode dependensi, misalnya memprediski laba perusahaan dengan menggunakan biaya promosi dan harga produk.Metode interdependensi diklasifikasikan didasarkan pada jenis masukan variable dengan skala pengukuran bersifat metrik atau non metrik.Jika masukan data berskala metrik, maka kita dapat menggunakan teknik analisis faktor, analisis kluster dan multidimensional scaling.Jika masukan data berskala non-metrik, maka kita hanya dapat menggunakan teknik analisis multidimensional scaling. Analisis depedensi dibagi menjadi 4, yakni, analisis regresi berganda, analisis diskriminan, analisis multivariate varian, analisis conjoint dan analisis korelasi kanonikal .
2.3 Analisis Korelasi dan Determinasi
Korelasi merupakan teknik analisis yang termasuk dalam salah satu teknik pengukuran asosiasi / hubungan (measures of association). Pengukuran asosiasi merupakan istilah umum yang mengacu pada sekelompok teknik dalam statistik bivariat yang digunakan untuk mengukur kekuatan hubungan antara dua variabel.Diantara sekian banyak teknik-teknik pengukuran asosiasi, terdapat dua teknik korelasi yang sangat populer sampai sekarang, yaitu Korelasi Pearson ProductMoment dan Korelasi Rank Spearman. Selain kedua teknik tersebut, terdapat pula teknik-teknik korelasi lain, seperti Kendal, Chi-Square, Phi Coefficient, Goodman-Kruskal, Somer, dan Wilson.
atau hubungan antara variabel bebas dengan variabel tak bebas atau bisa juga antara variabel bebas dengan variabel bebas. Berikut ini jenis-jenis rumus Analisis Korelasi yang sering dipergunakan
2.3.1 Korelasi untuk Skala Pengukuran Interval
Koefisien korelasi untuk dua buah variabel x dan y yang kedua-duanya memiliki tingkat pengukuran interval, dapat dihitung dengan menggunakan korelasi product moment atau product moment Coefficent (Pearson’s Coefficien of Corellation) yang dikembangkan oleh Carl Pearson.Perbedaan dengan korelasi Spearman adalah, pada korelasi Spearman yang dikorelasikan adalah data peringkatnya atau rangking, sementara pada korelasi product moment data observasinya yang dikorelasikan
(Connover, 1999).
Koefisien korelasi product moment dapat diperoleh dengan rumus :
, =
n = banyaknya ukuran sampel
= ′ ′
( ′2)( ′2)
dengan nol (0), maka terdapat ketergantungan antara dua variabel tersebut. Jika koefesien korelasi diketemukan +1. maka hubungan tersebut disebut sebagai korelasi sempurna atau hubungan linear sempurna dengan kemiringan (slope) positif.
Jika koefesien korelasi diketemukan -1. maka hubungan tersebut disebut sebagai korelasi sempurna atau hubungan linear sempurna dengan kemiringan (slope) negatif. Dalam korelasi sempurna tidak diperlukan lagi pengujian hipotesis, karena kedua variabel mempunyai hubungan linear yang sempurna.Artinya variabel X
mempengaruhi variabel Y secara sempurna. Jika korelasi sama dengan nol (0), maka tidak terdapat hubungan antara kedua variabel tersebut. Dalam korelasi sebenarnya tidak dikenal istilah variabel bebas dan variabel tergantung.Biasanya dalam penghitungan digunakan simbol X untuk variabel pertama dan Y untuk variabel kedua.Dalam contoh hubungan antara variabel remunerasi dengan kepuasan kerja, maka variabel remunerasi merupakan variabel X dan kepuasan kerja merupakan variabel Y.
Koefesien korelasi ialah pengukuran statistik kovarian atau asosiasi antara dua variabel.Besarnya koefesien korelasi berkisar antara +1 s/d -1.Koefesien korelasi menunjukkan kekuatan (strength) hubungan linear dan arah hubungan dua variabel acak.Jika koefesien korelasi positif, maka kedua variabel mempunyai hubungan searah. Artinya jika nilai variabel X tinggi, maka nilai variabel Yakan tinggi pula. Sebaliknya, jika koefesien korelasi negatif, maka kedua variabel mempunyai hubungan terbalik. Artinya jika nilai variabel X tinggi, maka nilai variabel Yakan menjadi rendah (dan sebaliknya). Untuk memudahkan melakukan interpretasi mengenai kekuatan hubungan antara dua variabel penulis memberikan kriteria sebagai berikut (Sarwono:2006):
0 : Tidak ada korelasi antara dua variabel
0.01 – 0,25: Korelasi sangat lemah
0,26 – 0,50: Korelasi cukup
0,51 – 0,75: Korelasi kuat
0,76 – 0,99: Korelasi sangat kuat
Secara umum kita menggunakan angka signifikansi sebesar 0,01; 0,05 dan 0,1. Pertimbangan penggunaan angka tersebut didasarkan pada tingkat kepercayaan (confidence interval) yang diinginkan oleh peneliti. Angka signifikansi sebesar 0,01 mempunyai pengertian bahwa tingkat kepercayaan atau bahasa umumnya keinginan kita untuk memperoleh kebenaran dalam riset kita adalah sebesar 99%. Jika angka signifikansi sebesar 0,05, maka tingkat kepercayaan adalah sebesar 95%. Jika angka signifikansi sebesar 0,1, maka tingkat kepercayaan adalah sebesar 90%.Pertimbangan lain ialah menyangkut jumlah data (sampel) yang akan digunakan dalam riset. Semakin kecil angka signifikansi, maka ukuran sampelakan semakin besar. Sebaliknya semakin besar angka signifikansi, maka ukuran sample akan semakin kecil. Unutuk memperoleh angka signifikansi yang baik, biasanya diperlukan ukuran sample yang besar.Sebaliknya jika ukuran sampel semakin kecil, maka kemungkinan munculnya kesalahan semakin ada.
Untuk pengujian dalam SPSS digunakan kriteria sebagai berikut:
o Jika angka signifikansi hasil riset < 0,05, maka hubungan kedua variabel
signifikan.
o Jika angka signifikansi hasil riset > 0,05, maka hubungan kedua variabel
tidak signifikan
Ada tiga penafsiran hasil analisis korelasi, meliputi: pertama, melihat kekuatan hubungan dua variabel; kedua, melihat signifikansi hubungan; dan ketiga, melihat arah hubungan. Untuk melakukan interpretasi kekuatan hubungan antara dua variabel dilakukan dengan melihat angka koefesien korelasi hasil perhitungan dengan menggunakan kriteria sebagai berikut:
Jika angka koefesien korelasi menunjukkan 0, maka kedua variabel tidak mempunyai hubungan
Jika angka koefesien korelasi mendekati 0, maka kedua variabel mempunyai hubungan semakin lemah
Jika angka koefesien korelasi sama dengan 1, maka kedua variabel mempunyai hubungan linier sempurna positif.
Jika angka koefesien korelasi sama dengan -1, maka kedua variabel mempunyai hubungan linier sempurna negatif.
2.3.2 Determinasi untuk Skala Pengukuran interval
Koefisien determinasi (dinotasikan dengan R2) adalah sebuah kunci penting dalam analisis regresi. Nilai koefisien determinasi diinterpretasikan sebagai proporsi dari varian variable dependen, bahwa variabel dependen dapat dijelaskan oleh variabel independen sebesar nilai koefisien determinasi tersebut.
• Jika koefisien korelasi berganda dikuadratkan, diperoleh koefisien determinasi berganda yang disimbolkan dengan R2.
• Koefisien determinasi digunakan untuk mengukur besarnya sumbangan atau pengaruh dari beberapa variabel X (X1, X2, X3, ..., Xn) terhadap naik turunnya (variasi perubahan) variabel Y.
• Jika nilai koefisien determinasi dikalikan 100%, diperoleh persentase sumbangan variabel variabel X terhadap naik turunnya (variasi perubahan) variabel Y.
Koefisien determinasi dapat diperoleh dengan rumus :
2 = ,
2
Dimana :
2 = koefisien determinasi
2.4. Uji-Uji Dalam Statistik
2.4.1 Uji Kecukupan Sampel
Dilakukan dengan mencari banyaknya data yang diperlukan sesuai dengan ketelitian yang diinginkan.Uji kecukupan data ini perlu dilakukan untuk mengetahui apakah sampel data yang diambil sudah mencukupi untuk mewakili sampel data populasi.
Rumus yang digunakan dalam uji kecukupan data ini adalah :
′ = − 2 2
Dimana :
s = tingkat ketelitian (%)
k = nilai tingkat kepercayaan dari distribusi normal (%)
= data pengamatan
N = jumlah pengamatan atau pengukuran yang telah dilaksanakan
′ = banyaknya data yang diperlukan dengan tingkat kepercayaan yang
diinginkan.
2.4.2 Uji Validitas
dan 0,01. Tinggi rendahnya validitas instrumen akan menunjukkan sejauh mana data yang terkumpul tidak menyimpang dari gambaran tentang variabel yang dimaksud.
Adapun perhitungan korelasi product moment, dengan rumus seperti yang dikemukakan oleh Arikunto (1998):
Dimana:
r = Koefisien korelasi
n = Banyaknya sampel
x = Skor masing-masing item
y = Skor total variabel
Item Instrumen dianggap Valid jika lebih besar dari 0,3 atau bisa juga dengan membandingkannya dengan r tabel. Jika r hitung > r tabel maka valid.
2.4.3 Uji Reabilitas
Uji reliabilitas berguna untuk menetapkan apakah instrumen yang dalam hal ini kuesioner dapat digunakan lebih dari satu kali, paling tidak oleh responden yang sama akan menghasilkan data yang konsisten. Dengan kata lain, reliabilitas instrumen mencirikan tingkat konsistensi. Banyak rumus yang dapat digunakan untuk mengukur reliabilitas diantaranya adalah rumus Spearman Brown
11 =
Ket :
11adalah nilai reliabilitas
adalah nilai koefisien korelasi
Nilai koefisien reliabilitas yang baik adalah diatas 0,7 (cukup baik), di atas 0,8 (baik).
Pengukuran validitas dan reliabilitas mutlak dilakukan, karena jika instrument yang digunakan sudah tidak valid dan reliable maka dipastikan hasil penelitiannya pun tidak akanvalid dan reliable.Sugiyono (2007: 137) menjelaskan perbedaan antara penelitian yang valid dan reliable dengan instrument yang valid dan reliable sebagai berikut :
Penelitian yang valid artinya bila terdapat kesamaan antara data yang terkumpul dengan data yang sesungguhnya terjadi pada objek yang diteliti.Artinya, jika objek berwarna merah, sedangkan data yang terkumpul berwarna putih maka hasil penelitian tidak valid.Sedangkan penelitian yang reliable bila terdapat kesamaan data dalam waktu yang berbeda.Kalau dalam objek kemarin berwarna merah, maka sekarang dan besok tetap berwarna merah.
2.5 Analisis Regresi
Analisis regresi adalah teknik statistika yang berguna untuk mengukur besarnya pengaruh variabel bebas tehadap variabel tak bebas dan memprediksi variabel tak bebas dengan menggunakan variabel bebas. Menurut Gujarati (2006), analisis regresi didefinisikan sebagai kajian terhadap hubungan satu variabel yang disebut variabel diterangkan (the explained variable) dengan satu atau dua variabel yang menerangkan
maka analisis regresi tersebut disebut analisis regresi linear berganda. Dikatakan berganda karena pengaruh beberapa variabel bebas akan dikenakan kepada variabel tak bebasnya.
Jika 1, 2,… , adalah variabel bebas dan Y adalah variabel tak bebas, maka terdapat hubungan fungsional antara X dan Y, dimana variasi dari X akan diiringi pula oleh variasi dari Y. Secara matematik hubungan diatas dapat kita tuliskan sebagai berikut : = ( 1, 2,…, , )
dimana :
Y = variabel tak bebas atau terikat
x = variabel bebas
e = variabel residu ( disturbance term)
Berhubungan dengan analisis regresi ini, setidaknya ada 4 yang harus dilakukan dalam analisis regresi agar diperoleh hasil analisis regresi yang valid diantaranya :
o Mengadakan estimasi terhadap parameter berdasarkan data empiris,
o menguji berapa besar variansi variabel tak bebas dapat diterangkan oleh variansi variabel bebas,
o menguji apakah estimasi parameter tersebut signifikan atau tidak, dan
2.5.1 Analisis Regresi Sederhana dan Berganda
Dalam analisis regresi, regresi sederhana bertujuan untuk mempelajari hubungan antara dua variabel yakni variabel bebas dan tak bebas. Model regresi sederhana adalah ŷ= + dimana ŷ adalah variabel tak bebas atau terikat, x adalah variabel bebas, a adalah penduga bagi intersap (α), b adalah koefisien penduga bagi keofisien regresi (β) serta α, β adalah parameter yang nilainya tidak diketahui sehinnga diduga menggunakan sampel statistik, (Triola,2005).
Rumus yang dapat digunakan untuk mencari a dan b adalah sebagai berikut:
= ( )(
2)−( )( )
2−( )2
= ( 2)−
−( )2 = 2
dimana :
a= penduga intersap (α)
b= penduga koefisien regresi (β)
X = variabel bebas
Y = variabel tak bebas
Dalam regresi linear berganda variabel tak bebas y bergantung pada dua atau lebih variabel bebas. Mungkin terdiri dari beberapa variabel bebas, misalnya : 1, 2,… , . Hubungan seperti ini dicari dengan menggunakan analisis regresi
berganda dengan bentuk umum sebagai berikut :
dengan :
=
, 1, 2,…, =
1, 2,…, = =
Berdasarkan rumus diatas maka diperoleh :
= + 1 1 + 2 2
1 = 1+ 1 12+ 2 1 2
2 = 2+ 1 1 2+ 2 22
Dan untuk rumus keofisien korelasi bergandanya :
= 1 1 +22 2
2.6. Analisis Diskriminan
Analisis Analisis Diskriminan merupakan salah satu teknik menganalisis dalam analisis multivariate.diskriminan merupakan teknik menganalisis data, kalau variabel tak bebas (disebut criterion) merupakan kategori (non-metrik, nominal atau ordinal,bersifat kualitatif) sedangkan variabel bebas sebagai prediktor merupakan metrik (interval atau rasio, bersifat kuantitatif). Analisis diskriminan terkadang mirip dengan regresi linier berganda hanya saja perbedaannya, pada regresi linier berganda variabel tak bebasnya harus metrik dan variabel bebasnya bisa metrik maupun nonmetrik.Sedangkan persamaannya terletak pada variabel tak bebasnya hanya satu sedangkan variabel tak bebasnya banyak.(Simamora,2005)
Analisis diskriminan adalah metode statistik untuk mengelompokkan atau mengklasifikasikan sejumlah obyek ke dalam beberapa kelompok, berdasarkan beberapa variabel, sedemikian hingga setiap obyek yang menjadi anggota lebih dari pada satu kelompok.Pada prinsipnya analisis diskriminan bertujuan untuk mengelompokkan setiap obyek ke dalam dua atau lebih kelompok berdasarkan pada criteria sejumlah variabel bebas.Teknik analisis diskriminan dibedakan menjadi dua yaitu analisis diskriminan dua kelompok atau kategori, kalau variabel tak bebas Y dikelompokkan menjadi dua.Diperlukan satu fungsi diskriminan. Kalau variabel tak bebas dikelompokkan menjadi lebih dari dua kelompokdisebut analisis diskriminan berganda ( multiple discriminant analysis) diperlukan fungsi diskriminan sebanyak ( k – 1 ) kalau memang ada k kategori.
Model analisis diskriminan berkenaan dengan kombinasi linear yang bentuknya sebagai berikut.
= + 1 1+ 2 2+ 3 3+ + + +
= nilai (skor) diskriminan dari responden (objek) ke-i. i = 1, 2, …, n. D merupakan variabel tak bebas.
= koefisien atau timbangan diskriminan dari variabel atau atribut ke j. = koefisien atau timbangan diskriminan dari variabel atau atribut ke k.
= variabel bebas atau prediktor ke j dari responden ke i, juga disebut atribut, seperti disebutkan diatas.
= variabel (atribut) ke-k dari responden ke-i.
Pada prinsipnya analisis diskriminan bertujuan untuk mengelompokkan setiap objek ke dalam dua atau lebih kelompok berdasar pada criteria sejumlah variabel bebas. Pengelompokkan ini bersifat mutually exclusive, dalam artian jika objek A sudah masuk kelompok 1, maka ia tidak mungkin juga dapat menjadi anggota kelompok 2. Oleh karena itu, ciri lain analisis diskriminan adalah jenis data dari varaiabel dependent bertipe nominal (kategori), seperti kode 0 dan 1, atau kode 1, 2 dan 3 serta kombinasi lainnya (Santoso, Tjiptono, 2001).
2.6.1 Syarat-Syarat dan Tujuan Analisis Diskriminan
Bentuk multivariate dari analisis diskriminan adalah terikat sehinnga variabel tak bebas adalah variabel yang mendasari analisis diskriminan.Variabel tak bebas bisa berupa kode grup 1 atau grup 2 atau lainnya.(Santoso,2010)
Pada umumnya proses dasar dari analisis diskriminan dibagi atas beberapa bagian, yakni :
- Memisahkan variabel-variabel menjadi variabel bebas dan variabel terikat. - Menentukan metode untuk membuat Fungsi Diskriminan.
Pada prinsipnya ada dua metode dasar untuk itu, yakni:
a) Stimulation Estimation, dimana semua variabel dimasukkan secara bersama-sama kemudian dilakukan proses analisis diskriminan.
tetap ada pada model dan ada kemungkinan satu atau lebih variabel bebas yang akan dibuang dari model.
- Menguji signifikasi dari fungsi diskriminan yang telah terbentuk dengan menggunakan :
1) Angka Wilk’s Lambda, angka ini berkisar antara 0 dan 1. Semakin mendekati 0 berarti data tiap kelompok makin berbeda, sedangkan semakin mendekati angka 1 berarti data tiap kelompok cenderung sama.
2) F Test, dengan batasan signifikan 0,05, jika signifikan > 0.05 berarti tidak ada perbedaan antar kelompok. Jika signifikan < 0.05 berarti ada perbedaan antar kelompok.
- Menguji ketepatan klasifikasi dari Fungsi Diskriminan serta termasuk mengetahui ketepatan klasifikasi secara individual dengan Casewise Diagnostics.
- Melakukan interpretasi dari fungsi diskriminan tersebut. - Melakukan uji validitas fungsi diskriminan.
-Secara umum, tujuan diskriminan ada 4, yaitu :
1. Ingin mengetahui apakah ada perbedaan yang jelas antar-grup pada variabel terikat? Atau bisa dikatakan apakah ada perbedaan antara anggota Grup 1 dengan anggota grup lainnya?
2. Jika terjadi perbedaan, variabel bebas manakah pada fungsi diskriminan yang membuat perbedaan tersebut?
3. Membuat fungsi atau model diskriminan, yang pada dasarnya mirip dengan persamaan regresi.
4. Melakukan klasifikasi terhadap objek, apakah suatu objek termasuk pada grup tersebut atau masuk ke dalam grup lainnya.
2.6.2 Algoritma Pokok Analisis Diskriminan dan Model Matematis
Secara ringkas, langkah-langkah dalam analisis diskriminan adalah sebagai berikut:
1. Pengecekan adanya kemungkinan hubungan linier antara variabel penjelas.Untuk point ini, dilakukan dengan bantuan matriks korelasi (pembentukan matriks korelasi sudah difasilitasi pada analisis diskriminan). Pada output SPSS, matriks korelasi bisa dilihat pada Pooled Within-Groups Matrices.
2. Uji Vektor Rata-rata Kedua Kelompok
Ho: µ1 =µ2
H1: µ1 ≠µ2
Angka signifikan :
Jika Sig > 0,05 maka tidak ada perbedaan antar grup
Jika Sig < 0,05 maka ada perbedaan antar grup
Diharapkan dari uji ini adalah hipotesis nol ditolak, sehingga kita mempunyai informasi awal bahwa variabel yang sedang diteliti memang membedakan kedua kelompok. Pada SPSS, uji ini dilakukan secara univariate (jadi yang diuji bukan berupa vektor), dengan bantuan tabel Tests of Equality of Group Means.
3. Dilanjutkan pemeriksaan asumsi homoskedastisitas, dengan uji Box’s M. Diharapkan dari uji ini hipotesisi nol tidak ditolak ( Ho: Σ1= Σ2).
Hipotesis :
�0 : matriks kovarians grup adalah sama
�1 : matriks kovarians grup adalah berbeda secara nyata
Keputusan dengan dasar signifikasi bias dilihat dari angka signifikannya
Jika Sig > 0,05 berarti �0 diterima
Sama tidaknya grup kovarians matriks juga bias dilihat dari table output Log Determinant. Jika dalam pengujian ini �0 ditolak maka proses selanjutnya tidak dapat dilakukan.
4. Pembentukan model diskriminan
a.Kriteria Fungsi Linier Fisher
Pembentukan Fungsi Linier (teoritis)
Fisher mengelompokkan suatu observasi berdasarkan nilai skor yangdihitung dari suatu fungsi linier = �′ dimana λ menyatakan vektor yang berisi koefisien-koefisien variabel penjelas yang membentuk persamaan linier terhadap variabel respon, �′ = �1,�2,…,� .
= 1
2
,
menyatakan matriks data pada kelompok ke-k.
=
, , menyatakan observasi ke-i variabel ke-j pada kelompok ke-k.
µ = µ1,
µ ,
µ adalah vektor rata-rata tiap variabel X pada kelompok ke-k.
� = multivariate menjadi observasi y yang univariate. Dari persamaan diperoleh : = �′
µ = = �′ = �′µ �2 = �′ =�′ �
µ adalah rata-rata Y yang diperoleh X yang termasuk dalam kelompok ke-k.
�2adalah varians Y dan diasumsikan sama untuk kedua kelompok.
Kombinasi linier yang terbaik menurut Fisher adalah yang dapat memaksimumkan rasio antara jarak kuadrat rata-rata Y yang diperoleh dari x dari kelompok 1 dan 2 dengan varians Y, atau dirumuskan
adalah matriks definit positif maka teori pertidaksamaan Cauchy-Schartz,rasio �′
2
�′ � dapat dimaksimumkan jika �′ = −1 =
−1 µ
1−µ2 dengan memilih c = 1, menghasilkan kombinasi linier
= �′ = µ −µ ′ −
b. Pembentukan Fungsi Linier (dengan bantuan SPSS)
Pada output SPSS, koefisien untuk tiap variabel yang masuk dalam model dapat dilihat pada tabel Canonical Discriminant Function Coefficient. Tabel ini akan dihasilkan pada output apabila pilihan Function Coefficient
bagian Unstandardized diaktifkan.
c.MenghitungDiscriminant Score(nilai diskriminan)
Setelah dibentuk fungsi liniernya, maka dapat dihitung skor diskriminan untuk tiap observasi dengan memasukkan nilai-nilai variabel penjelasnya.
d. Menghitung Cutting Score
Untuk memprediksi responden mana masuk golongan mana, kita dapat menggunakan optimum cutting score.Memang dari komputer informasi ini sudah kita peroleh. Sedangkan cara mengerjakan secara manual Cutting Score (m) dapat dihitung dengan rumus sebagai berikut dengan ketentuan untuk dua grup yang mempunyai ukuran yang sama cutting score dinyatakan dengan rumus, ( Simamora, 2005) :
= +
2
Dengan :
= cutting score untuk grup yang sama ukuran
= centroid grup A
= centroid grup B
= + +
Dengan :
= cutting score untuk grup tak sama ukuran
= jumlah anggota grup A
= jumlah anggota grup B
= centroid grup A
= centroid grup B
Kemudian nilai-nilai discriminant score tiap observasi akan dibandingkan dengan cutting score, sehingga dapat diklasifikasikan suatu observasi akan termasuk kedalam kelompok yang mana. Suatu observasi dengan karakteristik x akan diklasifikasikan sebagai anggota kelompok kode 1 jika = µ −µ ′ − � ≥ �, selain itu dimasukkan dalam kelompok 2 (kode nol) perhitungan m dilakukan secara manual, karena SPSS tidak mengeluarkan output m. Namun dapat dihitung nilai m dengan bantuan table Function at Group Centroids dari outputs SPSS.
e. Penghitungan Hit Ratio
linier ini akan diprediksi keanggotaannya dengan fungsi yang sudah dibentuk tadi. Proses ini akan diulang dengan kombinasi observasi yang berbeda-beda, sehingga fungsi linier yang dibentuk ada sebanyak n. Inilah yang disebut dengan metode Leave One Out.
f. Kriteria Posterior Probability
Aturan pengklasifikasian yang ekivalen dengan model linier Fisher adalah berdasarkan nilai peluang suatu observasi dengan karakteristik tertentu (x)
berasal dari suatu kelompok. Nilai peluang ini disebut posterior probability dan bisa ditampilkan pada sheet SPSS dengan mengaktifkan option probabilities of groupmembership pada bagian Save di kotak dialog utama.
⃓ =
′
Dimana :
−
= 1
2� ⃓ ⃓12
−12 −µ ′ −1 −µ ; = 0,1
Suatu observasi dengan karakteristik x akan diklasifikasikan sebagai anggota kelompok 0 jika = ⃓ > = ⃓ . Nilai-nilai posterior probability
inilah yang mengisi kolom di 1,1 dan kolom di 1,2 pada sheet SPSS.
g. Akurasi Statistik
dengan nilai kritis (critical value) yang diambil dari table Chi-Square dan tingkat keyakinan sesuai yang diinginkan. Statistik Q ditulis dengan rumus :
− = − �
2
� −1
Dengan :
N = ukuran total sampel
n = jumlah kasus yang dikalsifikasikan secara tepat
BAB 3
HASIL DAN PEMBAHASAN
3.1Latar Belakang
3.1.1 Data Hasil Kuisioner
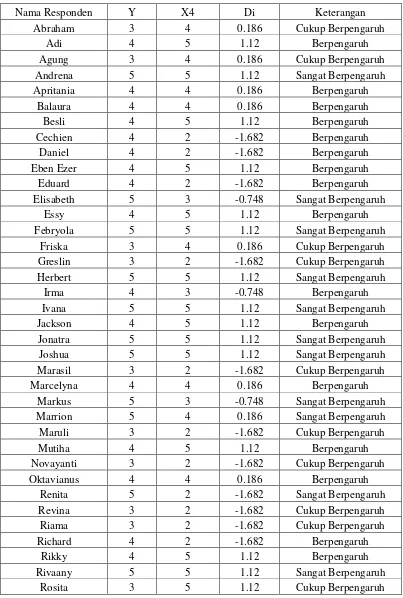
Berikut ini adalah data-data dari siswa/i SMA Kristen Immanuel Medan Kelas XII IA dimana data-data ini diperoleh dari hasil kuisioner yang diisi para siswa/i. Data-data ini meliputi nama siswa, seberapa besar pengaruh perilaku belajar siswa terhadap diri mereka, lama belajar disekolah dan diluar sekolah serta frekuensi tugas yang diberi disekolah dan yang mereka selesaikan.
Di bawah ini skema penelitian yang menunjukkan variabel bebas dan variabel tak bebas:
Cukup Mempengaruhi Variabel tak bebas
Mempengaruhi Data
Nilai Rata-rata Siswa Variabel Bebas Lama Belajar di Sekolah
Adapun data-data tersebut setelah dimasukkan kedalam tabel sebagai berikut :
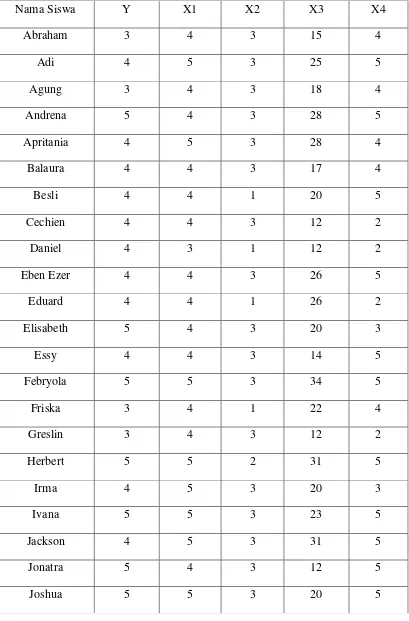
Tabel 3.1 Data-data Responden Berupa Faktor Perilaku Belajar
Nama Siswa Y X1 X2 X3 X4
Abraham 3 4 3 15 4
Adi 4 5 3 25 5
Agung 3 4 3 18 4
Andrena 5 4 3 28 5
Apritania 4 5 3 28 4
Balaura 4 4 3 17 4
Besli 4 4 1 20 5
Cechien 4 4 3 12 2
Daniel 4 3 1 12 2
Eben Ezer 4 4 3 26 5
Eduard 4 4 1 26 2
Elisabeth 5 4 3 20 3
Essy 4 4 3 14 5
Febryola 5 5 3 34 5
Friska 3 4 1 22 4
Greslin 3 4 3 12 2
Herbert 5 5 2 31 5
Irma 4 5 3 20 3
Ivana 5 5 3 23 5
Jackson 4 5 3 31 5
Jonatra 5 4 3 12 5
Marasil 3 5 3 15 2
Marcelyna 4 4 3 15 4
Markus 5 4 3 12 3
Marrion 5 4 3 25 4
Maruli 3 3 3 25 2
Mutiha 4 5 3 21 5
Novayanti 3 4 3 12 2
Oktavianus 4 4 3 12 4
Renita 5 5 3 25 5
Revina 3 3 3 12 2
Riama 3 3 3 12 2
Richard 4 2 3 12 2
Rikki 4 3 3 12 5
Rivaany 5 4 3 12 5
Rosita 3 5 3 20 5
Rumiris 3 5 1 12 2
Rustam 4 4 3 12 4
Ruth 4 5 3 17 5
Santa Christy 3 4 3 25 3
Sarah 4 4 2 21 4
Sarah Sianturi 4 4 3 20 5
Sisca 4 5 3 14 3
Theresia 5 3 1 12 2
Wike 5 4 3 25 4
Keterangan :
= Pengaruh perilaku belajar terhadap siswa tersebut
1 = Nilai rata-rata siswa di kelas XI dan XII
2 = Lama siswa belajar di sekolah berupa les tambahan
3 = Lama siswa belajar di luar sekolah
4 = Frekuensi tugas dari sekolah dan diselesaikan.
3.2 Pengujian Data dengan Menggunakan Uji-Uji Statistik
Sebelum data-data yang kita peroleh dari hasil kuisioner kita olah atau proses.Dan maksud dari pengujian ini salah satunya untuk menguji kevalidan data kita tersebut. Terlebih dahulu kita akan menguji data-data tersebut dengan menggunakan bantuan berupa uji-uji statistik dimana uji-uji ini sudah dijamin ke akuratannya., yakni :
3.2.1 Uji Kecukupan Sampel
Dilakukan dengan mencari banyaknya data yang diperlukan sesuai dengan ketelitian yang diinginkan.Uji kecukupan data ini perlu dilakukan untuk mengetahui apakah sampel data yang diambil sudah mencukupi untuk mewakili sampel data populasi.
Karena banyak populasi yang akan diteliti pada penelitian ini dibawah dari 100 orang atau lebih tepatnya 70 orang. Maka untuk memnenuhi kecukupan sampelnya
Yohannes Ivan 4 4 3 12 4
Yudika 4 4 3 15 4
maka penelitian ini cukup mengambil sampel sebanyak 3
4 dari populasinya yakni lebih
tepatnya 50 orang sebagai responden.Sebab 50 orang responden sudah cukup mewakili dari semua anggota populasinya karena populasinya bersifat homogen.
3.2.2. Uji Validitas
Uji validitas dilakukan untuk mengetahui tingkat kevalidan dari instrumen (kuesioner) yang digunakan dalam pengumpulan data yang diperoleh dengan cara mengkorelasi setiap skor variabel jawaban responden dengan total skor masing-masing variabel, kemudian hasil korelasi dibandingkan dengan nilai kritis pada taraf siginifikan 0,05 dan 0,01. Tinggi rendahnya validitas instrumen akan menunjukkan sejauh mana data yang terkumpul tidak menyimpang dari gambaran tentang variabel yang dimaksud.
Mode
Dengan menggunakan rumus Brown yakni :
11 =
2 1 +
Maka kita akan mendapat nilai reabilitasnya yakni :
11 =
2
1 + =
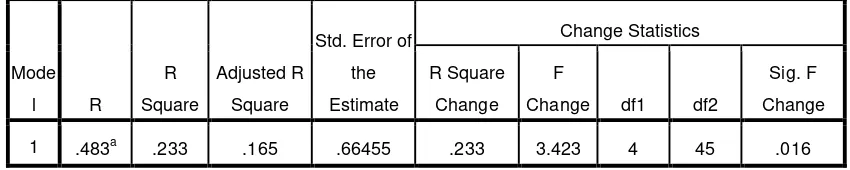
2 0.483
1 + 0.483= 0.65≃0.7
Jadi, item istrumen yang digunakan pada penelitian ini cukup baik untuk dapat digunakan lebih dari satu kali, paling tidak oleh responden yang sama maka akan menghasilkan data yang konsisten.
3.3Pengolahan Data Dengan Analisis Regresi Berganda
Setelah data dimasukkan kedalam tabel selanjutnya kita akan menganalisis data tersebut dengan terlebih dahulu menghitung jumlah dari setiap data-data yang diperoleh. Adapun Analisis Regresi Berganda ini, kita gunakan untuk mencari koefisien untuk penduga intersep variabel tak bebas. Setelah kita mendapat nilai koefisien dari variabel tak bebasnya maka kita dapat mencari inilah diskriminan dari setiap responden.
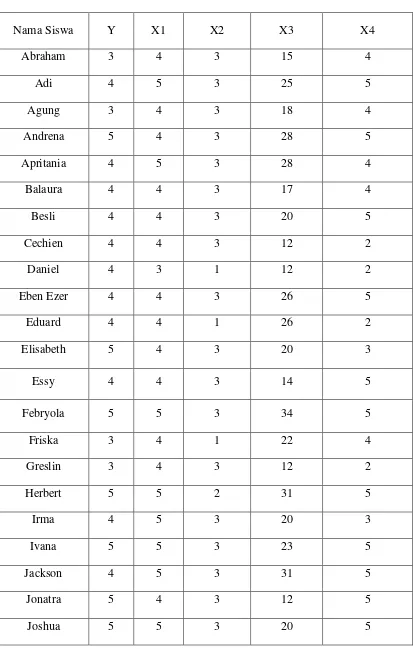
Tabel 3.2 Data Responden Setelah Diolah
Nama Siswa Y X1 X2 X3 X4
Abraham 3 4 3 15 4
Adi 4 5 3 25 5
Agung 3 4 3 18 4
Andrena 5 4 3 28 5
Apritania 4 5 3 28 4
Balaura 4 4 3 17 4
Besli 4 4 3 20 5
Cechien 4 4 3 12 2
Daniel 4 3 1 12 2
Eben Ezer 4 4 3 26 5
Eduard 4 4 1 26 2
Elisabeth 5 4 3 20 3
Essy 4 4 3 14 5
Febryola 5 5 3 34 5
Friska 3 4 1 22 4
Greslin 3 4 3 12 2
Herbert 5 5 2 31 5
Irma 4 5 3 20 3
Ivana 5 5 3 23 5
Jackson 4 5 3 31 5
Jonatra 5 4 3 12 5
Marasil 3 5 3 15 2
Marcelyna 4 4 3 15 4
Markus 5 4 3 12 3
Marrion 5 4 3 25 4
Maruli 3 3 3 25 2
Mutiha 4 5 3 21 5
Novayanti 3 4 3 12 2
Oktavianus 4 4 3 12 4
Renita 5 5 3 25 5
Revina 3 3 3 12 2
Riama 3 3 3 12 2
Richard 4 2 3 12 2
Rikki 4 3 3 12 5
Rivaany 5 4 1 12 5
Rosita 3 5 3 20 5
Rumiris 3 5 1 12 2
Rustam 4 4 3 12 4
Ruth 4 5 3 17 5
Santa Christy 3 4 3 25 3
Sarah 4 4 2 21 4
Sarah Sianturi 4 4 3 20 5
Sisca 4 5 3 14 3
Theresia 5 3 1 12 2
Wike 5 4 3 25 4
Yohannes Ivan 4 4 3 12 4
Yudika 4 4 3 15 4
Yuni 5 4 3 26 5
Jumlah 202 205 132 931 190
Berikut ini adalah nilai-nilai dari jumlah-jumlah dari setiap variabel tak bebas maupun variabel bebas.
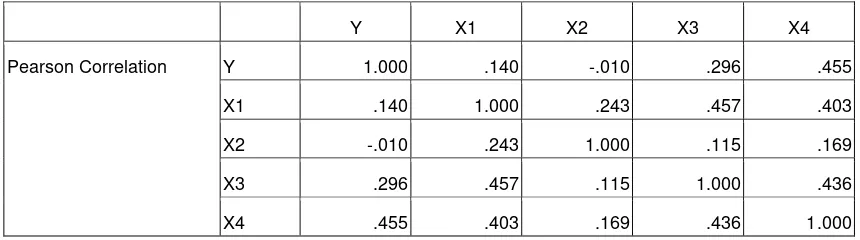
Keterangan:
� = 202; � 1 = 205; � 2 = 132 ; � 3= 931; � 4 = 190;
� 1 2 = 548; � 1 3 = 3927; � 1 4 = 797;
� 2 3= 2485; � 2 4 = 6701; � 3 4= 3631;
� 1 = 832; � 2 = 533; � 3 = 3829; � 4 = 787;
� 12 = 869; � 22 = 376; � 32 = 19361; � 42 = 792; � 2 = 842
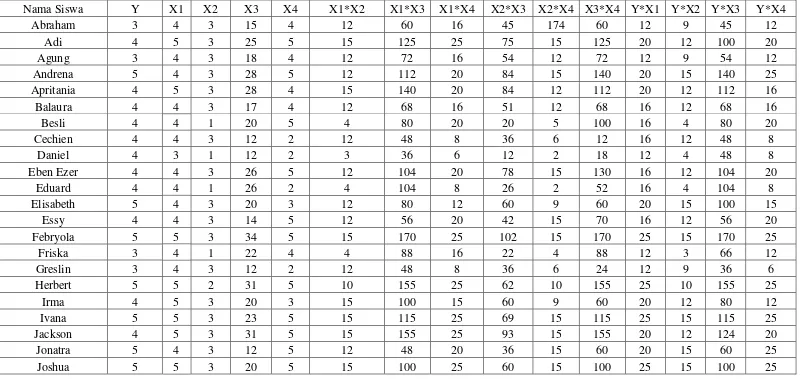
Tabel 3.3 Data Responden Hasil Pengolahan Data
Nama Siswa Y X1 X2 X3 X4 X1*X2 X1*X3 X1*X4 X2*X3 X2*X4 X3*X4 Y*X1 Y*X2 Y*X3 Y*X4
Abraham 3 4 3 15 4 12 60 16 45 174 60 12 9 45 12
Adi 4 5 3 25 5 15 125 25 75 15 125 20 12 100 20
Agung 3 4 3 18 4 12 72 16 54 12 72 12 9 54 12
Andrena 5 4 3 28 5 12 112 20 84 15 140 20 15 140 25
Apritania 4 5 3 28 4 15 140 20 84 12 112 20 12 112 16
Balaura 4 4 3 17 4 12 68 16 51 12 68 16 12 68 16
Besli 4 4 1 20 5 4 80 20 20 5 100 16 4 80 20
Cechien 4 4 3 12 2 12 48 8 36 6 12 16 12 48 8
Daniel 4 3 1 12 2 3 36 6 12 2 18 12 4 48 8
Eben Ezer 4 4 3 26 5 12 104 20 78 15 130 16 12 104 20
Eduard 4 4 1 26 2 4 104 8 26 2 52 16 4 104 8
Elisabeth 5 4 3 20 3 12 80 12 60 9 60 20 15 100 15
Essy 4 4 3 14 5 12 56 20 42 15 70 16 12 56 20
Febryola 5 5 3 34 5 15 170 25 102 15 170 25 15 170 25
Friska 3 4 1 22 4 4 88 16 22 4 88 12 3 66 12
Greslin 3 4 3 12 2 12 48 8 36 6 24 12 9 36 6
Herbert 5 5 2 31 5 10 155 25 62 10 155 25 10 155 25
Irma 4 5 3 20 3 15 100 15 60 9 60 20 12 80 12
Ivana 5 5 3 23 5 15 115 25 69 15 115 25 15 115 25
Jackson 4 5 3 31 5 15 155 25 93 15 155 20 12 124 20
Jonatra 5 4 3 12 5 12 48 20 36 15 60 20 15 60 25
Marasil 3 5 3 15 2 15 75 10 45 6 30 15 9 45 6
Marcelyna 4 4 3 15 4 12 60 16 45 12 60 16 12 60 16
Markus 5 4 3 12 3 12 48 12 36 9 27 20 15 60 15
Marrion 5 4 3 25 4 12 100 16 75 12 100 20 15 125 20
Maruli 3 3 3 25 2 9 75 6 75 6 50 9 9 75 6
Mutiha 4 5 3 21 5 15 105 25 63 15 105 20 12 84 20
Novayanti 3 4 3 12 2 12 48 8 36 6 24 12 9 36 6
Oktavianus 4 4 3 12 4 12 48 16 36 12 24 16 12 48 16
Renita 5 5 3 25 5 15 125 25 75 15 125 25 15 125 25
Revina 3 3 3 12 2 9 36 6 36 6 24 9 9 36 6
Riama 3 3 3 12 2 9 36 6 36 6 24 9 9 36 6
Richard 4 2 3 12 2 6 24 4 36 6 24 8 12 48 8
Rikki 4 3 3 12 5 9 36 15 36 15 60 12 12 48 20
Rivaany 5 4 1 12 5 4 48 20 12 5 60 20 5 60 25
Rosita 3 5 3 20 5 15 100 25 60 15 100 15 9 60 15
Rumiris 3 5 1 12 2 5 60 10 12 2 18 15 3 36 6
Rustam 4 4 3 12 4 12 48 16 36 12 24 16 12 48 16
Ruth 4 5 3 17 5 15 85 25 51 15 85 20 12 68 20
Santa Christy 3 4 3 25 3 12 100 12 75 9 75 12 9 75 9
Sarah 4 4 2 21 4 8 84 16 42 8 84 16 8 84 16
Sarah Sianturi 4 4 3 20 5 12 80 20 60 15 100 16 12 80 20
Sisca 4 5 3 14 3 15 70 15 42 9 52 20 12 56 12
Theresia 5 3 1 12 2 3 36 6 12 2 24 15 5 60 10
Wike 5 4 3 25 4 12 100 16 75 12 100 20 15 125 20
Yohannes Ivan 4 4 3 12 4 12 48 16 36 12 48 16 12 48 16
Yudika 4 4 3 15 4 12 60 16 45 12 60 16 12 60 16
Yuni 5 4 3 26 5 12 104 20 78 15 130 20 15 130 25
Jumlah 202 205 132 931 190 548 3927 797 2485 671 3631 832 533 3829 787
X1*X1 X2*X2 X3*X3 X4*X4 Y*Y X1*X2*X3 X1*X2*X4 X2*X3*X4 X1*X2*X3*X4
16 9 225 16 9 180 48 180 720
25 9 625 25 16 375 75 375 1875
16 9 324 16 9 216 48 216 864
16 9 784 25 25 336 60 420 1680
25 9 784 16 16 420 60 336 1680
16 9 289 16 16 204 48 204 816
16 1 400 25 16 80 20 100 400
16 9 144 4 16 144 24 72 288
9 1 144 4 16 36 6 24 72
16 9 676 25 16 312 60 390 1560
16 1 676 4 16 104 8 52 208
16 9 400 9 25 240 36 180 720
16 9 196 25 16 168 60 210 840
25 9 1156 25 25 510 75 510 2550
16 1 484 16 9 88 16 88 352
16 9 144 4 9 144 24 72 288
25 4 961 25 25 310 50 310 1550
25 9 400 9 16 300 45 180 900
25 9 961 25 16 465 75 465 2325
16 9 144 25 25 144 60 180 720
25 9 400 25 25 300 75 300 1500
25 9 225 4 9 225 30 90 450
16 9 225 16 16 180 48 180 720
16 9 144 9 25 144 36 108 432
16 9 625 16 25 300 48 300 1200
9 9 625 4 9 225 18 150 450
25 9 441 25 16 315 75 315 1575
16 9 144 4 9 144 24 72 288
16 9 144 16 16 144 48 144 576
25 9 625 25 25 375 75 375 1875
9 9 144 4 9 108 18 72 216
9 9 144 4 9 108 18 72 216
4 9 144 4 16 72 12 72 144
9 9 144 25 16 108 45 180 540
16 1 144 25 25 48 20 60 240
25 9 400 25 9 300 75 300 1500
25 1 144 4 9 60 10 24 120
16 9 144 16 16 144 48 144 576
25 9 289 25 16 255 75 255 1275
16 9 625 9 9 300 36 225 900
16 4 441 16 16 168 32 168 672
16 9 400 25 16 240 60 300 1200
9 1 144 4 25 36 6 24 72
16 9 625 16 25 300 48 300 1200
4 1 144 16 16 24 8 48 96
16 9 144 16 16 144 48 144 576
16 9 225 16 16 180 48 180 720
16 9 676 25 25 312 60 390 1560
Berdasarkan data diatas maka kita dapat mencari parameter-parameter regresinya yaitu nilai , 1, 2, 3, 4, serta kita akan mencari nilai koefisien nilai
korelasi bergandanya untuk membuktikan data-data diatas dapat diterima atau tidak.
Rumus regresi linier berganda untuk 4 variabel bebas dan 1 variabel terikat.
= 0+ 1 1+ 2 2+ 3 3+ 4 4
Berdasarkan rumus regresi berganda dan hasil perhitungan data-data diatas maka dapat dimasukkan kedalam rumus sebagai berikut :
50 0 + 205 1+ 132 2+ 931 3+ 190 4 = 202
205 0 + 869 1+ 548 2+ 3927 3+ 797 4 = 832
132 0 + 548 1+ 376 2+ 2485 3+ 671 4 = 533
931 0+ 3927 1+ 2485 + 19361 3+ 3631 4 = 3829
190 0 + 797 1+ 671 2+ 3631 3+ 792 4 = 842
Dengan mengunakan SPSS 16.0, kita akan mencari nilai koefisien intersep penduga variabel tak bebasnya. Sehingga kita dapat juga mendapatkan Persamaan Regresi Linear Bergandanya.
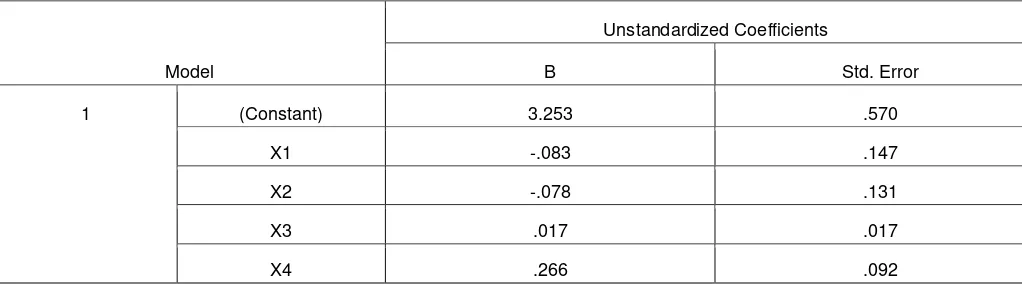
Tabel 3.4 Nilai Koefisien Intersep Penduga Variabel-Variabel Bebas
Model
Unstandardized Coefficients
B Std. Error
1 (Constant) 3.253 .570
X1 -.083 .147
X2 -.078 .131
X3 .017 .017
X4 .266 .092